ADSP重点习题第四章-第五章(原版书第五章-第六章)
ADSP重点习题
- 第四章
-
- 知识点:
-
-
- 平稳随机信号的自相关估计
- 平稳信号的功率谱估计
-
- 周期图法
- Blackman-Tukey法
- Welch-Bartlett法
-
- 第五章
-
- 习题5.4
- 习题5.24
- 习题5.25
- 习题5.27
- 知识点
-
-
- 最佳信号估计
- 线性均方误差估计
- 最佳有限脉冲响应滤波器
- 线性预测
-
第四章
知识点:
平稳随机信号的自相关估计
对于一个平稳过程 x ( n ) x(n) x(n),最广泛使用的 r x ( l ) r_{x}(l) rx(l)的估计量是采样自相关序列,如下式:
r ^ x ( l ) = { 1 N ∑ n = 0 N − l − 1 x ( n + l ) x ∗ ( n ) 0 ≤ l ≤ N − 1 r x ∗ ^ ( − l ) − ( N − 1 ) ≤ l ≤ 0 0 其 他 \hat{r}_x(l)=\left\{ \begin{array}{lr} \frac{1}{N}\sum_{n=0}^{N-l-1}x(n+l)x^{*}(n) & 0 \le l \le N-1 \\ \hat{r_x^{*}}(-l) & -(N-1) \le l \le 0\\ 0 & 其他 \end{array} \right. r^x(l)=⎩⎨⎧N1∑n=0N−l−1x(n+l)x∗(n)rx∗^(−l)00≤l≤N−1−(N−1)≤l≤0其他或等价于:
r ^ x ( l ) = { 1 N ∑ n = l N − 1 x ( n ) x ∗ ( n − l ) 0 ≤ l ≤ N − 1 r x ∗ ^ ( − l ) − ( N − 1 ) ≤ l ≤ 0 0 其 他 \hat{r}_x(l)=\left\{ \begin{array}{lr} \frac{1}{N}\sum_{n=l}^{N-1}x(n)x^{*}(n-l) & 0 \le l \le N-1 \\ \hat{r_x^{*}}(-l) & -(N-1) \le l \le 0\\ 0 & 其他 \end{array} \right. r^x(l)=⎩⎨⎧N1∑n=lN−1x(n)x∗(n−l)rx∗^(−l)00≤l≤N−1−(N−1)≤l≤0其他需要注意的是,除了观察数据 x ( n ) 0 N − 1 {x(n)}^{N-1}_0 x(n)0N−1外没有更进一步的信息,因此当 ∣ l ∣ ≥ N |l| \ge N ∣l∣≥N时, r x ( l ) r_x(l) rx(l)的合理估计是不可能得到的。
r ^ x ( l ) \hat{r}_x(l) r^x(l)的均值:
E { r ^ x ( l ) } = 1 N r x ( l ) r w ( l ) E\{ \hat{r}_x(l) \}=\frac{1}{N}r_x(l)r_w(l) E{ r^x(l)}=N1rx(l)rw(l)其中: r w ( l ) = w ( l ) ∗ w ( − l ) = ∑ n = − ∞ ∞ w ( n ) w ( n + l ) r_w(l)=w(l)*w(-l)=\sum^{\infty}_{n=-\infty}w(n)w(n+l) rw(l)=w(l)∗w(−l)=∑n=−∞∞w(n)w(n+l),是一个窗口序列的自相关。对于矩形窗:
r w ( l ) = w B ( n ) = { N − ∣ l ∣ ∣ l ∣ ≤ N − 1 0 其 他 {r}_w(l)=w_B(n)=\left\{ \begin{array}{lr} N-|l| & |l| \le N-1 \\ 0 & 其他 \end{array} \right. rw(l)=wB(n)={ N−∣l∣0∣l∣≤N−1其他
因此有:
E { r ^ x ( l ) } = 1 N r x ( l ) w B ( n ) = r x ( l ) ( 1 − ∣ l ∣ N ) w H ( n ) E\{ \hat{r}_x(l) \}=\frac{1}{N}r_x(l)w_B(n)=r_x(l)(1-\frac{|l|}{N})w_H(n) E{ r^x(l)}=N1rx(l)wB(n)=rx(l)(1−N∣l∣)wH(n)从式中可以看出 r ^ x ( l ) \hat{r}_x(l) r^x(l)不等于实际的 r x ( l ) r_x(l) rx(l),因此上面的自相关估计为有偏估计,但是当 N → ∞ N \to \infty N→∞时, E { r ^ x ( l ) } → r x ( l ) E\{ \hat{r}_x(l) \} \to r_x(l) E{ r^x(l)}→rx(l),所以 r ^ x ( l ) \hat{r}_x(l) r^x(l)是一个渐近无偏估计量
r ^ x ( l ) \hat{r}_x(l) r^x(l)的方差:
一个对 r ^ x ( l ) \hat{r}_x(l) r^x(l)的协方差的近似式为:
c o v r ^ x ( l 1 ) , r ^ x ( l 2 ) ≃ 1 N ∑ l = − ∞ ∞ [ r x ( l ) r x ( l + l 2 − l 1 ) + r x ( l + l 2 ) r x ( l − l 1 ) ] cov{\hat{r}_x(l_1),\hat{r}_x(l_2)}\simeq \frac{1}{N}\sum_{l=-\infty}^{\infty}[r_x(l)r_x(l+l_2-l_1)+r_x(l+l_2)r_x(l-l_1)] covr^x(l1),r^x(l2)≃N1l=−∞∑∞[rx(l)rx(l+l2−l1)+rx(l+l2)rx(l−l1)]易得:当 N → ∞ N \to \infty N→∞时, r ^ x ( l ) \hat{r}_x(l) r^x(l)方差趋于0,当 ∣ l ∣ |l| ∣l∣相对于 N N N足够小, r ^ x ( l ) \hat{r}_x(l) r^x(l)是 r x ( l ) r_x(l) rx(l)的一个很好的估计,但是当 ∣ l ∣ |l| ∣l∣接近于 N N N时,估计值变差,方差增加。
r ^ x ( l ) \hat{r}_x(l) r^x(l)的非负定性
对于自相关序列的另一种估计量可由下式给出:
r ^ x ( l ) = { 1 N − 1 ∑ n = 0 N − l − 1 x ( n + l ) x ∗ ( n ) 0 ≤ l ≤ L < N r x ∗ ^ ( − l ) − N < − L ≤ l < 0 0 其 他 \hat{r}_x(l)=\left\{ \begin{array}{lr} \frac{1}{N-1}\sum_{n=0}^{N-l-1}x(n+l)x^{*}(n) & 0 \le l \le L < N \\ \hat{r_x^{*}}(-l) & -N < -L \le l <0\\ 0 & 其他 \end{array} \right. r^x(l)=⎩⎨⎧N−11∑n=0N−l−1x(n+l)x∗(n)rx∗^(−l)00≤l≤L<N−N<−L≤l<0其他尽管这个估计是无偏的,但是由于它是负定的,因此不用于谱估计。
平稳信号的功率谱估计
周期图法
数据段 { x ( n ) } 0 N − 1 \{x(n)\}_{0}^{N-1} { x(n)}0N−1的周期图定义为:
R ^ x ( e j w ) = 1 N ∣ ∑ n = 0 N − 1 v ( n ) e − j w n ∣ 2 = 1 N ∣ V ( e j w ) ∣ 2 \hat{R}_{x}(e^{jw})=\frac{1}{N}|\sum_{n=0}^{N-1}v(n)e^{-jwn}|^2=\frac{1}{N}|V(e^{jw})|^2 R^x(ejw)=N1∣n=0∑N−1v(n)e−jwn∣2=N1∣V(ejw)∣2其中: v ( n ) = x ( n ) w ( n ) , 0 ≤ n ≤ N − 1 v(n)=x(n)w(n),0\le n \le N-1 v(n)=x(n)w(n),0≤n≤N−1, V ( e j w ) V(e^{jw}) V(ejw)为窗口序列 v ( n ) v(n) v(n)的DTFT。
R ^ x ( e j w ) \hat{R}_{x}(e^{jw}) R^x(ejw)的逆傅里叶变换给出了估计的自相关序列 r v ( l ) ^ \hat{r_v(l)} rv(l)^,即:
r v ^ ( l ) = 1 2 π ∫ − π p i R ^ x ( e j w ) e j w l d w \hat{r_v}(l)=\frac{1}{2\pi}\int_{-\pi}^{pi}\hat{R}_{x}(e^{jw})e^{jwl}dw rv^(l)=2π1∫−πpiR^x(ejw)ejwldw
周期图法估计的 R ^ x ( e j w ) \hat{R}_{x}(e^{jw}) R^x(ejw)的平均值:
E { R ^ x ( e j w ) } = ∑ l = − ( N − 1 ) N − 1 E { r ^ x ( l ) } e − j w l = 1 N ∑ l = − ( N − 1 ) N − 1 r x ( l ) r w ( l ) e − j w l E\{ \hat{R}_{x}(e^{jw})\}=\sum_{l=-(N-1)}^{N-1}E\{\hat{r}_x(l)\}e^{-jwl}=\frac{1}{N}\sum_{l=-(N-1)}^{N-1}r_x(l)r_w(l)e^{-jwl} E{ R^x(ejw)}=l=−(N−1)∑N−1E{ r^x(l)}e−jwl=N1l=−(N−1)∑N−1rx(l)rw(l)e−jwl
其中, r w ( l ) = w ( l ) ∗ w ( − l ) r_w(l)=w(l)*w(-l) rw(l)=w(l)∗w(−l),所以有:
E { R ^ x ( e j w ) } = ∑ l = − ( N − 1 ) N − 1 ( 1 − ∣ l ∣ N ) r x ( l ) e − j w l E\{\hat{R}_{x}(e^{jw})\}=\sum_{l=-(N-1)}^{N-1}(1-\frac{|l|}{N})r_x(l)e^{-jwl} E{ R^x(ejw)}=l=−(N−1)∑N−1(1−N∣l∣)rx(l)e−jwl当 N → ∞ N \to \infty N→∞时, R ^ x ( e j w ) \hat{R}_{x}(e^{jw}) R^x(ejw)趋近于真实的功率谱 R x ( e j w ) R_{x}(e^{jw}) Rx(ejw),周期图为渐近无偏估计。
周期图法估计的 R ^ x ( e j w ) \hat{R}_{x}(e^{jw}) R^x(ejw)的方差:
对于大的N值,方差近似等于:
v a r { R ^ x ( e j w ) } ≃ { R x 2 ( e j w ) 0 < w < π 2 R x 2 ( e j w ) w = 0 , π var\{\hat{R}_{x}(e^{jw})\} \simeq \left\{ \begin{array}{lr} R^2_{x}(e^{jw}) & 0
Blackman-Tukey法
Blackman-Tukey法是一个根据已有的估计好的功率谱 R ^ x ( e j w ) \hat{R}_{x}(e^{jw}) R^x(ejw)进行平滑的过程:
R ^ x ( P S ) ( e j w ) = 1 2 π ∫ − π π R ^ x ( e j ( w − θ ) ) W a ( e j θ ) d θ = R ^ x ( e j w ) ⊗ W a ( e j w ) \hat{R}^{(PS)}_{x}(e^{jw})=\frac{1}{2\pi}\int_{-\pi}^{\pi}\hat{R}_{x}(e^{j(w-\theta)})W_a(e^{j\theta})d\theta=\hat{R}_{x}(e^{jw})\otimes W_a(e^{jw}) R^x(PS)(ejw)=2π1∫−ππR^x(ej(w−θ))Wa(ejθ)dθ=R^x(ejw)⊗Wa(ejw)式中, W a ( e j w ) W_a(e^{jw}) Wa(ejw)是 w w w函数,周期为 2 π 2\pi 2π,由下式给出:
W a ( e j w ) = { 1 △ w ∣ w ∣ < △ w 2 0 △ w 2 ≤ w ≤ π W_a(e^{jw})=\left\{ \begin{array}{lr} \frac{1}{\bigtriangleup w} & |w|<\frac{\bigtriangleup w}{2} \\ 0 & \frac{\bigtriangleup w}{2} \le w \le \pi \end{array} \right. Wa(ejw)={ △w10∣w∣<2△w2△w≤w≤π利用卷积定理,Blackman-Tukey可以表示为:
R ^ x ( P S ) ( e j w ) = ∑ l = − ( L − 1 ) L − 1 r ^ x ( l ) w a ( l ) e − j w l \hat{R}^{(PS)}_{x}(e^{jw})=\sum_{l=-(L-1)}^{L-1}\hat{r}_x(l)w_a(l)e^{-jwl} R^x(PS)(ejw)=l=−(L−1)∑L−1r^x(l)wa(l)e−jwl其中, w a ( l ) = s i n ( l △ w / 2 ) π l , − ∞ < l < ∞ w_a(l)=\frac{sin(l\bigtriangleup w /2)}{\pi l},-\infty < l < \infty wa(l)=πlsin(l△w/2),−∞<l<∞。
R ^ x ( P S ) ( e j w ) \hat{R}^{(PS)}_{x}(e^{jw}) R^x(PS)(ejw)的均值
E { R ^ x ( P S ) ( e j w ) } = ∑ l = − ( L − 1 ) L − 1 E { r ^ x ( l ) } w a ( l ) e − j w l = ∑ l = − ( L − 1 ) L − 1 r x ( l ) ( 1 − ∣ l ∣ N ) w a ( l ) e − j w l E\{\hat{R}^{(PS)}_{x}(e^{jw})\}= \\ \begin{array}{lr} \sum_{l=-(L-1)}^{L-1}E\{\hat{r}_x(l)\}w_a(l)e^{-jwl} \\ =\sum_{l=-(L-1)}^{L-1}r_x(l)(1-\frac{|l|}{N})w_a(l)e^{-jwl} \end{array} E{ R^x(PS)(ejw)}=∑l=−(L−1)L−1E{ r^x(l)}wa(l)e−jwl=∑l=−(L−1)L−1rx(l)(1−N∣l∣)wa(l)e−jwl结论是,当相关窗的谱是单位面积的,即 1 2 π ∫ − π π W a ( e j w ) d w = w a ( 0 ) = 1 \frac{1}{2\pi}\int_{-\pi}^{\pi}W_a(e^{jw})dw=w_a(0)=1 2π1∫−ππWa(ejw)dw=wa(0)=1时, R ^ x ( P S ) ( e j w ) \hat{R}^{(PS)}_{x}(e^{jw}) R^x(PS)(ejw)是一个渐近无偏估计,在这种条件下如果L和N趋向于无穷,那么就能够再现出 R x ( e j w ) R_{x}(e^{jw}) Rx(ejw)。
R ^ x ( P S ) ( e j w ) \hat{R}^{(PS)}_{x}(e^{jw}) R^x(PS)(ejw)的方差
结论:
v a r { R ^ x ( P S ) ( e j w ) } v a r { R ^ x ( e j w ) } ≃ E m N , 0 < w < π \frac{var\{\hat{R}^{(PS)}_{x}(e^{jw})\}}{var\{ \hat{R}_{x}(e^{jw})\}} \simeq \frac{E_m}{N},0
Welch-Bartlett法
思路:一般而言,K个IID随机变量和的方差是其中单个随机变量的方差的1/K倍。所以为了减少周期图的方差,我们可以对一个平稳随机信号的K个不同实现的周期图求平均,但是在大多数实际情况中,我们只能得到一个实现。在这种情况下,可以把存在的记录 { x ( n ) , 0 ≤ n ≤ N − 1 } \{x(n),0\le n \le N-1\} { x(n),0≤n≤N−1}再细分(可能会重叠)为K个小块:
x i ( n ) = x ( i D + n ) w ( n ) , 0 ≤ n ≤ L − 1 , 0 ≤ i ≤ K − 1 x_i(n)=x(iD+n)w(n),0\le n \le L-1,0 \le i \le K-1 xi(n)=x(iD+n)w(n),0≤n≤L−1,0≤i≤K−1式中, w ( n ) w(n) w(n)是一个持续时间为L的窗,D是偏移长度。如果D
R ^ x , i ( e j w ) = 1 L ∣ X i ( e j w ) ∣ 2 = 1 L ∣ ∑ n = 0 L − 1 x i ( n ) e − j w n ∣ 2 \hat{R}_{x,i}(e^{jw})=\frac{1}{L}|X_i(e^{jw})|^2=\frac{1}{L}|\sum_{n=0}^{L-1}x_i(n)e^{-jwn}|^2 R^x,i(ejw)=L1∣Xi(ejw)∣2=L1∣n=0∑L−1xi(n)e−jwn∣2通过对K个周期图求平均得到谱估计 R ^ x ( P A ) ( e j w ) \hat{R}_x^{(PA)}(e^{jw}) R^x(PA)(ejw):
R ^ x ( P A ) ( e j w ) = 1 K ∑ i = 1 K − 1 R ^ x , i ( e j w ) = 1 K L ∑ i = 0 K − 1 ∣ X i ( e j w ) ∣ 2 \hat{R}_x^{(PA)}(e^{jw})=\frac{1}{K}\sum_{i=1}^{K-1}\hat{R}_{x,i}(e^{jw})=\frac{1}{KL}\sum_{i=0}^{K-1}|X_i(e^{jw})|^2 R^x(PA)(ejw)=K1i=1∑K−1R^x,i(ejw)=KL1i=0∑K−1∣Xi(ejw)∣2
R ^ x ( P A ) ( e j w ) \hat{R}_x^{(PA)}(e^{jw}) R^x(PA)(ejw)的均值
结论为:
R ^ x ( P A ) ( e j w ) = 1 K ∑ i = 0 K − 1 E { R ^ x , i ( e j w ) } = E R ^ x ( e j w ) \hat{R}_x^{(PA)}(e^{jw})=\frac{1}{K}\sum_{i=0}^{K-1}E\{\hat{R}_{x,i}(e^{jw})\}=E{\hat{R}_x(e^{jw})} R^x(PA)(ejw)=K1i=0∑K−1E{ R^x,i(ejw)}=ER^x(ejw)当数据窗是归一化的,即: ∑ n = 0 L − 1 w 2 ( n ) = L \sum_{n=0}^{L-1}w^2(n)=L ∑n=0L−1w2(n)=L时, R ^ x ( P A ) ( e j w ) \hat{R}_x^{(PA)}(e^{jw}) R^x(PA)(ejw)为渐近无偏估计。
R ^ x ( P A ) ( e j w ) \hat{R}_x^{(PA)}(e^{jw}) R^x(PA)(ejw)的方差
R ^ x ( P A ) ( e j w ) \hat{R}_x^{(PA)}(e^{jw}) R^x(PA)(ejw)的方差是:
v a r { R ^ x ( P A ) ( e j w ) } = 1 K v a r { R ^ x ( e j w ) } var\{\hat{R}_x^{(PA)}(e^{jw})\}=\frac{1}{K}var\{\hat{R}_x(e^{jw})\} var{ R^x(PA)(ejw)}=K1var{ R^x(ejw)}随着K的增加,方差趋近于零,因此 R ^ x ( P A ) ( e j w ) \hat{R}_x^{(PA)}(e^{jw}) R^x(PA)(ejw)给出了 R x ( e j w ) R_x(e^{jw}) Rx(ejw)的一个渐近无偏估计和一致性估计。
第五章
习题5.4
A process y ( n ) y(n) y(n) with the autocorrelation r y ( l ) = a ∣ l ∣ , − 1 < a < 1 r_y (l) = a|l|, −1
uncorrelated white noise v ( n ) v(n) v(n) with variance σ v 2 σ^2_v σv2. To reduce the noise in the observed process x ( n ) = y ( n ) + v ( n ) x(n) = y(n) + v(n) x(n)=y(n)+v(n), we use a first-order Wiener filter.
(a) Express the coefficients c o , 1 c_{o,1} co,1 and c o , 2 c_{o,2} co,2 and the MMSE P o P_o Po in terms of parameters a a a and σ v 2 σ^2_v σv2.
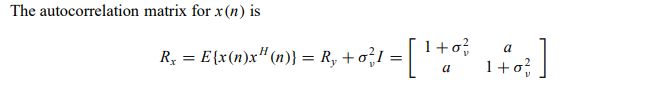

习题5.24
Let x ( n ) = s ( n ) + v ( n ) x(n) = s(n) + v(n) x(n)=s(n)+v(n) with R v ( z ) = 1 , R s v ( z ) = 0 R_v(z) = 1, R_{sv}(z) = 0 Rv(z)=1,Rsv(z)=0, and
R s ( z ) = 0.75 ( 1 − 0.5 z − 1 ) ( 1 − 0.5 z ) R_s(z) = \frac{0.75}{(1 − 0.5z−1)(1 − 0.5z)} Rs(z)=(1−0.5z−1)(1−0.5z)0.75
Determine the optimum filters for the estimation of s ( n ) s(n) s(n) and s ( n − 2 ) s(n − 2) s(n−2) from { x ( k ) } − ∞ n \{x(k)\}^n_{-\infty} { x(k)}−∞nand the
corresponding MMSEs.

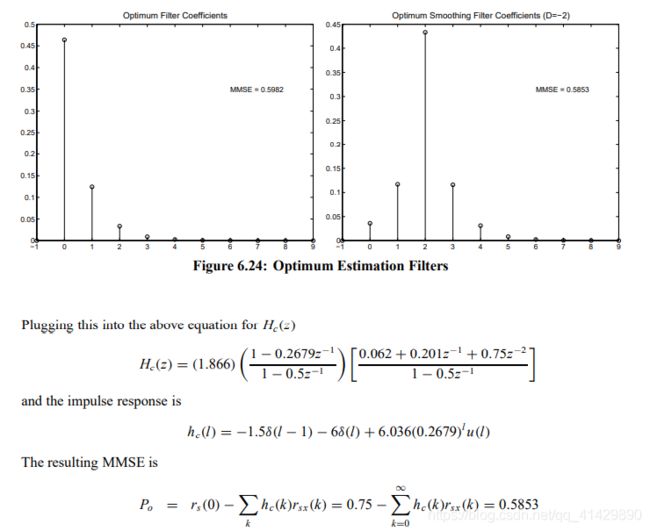
习题5.25
For the random signal with PSD
R x ( z ) = ( 1 − 0.2 z − 1 ) ( 1 − 0.2 z ) ( 1 − 0.9 z − 1 ) ( 1 − 0.9 z ) Rx (z) = \frac{(1 − 0.2z−1)(1 − 0.2z)}{ (1 − 0.9z−1)(1 − 0.9z)} Rx(z)=(1−0.9z−1)(1−0.9z)(1−0.2z−1)(1−0.2z)
determine the optimum two-step ahead linear predictor and the corresponding MMSE.


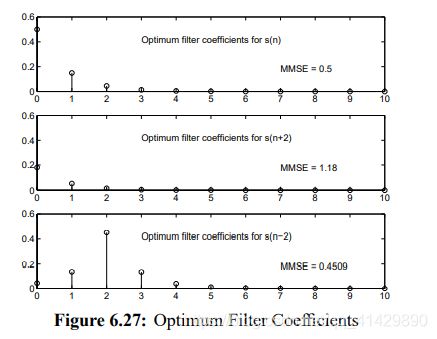
习题5.27
Let x ( n ) = s ( n ) + v ( n ) x(n) = s(n) + v(n) x(n)=s(n)+v(n) with $v(n) ∼ WN(0, 1) $ and s ( n ) = 0.6 s ( n − 1 ) + w ( n ) s(n) = 0.6s(n − 1) + w(n) s(n)=0.6s(n−1)+w(n), where
w ( n ) ∼ W N ( 0 , 0.82 ) w(n) ∼ WN(0, 0.82) w(n)∼WN(0,0.82). The processes s ( n ) s(n) s(n) and v ( n ) v(n) v(n) are uncorrelated. Determine the optimum
filters for the estimation of s ( n ) , s ( n + 2 ) s(n), s(n + 2) s(n),s(n+2), and s ( n − 2 ) s(n − 2) s(n−2) from { x ( k ) } − ∞ n \{x(k)\}^n_{-\infty} { x(k)}−∞n and the corresponding MMSEs.



知识点
最佳信号估计
估计信号 y ^ ( n ) \hat{y}(n) y^(n)和期望响应 y ( n ) y(n) y(n)之间的差别见下式,被称为误差信号:
e ( n ) = y ( n ) − y ^ ( n ) e(n)=y(n)-\hat{y}(n) e(n)=y(n)−y^(n)均方误差准则(MSE): P ( n ) = E { ∣ e ( n ) ∣ 2 } P(n)=E\{|e(n)|^2\} P(n)=E{ ∣e(n)∣2},它会使最佳估计器呈非线性。
线性均方误差估计
目标:设计一个估计器,使用数据 x k ( n ) , 1 ≤ k ≤ M x_k(n),1\le k \le M xk(n),1≤k≤M的线性组合,对期望相应 y ( n ) y(n) y(n)做估计,使MSE E { ∣ y ( n ) − y ^ ( n ) ∣ 2 } E\{|y(n)-\hat{y}(n)|^2\} E{ ∣y(n)−y^(n)∣2}最小,线性估计器可以定义为:
y ^ ( n ) = ∑ k = 1 M c k ∗ ( n ) x k ( n ) \hat{y}(n)=\sum_{k=1}^Mc^*_k(n)x_k(n) y^(n)=k=1∑Mck∗(n)xk(n),写成向量形式为:
y ^ = ∑ k = 1 M c k ∗ x k = c H x \hat{y}=\sum_{k=1}^M c^*_k x_k = \mathbf{c^Hx} y^=k=1∑Mck∗xk=cHx其中: x = [ x 1 , x 2 , ⋯ x M ] T \mathbf{x}=[x_1,x_2,\cdots x_M]^T x=[x1,x2,⋯xM]T, c = [ c 1 , c 2 , ⋯ c M ] T \mathbf{c}=[c_1,c_2,\cdots c_M]^T c=[c1,c2,⋯cM]T其中,M称为估计器的阶数,MSE为:
P = E { ∣ e ∣ 2 } e = y − y ^ P=E\{|e|^2\} \\ e=y-\hat{y} P=E{ ∣e∣2}e=y−y^选取合适的 c k c_k ck使上式最小化,可以得到最佳的参数矢量 c 0 \mathbf{c_0} c0。
最佳参数的求解
由
P ( c ) = E { ∣ e ∣ 2 } = E { ( y − c H x ) ( y ∗ − x H c ) } P(\mathbf{c})=E\{|e|^2\}=E\{(y-\mathbf{c^Hx})(y^*-\mathbf{x^Hc})\} P(c)=E{ ∣e∣2}=E{ (y−cHx)(y∗−xHc)}
可推导得:
P ( c ) = P y − d H R − 1 d + ( R c − d ) H R − 1 ( R c − d ) P(\mathbf{c})=P_y-\mathbf{d^HR^{-1}d+(Rc-d)^HR^{-1}(Rc-d)} P(c)=Py−dHR−1d+(Rc−d)HR−1(Rc−d)上式中,只有第三项取决于 c \mathbf{c} c,因此,当 R c − d = 0 \mathbf{Rc-d=0} Rc−d=0时就可得到最佳估计。所以得到最佳估计器的参数 c 0 \mathbf{c_0} c0的充分必要条件是:
R c 0 = d \mathbf{Rc_0}=d Rc0=d,R是正定矩阵。更详细的,可以写成:
[ r 11 r 12 ⋯ r 1 M r 21 r 22 ⋯ r 2 M ⋮ ⋮ ⋱ ⋮ r M 1 r M 2 ⋯ r M M ] [ c 1 c 2 ⋮ c M ] = [ d 1 d 2 ⋮ d M ] \left[\begin{matrix} r_{11} & r_{12} & \cdots & r_{1M} \\ r_{21} & r_{22} & \cdots & r_{2M} \\ \vdots & \vdots & \ddots & \vdots \\ r_{M1} & r_{M2} & \cdots & r_{MM} \end{matrix} \right] \left[\begin{matrix} c_1 \\ c_2 \\ \vdots \\ c_M \end{matrix}\right] = \left[\begin{matrix} d_1 \\ d_2 \\ \vdots \\ d_M \end{matrix}\right] ⎣⎢⎢⎢⎡r11r21⋮rM1r12r22⋮rM2⋯⋯⋱⋯r1Mr2M⋮rMM⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡c1c2⋮cM⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡d1d2⋮dM⎦⎥⎥⎥⎤其中: r i j = E { x i x j ∗ } = r j i ∗ r_{ij}=E\{x_ix^*_j\}=r^*_{ji} rij=E{ xixj∗}=rji∗, d i = E { x i y ∗ } d_i=E\{x_iy^*\} di=E{ xiy∗},此时的MMSE为:
P 0 = P y − d H R − 1 d = P y − d H c 0 P_0=P_y-\mathbf{d^HR^{-1}d}=P_y-\mathbf{d^Hc_0} P0=Py−dHR−1d=Py−dHc0通过上式很容易看出:最佳估计器和MMSE仅依赖于期望响应和输入数据的二阶矩。 d H c 0 \mathbf{d^Hc_0} dHc0和 E { ∣ y ^ 0 ∣ 2 } E\{|\hat{y}_0|^2\} E{ ∣y^0∣2}是相等的(最佳估计的功率),当 x , y \mathbf{x},y x,y无关时( d = 0 \mathbf{d}=0 d=0),是最坏的情况( P 0 = P y P_0=P_y P0=Py),因为没有线性估计能够减少MSE。
如果 c ~ \mathbf{\tilde{c}} c~是最佳估计器参数的偏差,即 c = c 0 + c ~ \mathbf{c=c_0+\tilde{c}} c=c0+c~,我们可以得到:
P ( c 0 + c ~ ) = P ( c 0 ) + c ~ H R c ~ P(\mathbf{c_0+\tilde{c}})=P(\mathbf{c_0})+\mathbf{\tilde{c}^HR\tilde{c}} P(c0+c~)=P(c0)+c~HRc~
即估计器参数的偏差会增大MSE的值,增大的数量被称为超量均方误差:
E x c e s s M S E = P ( c 0 + c ~ ) − P ( c 0 ) = c ~ H R c ~ Excess MSE =P(\mathbf{c_0+\tilde{c}})- P(\mathbf{c_0})=\mathbf{\tilde{c}^HR\tilde{c}} ExcessMSE=P(c0+c~)−P(c0)=c~HRc~超量均方误差仅取决于输入的相关矩阵,与期望相应无关,因此,任何与最佳参数值的偏差都能通过监测MSE而发现。
正交原理:
E { x e 0 ∗ } = E { x ( y ∗ − x H c 0 ) } = d − R c 0 = 0 E\{\mathbf{x}e^*_0\}=E\{\mathbf{x(y^*-x^Hc_0)}\}=\mathbf{d-Rc_0}=0 E{ xe0∗}=E{ x(y∗−xHc0)}=d−Rc0=0即估计器在最佳参数下工作时,误差 e 0 e_0 e0既与数据 x 1 , x 2 , ⋯ , x M x_1,x_2,\cdots,x_M x1,x2,⋯,xM无关,也与最佳估计值 y ^ 0 \hat{y}_0 y^0无关(正交)。
最佳有限脉冲响应滤波器
对于一个线性FIR滤波器,他的脉冲响应由 h ( n , k ) h(n,k) h(n,k)表示,滤波器的输出为:
y ^ ( n ) = ∑ k = 0 N − 1 h ( n , k ) x ( n − k ) = ∑ k = 0 N − 1 c k ∗ ( n ) x ( n − k + 1 ) = c H ( n ) x ( n ) \begin{array}{lr} \hat{y}(n) & =\sum_{k=0}^{N-1}h(n,k)x(n-k) \\ &=\sum_{k=0}^{N-1}c^*_k(n)x(n-k+1) \\ &=\mathbf{c^H(n)x(n)} \end{array} y^(n)=∑k=0N−1h(n,k)x(n−k)=∑k=0N−1ck∗(n)x(n−k+1)=cH(n)x(n)其中, x ( n ) = [ x ( n ) , x ( n − 1 ) , ⋯ , x ( n − M + 1 ) ] T \mathbf{x(n)}=[x(n),x(n-1),\cdots,x(n-M+1)]^T x(n)=[x(n),x(n−1),⋯,x(n−M+1)]T, c ( n ) = [ c 1 ( n ) , c 2 ( n ) , ⋯ , c M ( n ) ] T \mathbf{c(n)}=[c_1(n),c_2(n),\cdots,c_M(n)]^T c(n)=[c1(n),c2(n),⋯,cM(n)]T,我们可以得到以下方程组进而求解MMSE下的参数:
R ( n ) c 0 ( n ) = d ( n ) R ( n ) = E { x ( n ) x H ( n ) } d ( n ) = E { x ( n ) y ∗ ( n ) } \mathbf{R}(n)\mathbf{c}_0(n)=\mathbf{d}(n) \\ \mathbf{R}(n)=E\{\mathbf{x}(n)\mathbf{x^H}(n)\} \\ \mathbf{d}(n)=E\{\mathbf{x}(n)y^*(n)\} R(n)c0(n)=d(n)R(n)=E{ x(n)xH(n)}d(n)=E{ x(n)y∗(n)}最佳参数下的MMSE: P 0 ( n ) = P y ( n ) − d H ( n ) c 0 ( n ) P_0(n)=P_y(n)-\mathbf{d^H}(n)\mathbf{c}_0(n) P0(n)=Py(n)−dH(n)c0(n)其中, P y ( n ) = E { ∣ y ( n ) ∣ 2 } P_y(n)=E\{|y(n)|^2\} Py(n)=E{ ∣y(n)∣2}。
平稳过程的最佳FIR滤波器
如果输入的信号和所需的响应信号的随机过程是联合广义平稳的,输入信号的相关矩阵和互相关矢量并不依赖于时间序号 n n n,因此,最佳滤波器和MMSE是非时变的(即不依赖于时间信号n),由下面两式决定:
R c 0 = d P 0 = P y − d H c 0 \mathbf{Rc_0=d} \\ P_0=P_y-\mathbf{d^Hc_0} Rc0=dP0=Py−dHc0,由于平稳性的原因,自相关矩阵为:
R = [ r x ( 0 ) r x ( 1 ) ⋯ r x ( M − 1 ) r x ∗ ( 1 ) r x ( 0 ) ⋯ r x ( M − 2 ) ⋮ ⋮ ⋱ ⋮ r x ∗ ( M − 1 ) r x ∗ ( M − 2 ) ⋯ r x ( 0 ) ] \mathbf{R}=\left[\begin{matrix} r_x(0) & r_x(1) & \cdots & r_x(M-1) \\ r^*_x(1) & r_x(0) & \cdots & r_x(M-2) \\ \vdots & \vdots & \ddots & \vdots \\ r^*_x(M-1) & r^*_x(M-2) & \cdots & r_x(0) \end{matrix}\right] R=⎣⎢⎢⎢⎡rx(0)rx∗(1)⋮rx∗(M−1)rx(1)rx(0)⋮rx∗(M−2)⋯⋯⋱⋯rx(M−1)rx(M−2)⋮rx(0)⎦⎥⎥⎥⎤由于滤波器是非时变的,它可以用卷积来实现:
y ^ 0 = ∑ k = 0 M − 1 h 0 ( k ) x ( n − k ) \hat{y}_0=\sum_{k=0}^{M-1}h_0(k)x(n-k) y^0=k=0∑M−1h0(k)x(n−k),MMSE为:
KaTeX parse error: Expected group after '_' at position 3: P_̲_0=P_y-\sum_{k=…
频域解释
结论:
P 0 = 1 2 π ∫ − π π [ 1 − ∣ R y x ( e j w ) ∣ 2 R y ( e j w ) R x ( e j w ) ] R y ( e j w ) P 0 = 1 2 π ∫ − π π [ 1 − G y x ( e j w ) ] R y ( e j w ) d w P_0=\frac{1}{2\pi}\int_{-\pi}^{\pi}[1-\frac{|R_{yx}(e^{jw})|^2}{R_y(e^{jw})R_x(e^{jw})}]R_y(e^{jw}) \\ P_0=\frac{1}{2\pi}\int_{-\pi}^{\pi}[1-G_{yx}(e^{jw})]R_y(e^{jw})dw P0=2π1∫−ππ[1−Ry(ejw)Rx(ejw)∣Ryx(ejw)∣2]Ry(ejw)P0=2π1∫−ππ[1−Gyx(ejw)]Ry(ejw)dw
仅当 x ( n ) , y ( n ) x(n),y(n) x(n),y(n)之间存在显著的相关性(即: G y x ( e j w ≃ 1 ) G_{yx}(e^{jw}\simeq 1) Gyx(ejw≃1)时),最佳滤波器才可以在一定的频段上减少MMSE。
线性预测
线性信号估计
目的:通过随机过程的一些样本值 x ( n ) , x ( n − 1 ) , ⋯ , x ( n − M ) x(n),x(n-1),\cdots ,x(n-M) x(n),x(n−1),⋯,x(n−M),希望用其估计 x ( n − i ) x(n-i) x(n−i)的值,所得到的估计值和相应的估计误差如下:
x ^ ( n − i ) = − ∑ k = 0 M c k ∗ ( n ) x ( n − k ) e ( i ) ( n ) = x ( n − i ) − x ^ ( n − i ) = ∑ k = 0 M c k ∗ ( n ) x ( n − k ) \hat{x}(n-i)=-\sum_{k=0}^Mc^*_k(n)x(n-k) \\ e^{(i)}(n)=x(n-i)-\hat{x}(n-i)=\sum_{k=0}^Mc^*_k(n)x(n-k) x^(n−i)=−k=0∑Mck∗(n)x(n−k)e(i)(n)=x(n−i)−x^(n−i)=k=0∑Mck∗(n)x(n−k),其中 c i ( n ) = 1 c_i(n)=1 ci(n)=1
其MMSE参数计算方程为:
[ R 11 ( n ) R 12 ( n ) R 12 T ( n ) R 22 ( n ) ] [ c 1 ( n ) c 2 ( n ) ] = − [ r 1 ( n ) r 2 ( n ) ] \left[\begin{matrix} \mathbf{R}_{11}(n) & \mathbf{R}_{12}(n) \\ \mathbf{R}^T_{12}(n) & \mathbf{R}_{22}(n) \end{matrix}\right] \left[\begin{matrix} \mathbf{c}_1(n) \\ \mathbf{c}_2(n) \end{matrix}\right]=-\left[\begin{matrix} \mathbf{r}_1(n) \\ \mathbf{r}_2(n) \end{matrix}\right] [R11(n)R12T(n)R12(n)R22(n)][c1(n)c2(n)]=−[r1(n)r2(n)]和 P 0 ( i ) ( n ) = P x ( n − i ) + r 1 H ( n ) c 1 ( n ) + r 2 H ( n ) c 2 ( n ) P^{(i)}_0(n)=P_x(n-i)+\mathbf{r}^H_1(n)\mathbf{c}_1(n)+\mathbf{r}^H_2(n)\mathbf{c}_2(n) P0(i)(n)=Px(n−i)+r1H(n)c1(n)+r2H(n)c2(n),这里:
R i j ( n ) = E { x i ( n ) x j H ( n ) } r j ( n ) = E { x j ( n ) x ∗ ( n − i ) } P x ( n ) = E { ∣ x ( n ) ∣ 2 } \mathbf{R}_{ij}(n)=E\{\mathbf{x_i(n)}\mathbf{x^H_j(n)}\} \\ \mathbf{r}_j(n)=E\{\mathbf{x}_j(n)x^*(n-i)\} \\ P_x(n)=E\{|x(n)|^2\} Rij(n)=E{ xi(n)xjH(n)}rj(n)=E{ xj(n)x∗(n−i)}Px(n)=E{ ∣x(n)∣2}我们可以将上面两式合并为一个等式:
R ˉ ( n ) c ˉ 0 ( i ) ( n ) = [ 0 P 0 ( i ) ( n ) 0 ] \bar{\mathbf{R}}(n)\bar{\mathbf{c}}_0^{(i)}(n)=\left[\begin{matrix} \mathbf{0} \\ P_0^{(i)}(n) \\ 0 \end{matrix}\right] Rˉ(n)cˉ0(i)(n)=⎣⎡0P0(i)(n)0⎦⎤其中,只有第i行不为0,
R ˉ ( n ) = E { x ˉ ( n ) x ˉ H ( n ) } = [ R 11 ( n ) r 1 ( n ) R 12 ( n ) r 1 H ( n ) P x ( n − i ) r 2 H ( n ) R 12 H ( n ) r 2 ( n ) R 22 ( n ) ] \bar{\mathbf{R}}(n)=E\{\bar{\mathbf{x}}(n)\bar{\mathbf{x}}^H(n)\}=\left[\begin{matrix} \mathbf{R}_{11}(n) & \mathbf{r}_{1}(n) & \mathbf{R}_{12}(n) \\ \mathbf{r}_{1}^H(n) & P_x(n-i) & \mathbf{r}_{2}^H(n) \\ \mathbf{R}_{12}^H(n) & \mathbf{r}_{2}(n) & \mathbf{R}_{22}(n) \end{matrix}\right] Rˉ(n)=E{ xˉ(n)xˉH(n)}=⎣⎡R11(n)r1H(n)R12H(n)r1(n)Px(n−i)r2(n)R12(n)r2H(n)R22(n)⎦⎤其中:
x ˉ ( n ) = [ x 1 ( n ) x ( n − i ) x 2 ( n ) ] \bar{\mathbf{x}}(n)=\left[\begin{matrix} \mathbf{x}_1(n) \\ x(n-i) \\ \mathbf{x}_2(n) \end{matrix}\right] xˉ(n)=⎣⎡x1(n)x(n−i)x2(n)⎦⎤
前向线性预测
用 x ( n − 1 ) , ⋯ , x ( n − M ) x(n-1),\cdots,x(n-M) x(n−1),⋯,x(n−M)的值来预测 x ( n ) x(n) x(n)的值。误差计为:
e f ( n ) = x ( n ) + ∑ k = 1 M a k ∗ ( n ) x ( n − k ) = x ( n ) + a H ( n ) x ( n − 1 ) \begin{array}{lr} e^f(n)&=x(n)+\sum_{k=1}^Ma^*_k(n)x(n-k) \\ &=x(n)+\mathbf{a^H}(n)\mathbf{x}(n-1) \end{array} ef(n)=x(n)+∑k=1Mak∗(n)x(n−k)=x(n)+aH(n)x(n−1)其中: a ( n ) = [ a 1 ( n ) , a 2 ( n ) , ⋯ , a M ( n ) ] T \mathbf{a}(n)=[a_1(n),a_2(n),\cdots,a_M(n)]^T a(n)=[a1(n),a2(n),⋯,aM(n)]T。
MMSE参数的求解方程:
R ˉ ( n ) [ 1 a 0 ( n ) ] = [ P 0 f ( n ) 0 ] \bar{\mathbf{R}}(n)\left[\begin{matrix} 1 \\ \mathbf{a}_0(n) \end{matrix}\right]=\left[\begin{matrix} P^f_0(n) \\ \mathbf{0} \end{matrix}\right] Rˉ(n)[1a0(n)]=[P0f(n)0]其中:
R ˉ ( n ) = [ P x ( n ) r f H ( n ) r f ( n ) R ( n − 1 ) ] \bar{\mathbf{R}}(n)=\left[\begin{matrix} P_x(n) & \mathbf{r}^{fH}(n) \\ \mathbf{r}^f(n) & \mathbf{R}(n-1) \end{matrix}\right] Rˉ(n)=[Px(n)rf(n)rfH(n)R(n−1)]
R ( n ) = E { x ( n ) x H ( n ) } \mathbf{R}(n)=E\{\mathbf{x}(n)\mathbf{x}^H(n)\} R(n)=E{ x(n)xH(n)}
r f ( n ) = E { x ( n − 1 ) x ∗ ( n ) } \mathbf{r}^f(n)=E\{\mathbf{x}(n-1)x^*(n)\} rf(n)=E{ x(n−1)x∗(n)}
后向线性预测
目的:通过将来的样本值 x ( n ) , x ( n − 1 ) , ⋯ , x ( n − M + 1 ) x(n),x(n-1),\cdots,x(n-M+1) x(n),x(n−1),⋯,x(n−M+1)来估计 x ( n − M ) x(n-M) x(n−M)的值,误差计为:
e b ( n ) = ∑ k = 0 M − 1 b k ∗ ( n ) x ( n − k ) + x ( n − M ) = b H ( n ) x ( n ) + x ( n − M ) \begin{array}{lr} e^b(n)&=\sum_{k=0}^{M-1}b^*_k(n)x(n-k)+x(n-M) \\ &=\mathbf{b^H}(n)\mathbf{x}(n)+x(n-M) \end{array} eb(n)=∑k=0M−1bk∗(n)x(n−k)+x(n−M)=bH(n)x(n)+x(n−M)其中: b ( n ) = [ b 0 ( n ) , b 1 ( n ) , ⋯ , b M − 1 ( n ) ] T \mathbf{b}(n)=[b_0(n),b_1(n),\cdots,b_{M-1}(n)]^T b(n)=[b0(n),b1(n),⋯,bM−1(n)]T。
MMSE参数的求解方程:
R ˉ ( n ) [ b 0 ( n ) 1 ] = [ 0 P 0 b ( n ) ] \bar{\mathbf{R}}(n)\left[\begin{matrix} \mathbf{b}_0(n) \\ 1 \end{matrix}\right]=\left[\begin{matrix} \mathbf{0} \\ P^b_0(n) \end{matrix}\right] Rˉ(n)[b0(n)1]=[0P0b(n)]其中:
R ˉ ( n ) = [ R ( n ) r b ( n ) r b H ( n ) P x ( n − M ) ] \bar{\mathbf{R}}(n)=\left[\begin{matrix} \mathbf{R}(n) & \mathbf{r}^{b}(n) \\ \mathbf{r}^{bH}(n) & P_x(n-M) \end{matrix}\right] Rˉ(n)=[R(n)rbH(n)rb(n)Px(n−M)]
R ( n ) = E { x ( n ) x H ( n ) } \mathbf{R}(n)=E\{\mathbf{x}(n)\mathbf{x}^H(n)\} R(n)=E{ x(n)xH(n)}
r b ( n ) = E { x ( n ) x ∗ ( n − M ) } \mathbf{r}^b(n)=E\{\mathbf{x}(n)x^*(n-M)\} rb(n)=E{ x(n)x∗(n−M)}