经历一番推理演算,每个字段逐字分析,接着https://blog.csdn.net/hu_lichao/article/details/110358607 前面的理论,本篇对前面的监控做了更进一步的设计产出,看完绝对不会浪费您的时间。
设计摘要:
任务执行、监控和报警从设计上是可以完全分开的,分开可以让任务执行尽可能只做任务执行的事情,监控可以根据多种监控规则来进行数据统计,数据分布,而报警则专注于如何根据监控的结果进行自定义灵活地报警。其中在设计上可以以监控为主体,任务执行和报警可以依据需求来定制,从而更好满足各方需求。 监控规则的设计,暂时从以下几个方面入手,数据分区的生成、数据分区的数据量、数据分区的数据量波动、表数据字段的码值分布波动。监控的主要职责是跑数,跑出报警需要的数据,而报警,可以根据监控的输出数据以及监控配置进行生成done文件或者undone 和 报警。
done目录和原表目录类似 表/版本/分区或日期/done/a.done or b.done or c.done (根据配置的根目录 + 表路径的后半部分来生成)
1.表数据监控
监控什么?要达到什么目的?
监控主要有两个目的,一个是报警,另外一个是拦截,拦截为了发生问题时不继续往下走,所以一般配置有拦截必有报警,有报警不一定有拦截,比如延时报警。
1.1 输入什么
一个调度平台的调度时间,以天为单位,最后体现在跑批日志的分区字段上,可以支持回溯,其他监控需要的配置信息都在表数据监控的主表里面,一些特别的配置信息,会用到附属表,比如分布子表。
1.2 计算模型
1.2.1分区有没有生成 show partitions | grep xx
1.2.2分区数量大于某个阈值,默认0:select count(*) from db_table where {db_table_date_column} = f($input_date) and version=20201205
1.2.3 分区数量波动:(分区数量的count - 前几天的count平均值) / 前几天的count平均值
1.2.4 数据码值分布波动监控
如何衡量数据分布波动
假设某指标码值和数据分布如下:
| 2020-12-05 | 2020-12-06 | 2020-12-07 |
|---|---|---|
| a 10% | a 9% | a 1% |
| b 50% | b 51% | b 90% |
| c 40% | c 40% | c 9% |
可以看到在12.07日,波动较大,需要做预警,问如何衡量这个波动,以及设置预警
把a,b,c看成一个向量,求比如最近一周(不包括当天)的向量平均值
$$ a1,b1,c1 $$
,然后计算当前向量
$$ a0,b0,b1 - a1,b1,c1 / (a1,b1,c1) = a3,b3,c3 $$
数据分布波动计算模型
key 当天向量
$$ a=(x,y,z...) $$
$$ b=(x1,y1,z1....) $$
那么波动向量
$$ c=(a-b)/a $$
,最终结果
$$ c=(x2,y2,z2...) $$
2.报警设计
报警任务的每次启动可以依赖当天分区数据监控的日志跑批分区,即至少有跑批日志,才开始进行报警任务。报警的输入是监控主表和监控跑批表,输出done,undone && 报警,于报警日志中。
3. 整体设计
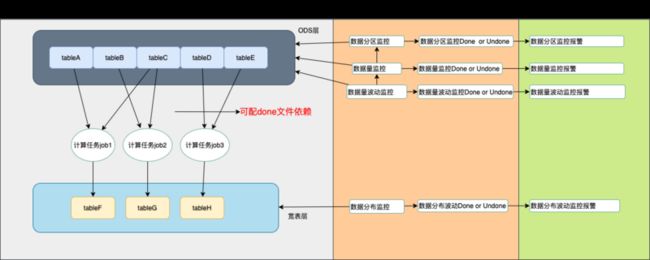
使用平台例行任务来调度监控任务,使用mysql开发环境来读配置,使用gp来存储结果数据,使用平台同步功能将同结构的hive结果表同步到gp来做报表展示,整个过程支持回溯。
表数据监控配置表:
-- 总表
create table table_monitor_conf (
db_table string,
table_charge_people string comment '表负责人',
done_path string comment 'done 文件输出位置前缀',
where_condition string comment 'where 子句内容 eg:version=20201201 and dt=#YYYYMMdd#',
if_done string comment '总开关:是否生成done文件'
if_check_partition string comment '规则1:是否监控产出分区',
if_check_partition_count string comment '规则2:是否监控产出分区数据量',
if_check_partition_count_fluctuates string comment '规则3:是否监控产出分区数据量波动',
if_check_distribute string comment '规则4:是否监控产出表数据分布波动'
)
-- 分布子表if_check_distribute 为1时候使用
create table table_monitor_distribute_conf (
db_table string comment '表名',
with_code_value_keys string comment '有码值的keys:k1,k2,k3',
no_code_value_keys string comment '无码值的keys:k1,k2,k3'
)其中当table_monitor_conf 的 db_table = 'default.default' 时候表示是所有配置记录的默认值。
表数据量监控跑批记录:
create table table_monitor_records (
run_db_table string comment '跑批表,来源table_monitor_conf 的db_table',
check_date_time string comment '任务实际跑批时间-程序生成',
run_check_partition string comment '规则1产出:根据where_condition 是否产出分区'
run_check_partition_count bigint comment '规则2产出:根据where_condition 跑出来的表数量',
run_check_partition_count_fluctuates string comment '规则3产出:表数据量相对一周前平均值的数据波动',
run_check_distribute_json comment '规则4产出:数据分布的大json',
run_check_distribute_fluctuates comment '规则4产出:数据分布的大json相对一周平均值的波动大json'
) partition by (dt string comment '数据跑批分区,平台传入')
comment '监控跑批记录表'报警配置表
create table table_monitor_notify_conf(
db_table string comment '库表',
notify_enable string comment '是否开启此报警',
normal_produce_datetime string comment '表数据正常产生时间',
check_count_threshold bigint comment '监控产出分区数据量的阈值',
check_count_fluctuates_threshold double comment '监控产出分区数据量波动的阈值' ,
check_distribute__json_threshold double comment '表数据分布阈值'
)报警日志表
create table table_monitor_notify_records(
db_table string comment '哪个表有问题',
view_url string comment '页面展示地址',
table_charge_people string comment '表负责人',
trouble_description string comment '有什么问题',
check_date_time string comment '报警时间-程序生成',
) patition by (dt string comment '数据跑批分区,平台传入')写出数据,done 文件 ,undone文件 每个表,每个分区只有一个
数据分布,在分布波动的第一次跑数据时候,就会写一份
总共有几个任务:监控任务,报警任务各1个,每天1点->晚上8点,10分钟一次
其他:
hi_email_message_phone string comment '报警方式,保留字段'
zhiban_people string comment '值班负责人,保留字段',
TODO:
- [ ] 增加值班人,报警方式升级、
- [ ] 根据依赖来报警
- [ ] 通过群内机器人,来操作报警日志表,达到报警暂停一段时间的作用
吴邪,小三爷,混迹于后台,大数据,人工智能领域的小菜鸟。
更多请关注