CentOS 7上搭建Spark3.0.1+ Hadoop3.2.1分布式集群
CentOS 7上搭建Spark3.0.1+ Hadoop3.2.1分布式集群
-
-
- VMWare 安装CentOS 7
- 使用Xshell连接虚拟机
- 集群设置
- 安装JDK 1.8
- SSH 免密登陆
- 安装hadoop 3.2
- 安装Spark 3.0.1
- 总结
-
VMWare 安装CentOS 7
- 推荐使用VMware Workstation Pro 16,下载安装即可。
- 下载最新的CentOS 7 Minimal-2009.iso,在虚拟机安装。推荐1G运存和20G存储。
- 在CentOS 7的安装过程中,需要设置root用户的密码,还可以根据需要创建单独的用户。
- 安装完成后,使用命令行进行更新,然后安装net-tools.x86_64,以方便查看ip地址。
ip地址为:192.168.92.137# 如果在安装时没有连接网络 vi /etc/sysconfig/network-scripts/ifcfg-ens33 # 将ONBOOT=no修改为yes # 重启网络服务 service network restart # 更新系统 yum update # 安装net-tools yum install net-tools.x86_64 # 查看ip地址 ifconfig
使用Xshell连接虚拟机
- 这里可以下载Xshell家庭/学校免费版,但是您需要申请才行。
- 文件->新建会话,信息配置可以参考如下,连接即可。
表格中的信息,具体需要更换成您自己的。名称 主机 端口 用户名 CentOS 7 192.168.92.137 22 root
集群设置
- 节点设置。
为什么上面的ip地址是连续的呢? 这其实跟DHCP有关,下一步我们会使用克隆主机的方式来创建多个slave机器,大家可以去验证,但是可能出现与表中不一直的ip,我们根据需要修改即可。hostname(主机名) ip地址 namenode(主节点) datanode(从节点) master 192.168.92.137 True False slave1 192.168.92.138 False True slave2 192.168.92.139 False True slave3 192.168.92.140 False True
安装JDK 1.8
- 在进行下一步的克隆前,我们先安装jdk-8u271-linux-x64.tar.gz,目前1.8版本的下载需要注册Oracle的账号才能够下载,有点麻烦呢。
- 使用SCP命令上传到master主机上,scp命令使用参考如下。
参数依次是本地文件,远程用户名和远程ip,以及保存的文件夹。在PowerShell中使用如下。scp local_file remote_username@remote_ip:remote_folderPS E:\XunLeiDownload> scp .\jdk-8u271-linux-x64.tar.gz [email protected]:/usr/local >>> # 这是输出 The authenticity of host '192.168.92.137 (192.168.92.137)' can't be established. ECDSA key fingerprint is SHA256:DjkK5V/chVHAD1SsaosqdxfH4wClmH8S6M8kxw7X/RQ. Are you sure you want to continue connecting (yes/no)? Warning: Permanently added '192.168.92.137' (ECDSA) to the list of known hosts. [email protected]'s password: jdk-8u271-linux-x64.tar.gz 100% 137MB 91.5MB/s 00:01 # 上传成功 - 解压jdk1.8到/usr/local路径下,
安装vim,编辑/etc/profile,tar -xvf jdk-8u271-linux-x64.tar.gz mv jdk1.8.0_271 jdk1.8 # 重命名文件夹
添加两行内容如下,yum install vim # 安装vim vim /etc/profile
执行export JAVA_HOME=/usr/local/jdk1.8 export PATH=$PATH:$JAVA_HOME/binsource /etc/profile使环境生效,$JAVA_HOME查看是否配置成功,或者,
表示配置成功。java -version >>> java version "1.8.0_271" Java(TM) SE Runtime Environment (build 1.8.0_271-b09) Java HotSpot(TM) 64-Bit Server VM (build 25.271-b09, mixed mode)
SSH 免密登陆
- 在配置ssh免密登陆之前,将master克隆3份slaves出来,然后验证其ip是否和上面所述一致,并使用Xshell连接,这样我们可以得到额外的三台机器,且都安装好Java的。
注意:在使用克隆时,不太推荐使用链接克隆。
使用ifconfig查看ip地址后,如下,下面将按照这个ip地址进行配置。hostname(主机名) ip地址 namenode(主节点) datanode(从节点) master 192.168.92.137 True False slave1 192.168.92.134 False True slave2 192.168.92.135 False True slave3 192.168.92.146 False True - 在master节点上更改hosts文件如下。
vim /etc/hosts编辑,在后面添加以下行。
其他的slave节点也应该如此。192.168.92.137 master 192.168.92.134 slave1 192.168.92.135 slave2 192.168.92.136 slave3 - 使用以下命令,分别更改4台机器的主机名,以master节点为例。
其他节点是slave1-3,更改完成后在Xshell中重启会话就可以发现主机名已经改变啦。hostnamectl set-hostname master - 要使master和3台slave免密登陆,需先在本地机器使用
ssh-keygen一个公私钥对。
其他三台机器也是这样生成。ssh-keygen -t rsa # 生成公私钥对 >>> Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Created directory '/root/.ssh'. Enter passphrase (empty for no passphrase): # 不用输入 Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. # 存放位置 Your public key has been saved in /root/.ssh/id_rsa.pub. # 公钥 The key fingerprint is: SHA256:vGAdZV8QBkGYgbyAj4OkQ9GrYEEiilX5QLmL97CcFeg root@master The key's randomart image is: +---[RSA 2048]----+ |+o++o+ ..=*o+o. | |==..= o oo o . | |*..o.* .. . | |=.o.+ +o . | |o..+ .o.S | | .. E... . | | o * . | | + . | | | +----[SHA256]-----+ - 将slaves生成的所有
id_rsa.pub公钥文件通过scp上传到master的/root/.ssh/目录下。
在master节点上,将所有的公钥文件写入scp id_rsa.pub root@master:/root/.ssh/id_rsa.pub.1 # slave2 对应于.2 scp id_rsa.pub root@master:/root/.ssh/id_rsa.pub.2 # 依此类推 # master上也要这样处理,否则就不能从slaves登陆到master,如下 scp id_rsa.pub root@master:/root/.ssh/authorized_keys文件中。
分发cat id_rsa.pub* >> authorized_keys rm -rf id_rsa.pub.* # 删除authorized_keys文件给slaves机器。
分发scp authorized_keys root@slave1:/root/.ssh/ scp authorized_keys root@slave2:/root/.ssh/ scp authorized_keys root@slave3:/root/.ssh/known_hosts文件给slaves机器。
这样就可以实现免密登陆啦,查看scp known_hosts root@slave3:/root/.ssh/ # 其他同上known_hosts文件如下。
符合这样的格式才可以呢。master,192.168.92.137 ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNoYTItbmlzdHAyNTYAAAAIbmlzdHAyNTYAAABBBG4pcNSq4jQmGY3JRlYoU/IssJ8gfjTZhCcqBmLlviFismkti27xJHbd0s1rcaO/MX4ORK6eUdGr2ALE/r36otk= slave1,192.168.92.134 ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNoYTItbmlzdHAyNTYAAAAIbmlzdHAyNTYAAABBBG4pcNSq4jQmGY3JRlYoU/IssJ8gfjTZhCcqBmLlviFismkti27xJHbd0s1rcaO/MX4ORK6eUdGr2ALE/r36otk= slave2,192.168.92.135 ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNoYTItbmlzdHAyNTYAAAAIbmlzdHAyNTYAAABBBG4pcNSq4jQmGY3JRlYoU/IssJ8gfjTZhCcqBmLlviFismkti27xJHbd0s1rcaO/MX4ORK6eUdGr2ALE/r36otk= slave3,192.168.92.136 ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNoYTItbmlzdHAyNTYAAAAIbmlzdHAyNTYAAABBBG4pcNSq4jQmGY3JRlYoU/IssJ8gfjTZhCcqBmLlviFismkti27xJHbd0s1rcaO/MX4ORK6eUdGr2ALE/r36otk=
安装hadoop 3.2
- 下载hadoop-3.2.1.tar.gz,通过scp上传之master节点,然后解压。
PS E:\XunLeiDownload> scp .\jdk-8u271-linux-x64.tar.gz [email protected]:/usr/local tar -xvf hadoop-3.2.1.tar.gz # 解压在/usr/local/hadoop-3.2.1 - 添加环境变量,
vim /etc/profile,在最后添加以下两行。
执行以下命令export HADOOP_HOME=/usr/local/hadoop-3.2.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME:/sbinsource /etc/profile,使配置文件生效,并查看是否成功。hadoop version >>> Hadoop 3.2.1 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842 Compiled by rohithsharmaks on 2019-09-10T15:56Z Compiled with protoc 2.5.0 From source with checksum 776eaf9eee9c0ffc370bcbc1888737 This command was run using /usr/local/hadoop-3.2.1/share/hadoop/common/hadoop-common-3.2.1.jar - 在hadoop安装目录下建立以下目录:
mkdir tmp # 即hadoop-3.2.1/tmp, 存储临时文件 mkdir -p hdfs/name # namenode的数据目录 mkdir -p hdfs/data # datanode的数据目录 - 配置相关配置文件,在
etc/hadoop目录下。
在core-site.xml文件中指定默认文件系统和临时文件目录。文件 介绍 core-site.xml 核心配置文件 dfs-site.xml hdfs存储相关配置 apred-site.xml MapReduce相关的配置 arn-site.xml yarn相关的一些配置 workers 用来指定从节点,文件中默认是localhost hadoop-env.sh 配置hadoop相关变量
在hdfs-site.xml中配置复制份数,datanode和namenode的目录。fs.defaultFS hdfs://master:9000 hadoop.tmp.dir /usr/local/hadoop-3.2.1/tmp
在mapred-site.xml中指定主节点和添加classpath。dfs.namenode.secondary.http-address master:50090 dfs.replication 3 dfs.namenode.name.dir file:/usr/local/hadoop-3.2.1/hdfs/name true dfs.datanode.data.dir file:/usr/local/hadoop-3.2.1/hdfs/data true dfs.webhdfs.enabled true dfs.permissions.enabled false
yarn-site.xml中都需要指向主节点。mapreduce.framework.name yarn mapreduce.jobhistory.address master:10020 mapreduce.jobhistory.webapp.address master:19888 mapreduce.application.classpath /usr/local/hadoop-3.2.1/etc/hadoop, /usr/local/hadoop-3.2.1/share/hadoop/common/*, /usr/local/hadoop-3.2.1/share/hadoop/common/lib/*, /usr/local/hadoop-3.2.1/share/hadoop/hdfs/*, /usr/local/hadoop-3.2.1/share/hadoop/hdfs/lib/*, /usr/local/hadoop-3.2.1/share/hadoop/mapreduce/*, /usr/local/hadoop-3.2.1/share/hadoop/mapreduce/lib/*, /usr/local/hadoop-3.2.1/share/hadoop/yarn/*, /usr/local/hadoop-3.2.1/share/hadoop/yarn/lib/*
workers中指定datanode节点。yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.address master:8032 yarn.resourcemanager.scheduler.address master:8030 yarn.log-aggregation-enable true yarn.resourcemanager.resource-tracker.address master:8031 yarn.resourcemanager.admin.address master:8033 yarn.resourcemanager.webapp.address master:8088
在hadoop-env.sh中指定用户。localhost slave1 slave2 slave3export HADOOP_HOME=/usr/local/jdk1.8 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root - 将配置好的hadoop分发到其他机器,在其他slaves机器上也要执行步骤2添加环境变量哦。
scp -r hadoop-3.2.1 slave1:/usr/local/ scp -r hadoop-3.2.1 slave2:/usr/local/ scp -r hadoop-3.2.1 slave3:/usr/local/ - 格式化namenode,在master执行。
在输出中看到hdfs name -format >> 2020-11-25 23:58:07,593 INFO common.Storage: Storage directory /usr/local/hadoop-3.2.1/hdfs/name has been successfully formatted. 2020-11-25 23:58:07,640 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop-3.2.1/hdfs/name/current/fsimage.ckpt_0000000000000000000 using no compression 2020-11-25 23:58:07,792 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop-3.2.1/hdfs/name/current/fsimage.ckpt_0000000000000000000 of size 396 bytes saved in 0 seconds . 2020-11-25 23:58:07,807 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-11-25 23:58:07,825 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-11-25 23:58:07,826 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at master/192.168.92.137 ************************************************************/Storage: Storage directory /usr/local/hadoop-3.2.1/hdfs/name has been successfully formatted.,说明格式话成功了,在下一次格式化前,需要删除hdfs和tmp目录下的所有文件,否则会运行不起来。 - 启动hadoop,在
sbin下。
使用./start-all.sh >>> ./start-all.sh Starting namenodes on [master] 上一次登录:四 11月 26 00:08:30 CST 2020pts/5 上 master: namenode is running as process 14328. Stop it first. Starting datanodes 上一次登录:四 11月 26 00:14:03 CST 2020pts/5 上 slave1: WARNING: /usr/local/hadoop-3.2.1/logs does not exist. Creating. slave3: WARNING: /usr/local/hadoop-3.2.1/logs does not exist. Creating. slave2: WARNING: /usr/local/hadoop-3.2.1/logs does not exist. Creating. localhost: datanode is running as process 14468. Stop it first. Starting secondary namenodes [master] 上一次登录:四 11月 26 00:14:04 CST 2020pts/5 上 Starting resourcemanager 上一次登录:四 11月 26 00:14:09 CST 2020pts/5 上 resourcemanager is running as process 13272. Stop it first. Starting nodemanagers 上一次登录:四 11月 26 00:14:19 CST 2020pts/5 上jps查看。
这上面显示的master节点的信息slaves节点则少了一些,可以自行查看哦。jps >>> 15586 Jps 14468 DataNode 14087 GetConf 13272 ResourceManager 14328 NameNode 15096 SecondaryNameNode 15449 NodeManager - 验证,访问namenod主节点端口9870。
webui地址在:service firewalld stop # 需要关闭防火墙哦http://192.168.92.137:9870/。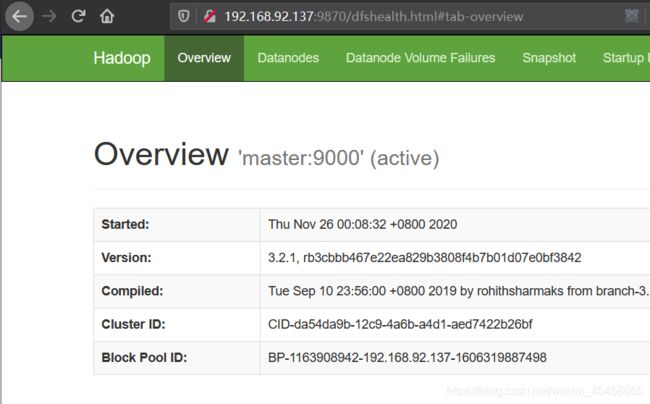
- 在下面的摘要如下,可以看到确实有4个节点。

- 查看yarn管理界面,在
http://192.168.92.137:8088/cluster。
- 测试,向hdfs文件系统中写入一个文件。
PS E:\XunLeiDownload> scp .\TwitterSecurity.csv [email protected]:/root # 这里上传一个40多兆的csv文件 hdfs dfs -put TwitterSecurity.csv / 可以看到确实在是三个节点上复制保存。
可以看到确实在是三个节点上复制保存。
安装Spark 3.0.1
-
下载预编译hadoop3.2的版本,spark-3.0.1-bin-hadoop3.2.tgz。
-
使用scp上传到master节点上,然后解压,并加入相应的环境变量。
PS E:\XunLeiDownload> scp .\spark-3.0.1-bin-hadoop3.2.tgz [email protected]:/usr/local # 上传 tar -xvf spark-3.0.1-bin-hadoop3.2.tgz # 解压 mv spark-3.0.1-bin-hadoop3.2 spark-3.0.1vim /etc/profile添加以下两行。export SPARK_HOME=/usr/local/spark-3.0.1 export PATH=$PATH:$SPARK_HOME:/bin:$SPARK_HOME:/sbinsource /etc/profile使配置文件生效。 -
进入conf文件夹,复制配置文件模板。
cp spark-env.sh.template spark-env.sh
在spark-env.sh后面添加以下行。export JAVA_HOME=/usr/local/jdk1.8 export HADOOP_CONF_DIR=/usr/local/hadoop-3.2.1/etc/hadoop export SPARK_MASTER_HOST=master export SPARK_LOCAL_DIRS=/usr/local/spark-3.0.1cp slaves.template slaves编辑如下。localhost slave1 slave2 slave3 -
将spark分发给slaves机器,同时不要忘记环境变量。
scp -r spark-3.0.1 slave1:/usr/local/ scp -r spark-3.0.1 slave2:/usr/local/ scp -r spark-3.0.1 slave3:/usr/local/ -
运行,进入
sbin目录。./start-all.sh >>> org.apache.spark.deploy.master.Master running as process 16859. Stop it first. slave1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-3.0.1/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.out slave3: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-3.0.1/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave3.out localhost: org.apache.spark.deploy.worker.Worker running as process 17975. Stop it first. slave2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-3.0.1/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave2.out -
查看,地址在:
http://192.168.92.137:8080/。