PP-OCR: 3.5M超轻量中英文OCR模型详解(四) 文本识别优化瘦身策略
PP-OCR: A Practical Ultra Lightweight OCR System
论文地址:https://arxiv.org/abs/2009.09941
代码地址:https://github.com/PaddlePaddle/PaddleOCR
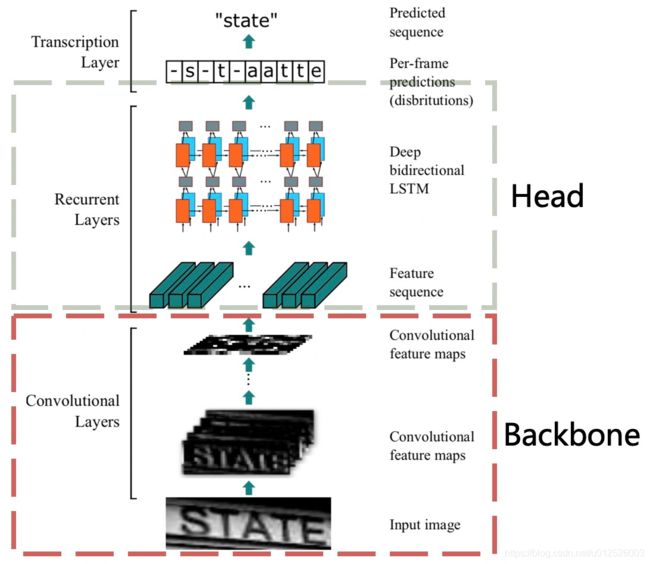
本文主要介绍PP-OCR中文本识别优化瘦身策略,首先会介绍实验环境,然后介绍超轻量骨干网络选择,数据增强,余弦学习率,增大特征图分辨率,正则化参数,预热学习率,头部轻量化,预训练大模型和PACT 量化的基本思路和消融实验。下图是PP-OCR中使用的文本识别算法CRNN的结构图,该图中虚线方框标出了骨干网络和网络头部部分。
1. 实验环境
文本识别的消融实验的训练集是从190万的真实数据中选择30万张图像,测试图像还是1.87万张真实图像。文中使用识别准确率(完全匹配率)指标用来评估一个文本识别器的效果。使用单个T4 GPU卡测试GPU时间,Intel® Xeon® Gold 6148 处理器测试CPU时间,骁龙855在手机上测试量化模型时间。
2.超轻量骨干网络选择
和文本检测类似,PP-OCR也是采用MobileNetV3作为文本识别的骨干网络。表1对比了不同骨干网络的文本识别效果。PP-OCR中选择MobileNetV3_small_x0.5对效果和效率进行折中。如果对大小不是很太敏感,MobileNetV3_small_x1也是一个不错的选择。

表1 不同骨干网络的文本识别效果
3.头部轻量化
通常会使用一个全连接层对序列特征进行编码,因此序列特征的维度对模型大小影响比较大,尤其对于中文需要识别6000多常见汉字的场景。从表2可以看出,将序列特征维度从256减小到48,模型大小从23M减小到4.6M,预测时间从17.27ms加速到12.26ms,识别准确率影响比较小。减小头部的序列特征的维度,速度收益比较明显。

表2 头部的不同通道数对文本识别效果的影响
4.数据增强
数据增强是提升文本识别效果的常用方法。除了在文本方向分类器章节中介绍的BDA(Base Data Augmentation,基于基本图像处理的数据增强),最近Luo等人针对文字识别提出的一种新的数据增强方法TIA,也是一种有效的策略。首先,设置一些参考点,然后将这些参考点进行随机扰动,并将相应的局部图像进行几何变换,形成新的变换图像。文章中的变换参数是可以学习的。在PP-OCR中,只使用在线数据增广,合成样本,并没有引入学习逻辑。从表3可以看出,不使用任何数据增广,也就是PP-OCR的v1.0版本策略,识别准确率只有0.5193。使用BDA数据增广,识别准确率大幅提升到0.5505。在后面的实验中,进一步使用TIA,可以使识别准确率提升0.9%,效果提升比较明显。


表3 数据增强、余弦学习率、增大特征图分辨率、正则化参数和预热学习对文本识别效果的影响
5.余弦学习率
如之前文本检测所述,采用余弦学习率可以有效提升模型效果。在文本识别中,同样非常有效。从表3可以看到,采用余弦学习率,识别准确率可以提升1.5%左右。
6.增大特征图分辨率
在PP-OCR中,文本识别的输入分辨率是3 * 32 * 320。MobileNetV3的原始stride变化策略并不适合文本识别。为了保留更多的水平方向图像的信息,除了第一次stride变化,其余stride变换都从(2,2)改为(2,1),为了进一步保留垂直方向图像的信息,将第二次stride变化,从(2,1)改为(1,1),整个网络的特征图的分辨率都变大。实验表明,特征图的分辨率变大,对识别效果影响很大。从表3可以看出,增大特征图的分辨率,识别准确率可以提升5.2%。

7.正则化参数
正则化一般是为了防止过拟合,添加到损失函数中。常用的正则化参数是L2正则化。如果使用L2正则化,整个网络权重值倾向变小,从而提升模型的泛化能力。从表3可以看出,正则化参数对识别结果影响很大。使用合适的正则化参数,识别准确率提升3.4%。
8.预热学习率
和文本检测类似,预热学习率也有助于提升文本识别效果。从表3可以看出,采用预热学习率,识别准确率提升0.7%左右。
9.预训练大模型
在图像分类、目标检测和图像分割中,使用ImageNet 1000训练的图像分类预训练模型,有助于模型快速收敛和效果提升。真实场景中,用于文本识别的数据往往有限,基于上千万场景丰富的数据训练的模型,也有助于真实场景中文本识别效果的提升。PP-OCR使用了1790万全量数据训练的模型,识别准确率是65.81%,然后在190万数据进行模型微调,识别准确率可以提升到69%。这个结论也说明,虽然全量数据场景丰富,对于特定场景效果不一定最优,对于特定场景的模型微调还是很有必要。
10.PACT 量化
与文本方向分类器类似,PP-OCR也采用PACT 量化减小模型大小。由于LSTM量化复杂性,目前的PP-OCR策略并没有对LSTM进行量化,实现中跳过该层。从表4可以看出,采用PACT量化文本识别,模型大小从4.6M减小到1.5M,预测时间从12ms降低到11ms,准确率有明显提升。预测时间提升不是很明显的原因是LSTM没有做量化导致的。准确率提升说明PACT 量化可以减小模型中的冗余,从而提升模型效果。

表 4 PACT 量化文本识别效果
感谢大家关注,PP-OCR: 3.5M超轻量中英文OCR模型详解系列总共有4个部分,列表如下:
(一) 简介、方案概览和数据
(二) 文本检测优化瘦身
(三) 文本方向分类器优化瘦身
(四) 文本识别优化瘦身
欢迎大家star PaddleOCR(https://github.com/PaddlePaddle/PaddleOCR),支持该repo的建设。感兴趣的朋友,可以加入Repo里面的PaddleOCR技术交流微信群,一起讨论OCR相关问题。