matlab练习程序(KNN,K最邻近分类法)
K最邻近密度估计技术是一种分类方法,不是聚类方法。
不是最优方法,实践中比较流行。
通俗但不一定易懂的规则是:
1.计算待分类数据和不同类中每一个数据的距离(欧氏或马氏)。
2.选出最小的前K数据个距离,这里用到选择排序法。
3.对比这前K个距离,找出K个数据中包含最多的是那个类的数据,即为待分类数据所在的类。
不通俗但严谨的规则是:
给定一个位置特征向量x和一种距离测量方法,于是有:
1.在N个训练向量外,不考虑类的标签来确定k邻近。在两类的情况下,k选为奇数,一般不是类M的倍数。
2.在K个样本之外,确定属于wi,i=1,2,...M类的向量的个数ki,显然sum(ki)=k。
3.x属于样本最大值ki的那一类wi。
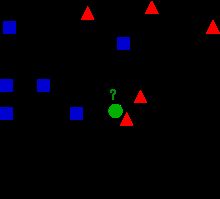
如下图,看那个绿色的值,是算三角类呢还是算矩类形呢,这要看是用几NN了,要是3NN就属于三角,要是5NN就属于矩形。
至于K到底取几,不同情况都要区别对待的。
下面是相关matlab代码:
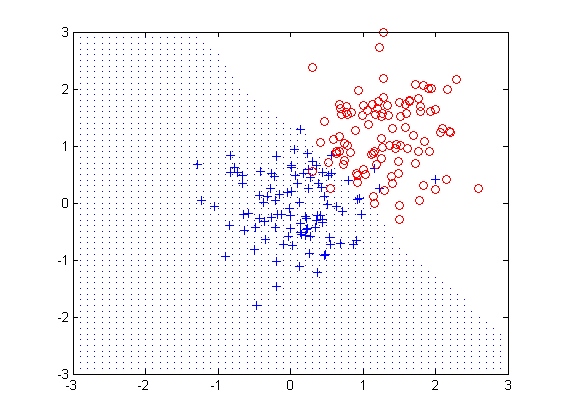
clear all; close all; clc; %%第一个类数据和标号 mu1=[0 0]; %均值 S1=[0.3 0;0 0.35]; %协方差 data1=mvnrnd(mu1,S1,100); %产生高斯分布数据 plot(data1(:,1),data1(:,2),'+'); label1=ones(100,1); hold on; %%第二个类数据和标号 mu2=[1.25 1.25]; S2=[0.3 0;0 0.35]; data2=mvnrnd(mu2,S2,100); plot(data2(:,1),data2(:,2),'ro'); label2=label1+1; data=[data1;data2]; label=[label1;label2]; K=11; %两个类,K取奇数才能够区分测试数据属于那个类 %测试数据,KNN算法看这个数属于哪个类 for ii=-3:0.1:3 for jj=-3:0.1:3 test_data=[ii jj]; %测试数据 label=[label1;label2]; %%下面开始KNN算法,显然这里是11NN。 %求测试数据和类中每个数据的距离,欧式距离(或马氏距离) distance=zeros(200,1); for i=1:200 distance(i)=sqrt((test_data(1)-data(i,1)).^2+(test_data(2)-data(i,2)).^2); end %选择排序法,只找出最小的前K个数据,对数据和标号都进行排序 for i=1:K ma=distance(i); for j=i+1:200 if distance(j)<ma ma=distance(j); label_ma=label(j); tmp=j; end end distance(tmp)=distance(i); %排数据 distance(i)=ma; label(tmp)=label(i); %排标号,主要使用标号 label(i)=label_ma; end cls1=0; %统计类1中距离测试数据最近的个数 for i=1:K if label(i)==1 cls1=cls1+1; end end cls2=K-cls1; %类2中距离测试数据最近的个数 if cls1>cls2 plot(ii,jj); %属于类1的数据画小黑点 end end end
代码中是两个高斯分布的类,变量取x=-3:3,y=-3:3中的数据,看看这些数据都是属于哪个类。
下面是运行效果图: