NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
有很多改进版的word2vec,但是目前还是word2vec最流行,但是Glove也有很多在提及,笔者在自己实验的时候,发现Glove也还是有很多优点以及可以深入研究对比的地方的,所以对其进行了一定的学习。
部分学习内容来源于小象学院,由寒小阳老师授课《深度学习二期课程》
高级词向量三部曲:
1、NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
2、NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
3、NLP︱高级词向量表达(三)——WordRank(简述)
4、其他NLP词表示方法paper:从符号到分布式表示NLP中词各种表示方法综述
一、理论简述
1、word2vec
word2vec:与一般的共现计数不同,word2vec主要来预测单词周边的单词,在嵌入空间里相似度的维度可以用向量的减法来进行类别测试。
弊端:
- 1、对每个local context window单独训练,没有利用包含在global co-corrence矩阵中的统计信息
- 2、多义词处理乏力,因为使用了唯一词向量
2、GloVe
GloVe和word2vec的思路相似(论文链接)
但是充分考虑了词的共现情况,比率远比原始概率更能区分词的含义。


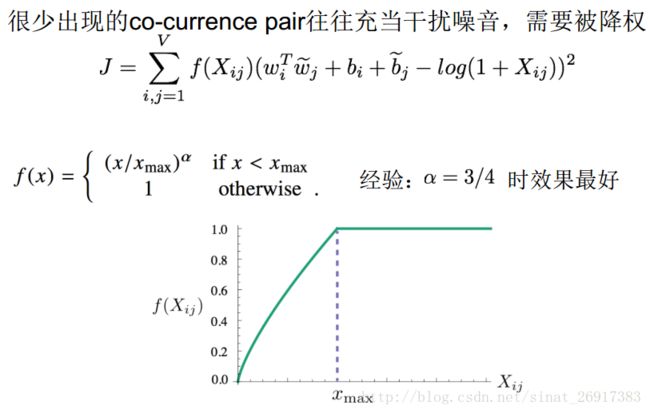
GloVe综合了LSA、CBOW的优点,训练更快、对于大规模语料算法的扩展性也很好、在小语料或者小向量上性能表现也很好。
.
.
二、测评
本节主要来自于52NLP的文章:斯坦福大学深度学习与自然语言处理第三讲:高级的词向量表示
.
.
1、词向量测评方法
一直以来,如何测评词向量还是一件比较头疼的事情。
主要方法分为两种:内部测评(词类比)与外部测评(命名实体识别(NER))。
词类比。通过评测模型在一些语义或语法类比问题上的余弦相似度距离的表现来评测词向量
当然,在测评时候,会去除一些来自于搜索的输入词、干扰词、常用停用词等,让测评结果更加显著
- 内部类比方式一:不同的城市可能存在相同的名字
类比数据来源:https://code.google.com/p/word2vec/source/browse/trunk/questions-words.txt

- 内部类比方式二:形容词比较级
以下语法和语义例子来源于:https://code.google.com/p/word2vec/source/browse/trunk/questions-words.txt 
- 内部类比三:时态
词向量类比:以下语法和语义例子来源于:https://code.google.com/p/word2vec/source/browse/trunk/questions-words.txt 
- 内部类比四:人名?
- 外部测评:命名实体识别(NER):找到人名,地名和机构名
.
.
2、测评结果
一些测评方式可参考:Paper2:[Improving Word Representations via Global Context
and Multiple Word
Prototypes]
- (1)内部测评
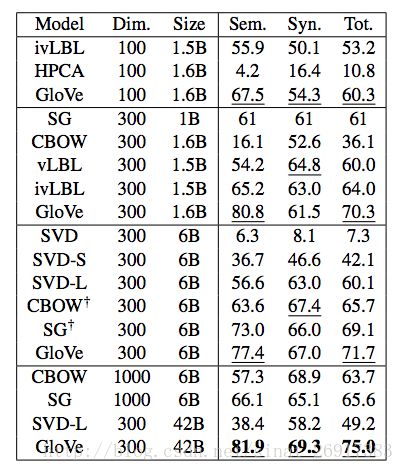
类比评测和超参数:
相关性评测结果: 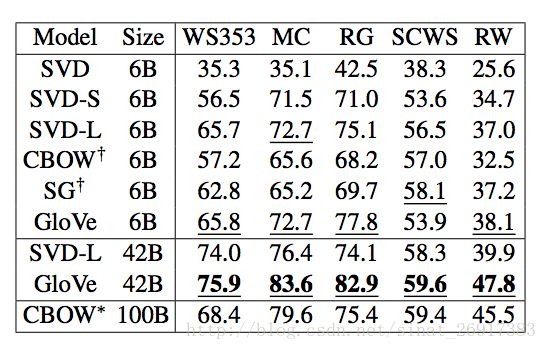
- (2)外部测评
命名实体识别(NER):找到人名,地名和机构名 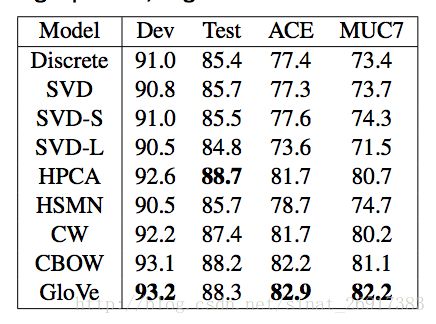
.
.
3、利用词向量解决歧义问题
也许你寄希望于一个词向量能捕获所有的语义信息(例如run即是动车也是名词),但是什么样的词向量都不能很好地进行凸显。
这篇论文有一些利用词向量的办法:Improving Word Representations Via Global Context And Multiple Word Prototypes(Huang et al. 2012)
解决思路:对词窗口进行聚类,并对每个单词词保留聚类标签,例如bank1, bank2等

.
.
.
三、Glove实现&R&python
1、Glove训练参数
本节主要来自于52NLP的文章:斯坦福大学深度学习与自然语言处理第三讲:高级的词向量表示
- 最佳的向量维度:300左右,之后变化比较轻微
- 对于GloVe向量来说最佳的窗口长度是8
- 训练迭代次数。对于GloVe来说确实有助于
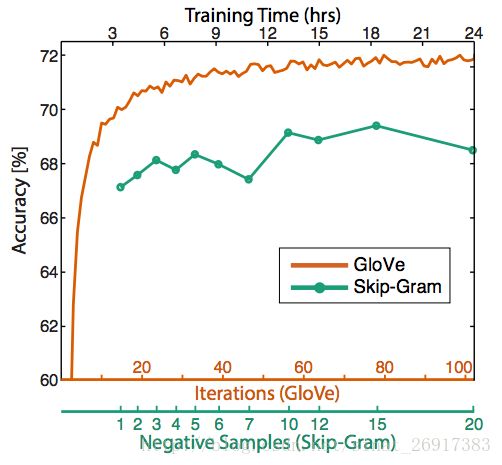
- 更多的数据有助于帮助提高训练精度
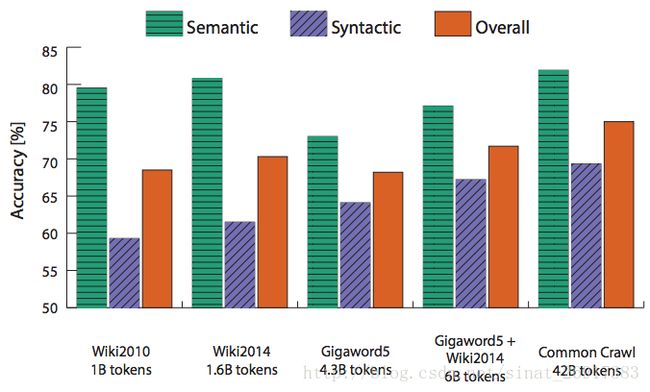
.
2、用R&python实现
python:python-glove(参考博客:glove入门实战)
R:text2vec(参考博客:重磅︱R+NLP:text2vec包——New 文本分析生态系统 No.1(一,简介))
.
.
四、相关应用
1、glove+LSTM:命名实体识别
用(Keras)实现,glove词向量来源: http://nlp.stanford.edu/data/glove.6B.zip
一开始输入的是7类golve词向量。The model is an LSTM over a convolutional layer which itself trains over a sequence of seven glove embedding vectors (three previous words, word for the current label, three following words).
最后是softmax层进行分类。The last layer is a softmax over all output classes.
CV categorical accuracy and weighted F1 is about 98.2%. To assess the test set performance we are ensembling the model outputs from each CV fold and average over the predictions.
来源于github:https://github.com/thomasjungblut/ner-sequencelearning
.
2、PAPER:词向量的擦除进行情感分类、错误稽查
Understanding Neural Networks Through Representation Erasure(arXiv: 1612.08220)
提出了一种通用的方法分析和解释了神经网络模型的决策——这种方法通过擦除输入表示的某些部分,比如将输入词向量的某些维、隐藏层的一些神经元或者输入的一些词。我们提出了几种方法来分析这种擦除的影响,比如比较擦除前后模型的评估结果的差异,以及使用强化学习来选择要删除的最小输入词集合,使用于分类的神经网络模型的分类结果发生改变。
在对多个 NLP 任务(包括语言特征分类、句子情感分析、文档级别的 sentiment aspect prediction)的综合分析中,我们发现我们提出的方法不仅能提供神经网络模型决策的清晰解释,而且可以用来进行错误分析。
**分析揭示了 Word2Vec 和 Glove 产生的词向量之间存在一些明显的差异,同时也表明训练语料中的词频对产生的词的表达有很大的影响;
在句子级别的情感分析上的实验表明情感词对情感分类结果影响显著,有意思的是还能找出来一些使模型误分类的词;**
在文档级别的 aspect prediction 实验则清晰地揭示出文档中哪部分文本和特定的 aspect 是强关联的。同时这些实验都表明,双向 LSTM 的表达能力比经典 LSTM 强,经典 RNN 则最弱。