Haar特征
哈尔特征使用检测窗口中指定位置的相邻矩形,计算每一个矩形的像素和并取其差值。然后用这些差值来对图像的子区域进行分类。
haar特征模板有以下几种:
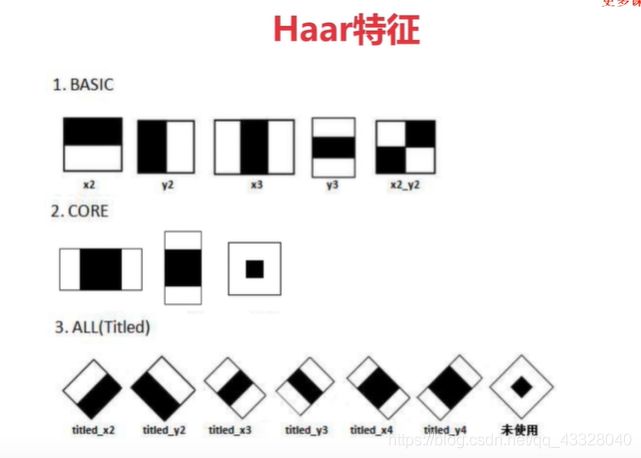
以第一个haar特征模板为例

计算方式
1.特征 = 白色 - 黑色(用白色区域的像素之和减去黑色区域的象征之和)
2.特征 = 整个区域 * 权重 + 黑色 * 权重
使用haar模板处理图像
从图像的起点开始,利用haar模板从左往右遍历,从上往下遍历,并设置步长,同时考虑图像大小和模板大小的信息
假如我们现在有一个 1080 * 720 大小的图像,10*10 的haar模板,并且步长为2,那么我我们所需要的的计算量为: (1080 / 2 * 720 / 2) * 100 * 模板数量 * 缩放 约等于50-100亿,计算量太大。
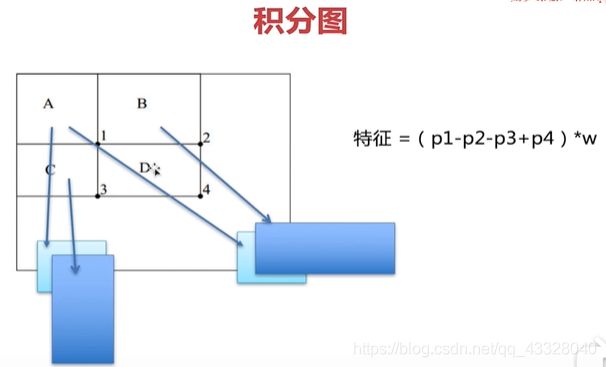
积分图
使用积分图可大量减少运算时间,实际上就是运用了前缀和的原理
Adaboost分类器
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
算法流程
该算法其实是一个简单的弱分类算法提升过程,这个过程通过不断的训练,可以提高对数据的分类能力。整个过程如下所示:
1. 先通过对N个训练样本的学习得到第一个弱分类器;
2. 将分错的样本和其他的新数据一起构成一个新的N个的训练样本,通过对这个样本的学习得到第二个弱分类器 ;
3. 将1和2都分错了的样本加上其他的新样本构成另一个新的N个的训练样本,通过对这个样本的学习得到第三个弱分类器;
4. 最终经过提升的强分类器。即某个数据被分为哪一类要由各分类器权值决定。
我们需要从官网下载俩个Adaboost分类器文件,分别是人脸和眼睛的分类器:
下载地址:https://github.com/opencv/opencv/tree/master/data/haarcascades
代码实现
实现人脸识别的基本步骤:
1.加载文件和图片
2.进行灰度处理
3.得到haar特征
4.检测人脸
5.进行标记
我们使用cv2.CascadeClassifier()来加载我们下载好的分类器。
然后我们使用detectMultiScale()方法来得到识别结果
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 1.加载文件和图片 2.进行灰度处理 3.得到haar特征 4.检测人脸 5.标记
face_xml = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
eye_xml = cv2.CascadeClassifier('haarcascade_eye.xml')
img = cv2.imread('img.png')
cv2.imshow('img', img)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 1.灰色图像 2.缩放系数 3.目标大小
faces = face_xml.detectMultiScale(gray, 1.3, 5)
print('face = ',len(faces))
print(faces)
#绘制人脸,为人脸画方框
for (x,y,w,h) in faces:
cv2.rectangle(img, (x,y), (x + w, y + h), (255,0,0), 2)
roi_face = gray[y:y+h,x:x+w]
roi_color = img[y:y+h,x:x+w]
eyes = eye_xml.detectMultiScale(roi_face)
print('eyes = ',len(eyes))
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color, (ex,ey),(ex + ew, ey + eh), (0,255,0), 2)
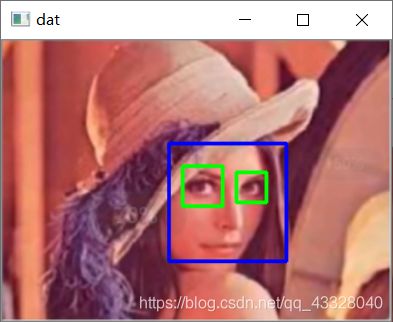
cv2.imshow('dat', img)
cv2.waitKey(0)
face = 1 [[133 82 94 94]] eyes = 2
到此这篇关于使用python-cv2实现Harr+Adaboost人脸识别的示例的文章就介绍到这了,更多相关python cv2 人脸识别内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!