hadoop--之YARN框架流程
YARN平台简介
YARN的诞生的背景
在Hadoop1.0版本中MapReduce架构存在的许多问题,例如:
(一)无法支持更多的计算模型,Mapreduce将两个阶段计算模型MapReduce固化到了Hadoop系统中,无法更容易的支持更多的计算框架,比如Giraph,DAG,获取迭代计算框架,尽管当前很多计算框架,比如Griaph
通过在Map-Only类型的作业中初步实现了BSP模型,但用于Map类型资源均是一样的,无法实现资源定制化;
(二)应用程序相关和资源管理相关的逻辑全部放在一个服务(JobTracker)中,使得主服务压力过大,进而限制了系统的扩展性
YARN的作用
Yarn/MRv2最基本的想法是将原JobTracker主要的资源管理和job调度/监视功能分开作为两个单独的守护进程。有一个全局的ResourceManager(RM)和每个Application有一个ApplicationMaster(AM),Application相当于map-reduce job或者DAG jobs。ResourceManager和NodeManager(NM)组成了基本的数据计算框架。
ResourceManager协调集群的资源利用,任何client或者运行着的applicatitonMaster想要运行job或者task都得向RM申请一定的资 源。ApplicatonMaster是一个框架特殊的库,对于MapReduce框架而言有它自己的AM实现,用户也可以实现自己的AM,在运行的时候,AM会与NM一起来启动和监视tasks。
YARN的成员
YARN是Yet Another Resource Negotiator的简称,它仍可认为采用了master/slave结构,总体上采用了双层调度架构,它主要以下几 部分组成
ResourceManager:负责资源管理的主服务,整个系统只有一个,负责资源管理、调度和监控,它支持可插拔的资源调度器,自带了FIFO、Fair Scheduler和Capacity Scheduler三种调度器;
NodeManager:负责单个节点的资源管理和监控,它定期将资源使用情况汇报给ResourceManager,并接收来自ApplicationMaster的命令以启动Container(YARN中对资源的抽象),回收Container等;
ApplicationMaster:负责管理单个应用程序,它向ResourceManager申请资源,并使用这些资源启动内部的任务,同时负责任务的运行监控和容错等;
Container:对资源的抽象,它封装了某个节点上的CPU、内存等资源,ApplicationMaster只有获得一个Container后才能启动任务,另外,ApplicationMaster本身也是运行在一个Container之中
MRAppMaster规范
MRAppMaster是MapReduce的ApplicationMaster实现,它使得MapReduce计算框架可以运行于YARN之上。在YARN中,MRAppMaster负责管理MapReduce作业的生命周期,包括创建MapReduce作业,向ResourceManager申请资源,与NodeManage通信要求其启动Container,监控作业的运行状态,当任务失败时重新启动任务等。
container规范
Container是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)。
Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster
Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令(可以使任何命令,比如java、Python、C++进程启动命令均可)以及该命令执行所需的环境变量和外部资源(比如词典文件、可执行文件、jar包等)。
另外,一个应用程序所需的Container分为两大类,如下
运行ApplicationMaster的Container:这是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源;
运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster与NodeManager通信以启动之
mapreduce流程
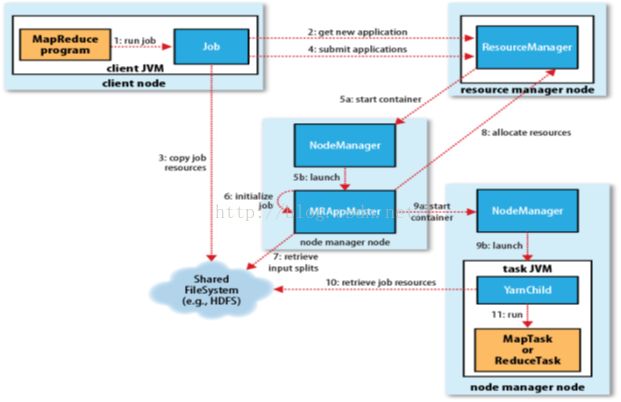
1,run job
在客户端,用户编写mapreduce程序,然后打包,通过方法 submit()提交作业,提交作业后,客户端每秒轮询一次resourcemanager以获取作业进度。
2,get new application 获取新的申请
Client 请求resourcemanager以获取运行工作的id ,以及检查输出目录,如果目录不存在,则抛出异常,然后检查输入目录,如果目录不存在,或者没有资源,则抛出异常
3,copy job resources 上传资源
客户端将打包好得jar包,以及配置文件,计算好的切片信息上传到HDFS上的一个以jobid命名的新建目录下。作业jar的副本默认为10
4,submit application
提交运行申请 通过submitapplication()提交申请。
5,start container launch
当resourcemanager 接收到submitapplication()方法传来的参数时,便将请求传递给调度器(schedular),调度器分配一个资源,而且在NodeManager的协助下在容器中启动一个master进程 MRAppMaster
6,initialize job
Mapreduce作业的application master 是一个Java程序,它的主类是MRAppMaster,它对作业进行初始化,通过创建多个对象,以保持对作业进度的跟踪因为他将接收来自任务的进度和完成报告。
MRAppMatser会初始化一定数量的记录对象(bookkeeping)来跟踪JOB的运行进度, 并收取每个TASK的进度和完成情况,接着MRAppMaster收集计算后的输入分片情况,如果应用程序很小,能在同一个JVM上运行,则用uber模式,下面会讲满足什么情况才采用uber模式。
7,retrieve input splits
MRAppMaster 从HDFS中获取计算好的切片信息,然后对每一个分片分配一个map任务,
8,allocate resources
如果不在uber模式下运行,则Application Master会为所有的Map和Reducer task向RM请求Container,所有的请求都通过heartbeat(心跳)传递,心跳也传递其他信息,例如关于map数据本地化的信息,分片所在的主机和机架地址信息,这些信息帮助调度器来做出调度的决策,调度器尽可能遵循数据本地化或者机架本地化的原则分配Container
。
在Yarn中,例如,用yarn.scheduler.capacity.minimum- allocation-mb设置最小申请资源1G,用yarn.scheduler.capacity.maximum-allocation-mb设置 最大可申请资源10G 这样一个Task申请的资源内存可以灵活的在1G~10G范围内
在Yarn中,例如,用yarn.scheduler.capacity.minimum- allocation-mb设置最小申请资源1G,用yarn.scheduler.capacity.maximum-allocation-mb设置 最大可申请资源10G 这样一个Task申请的资源内存可以灵活的在1G~10G范围内
9,start container lauch
获取到Container后,NM上的Application Master就联系NM启动Container,Task最后被一个叫org.apache.hadoop.mapred.YarnChild的main类执行,不过在此之前各个资源文件已经从分布式缓存拷贝下来,这样才能开始运行map Task或者reduce Task。PS:YarnChild是一个(dedicated)的JVM
10,retrieve job resources
NodeManager 从hdfs上下载运行所需要的资源信息,把jar包解压到当前节点上。
11,run
运行map() reduce()
12 当Yarn运行同时,各个Container会报告它的进度和状态给Application Master,客户端会每秒轮询检测Application Master,这样就随时收到更新信息,这些信息可以通过Web UI来查看
客户端每5秒轮询检查Job是否完成,期间需要调用函数Job类下waitForCompletion()方法,Job结束后该方法返回。轮询时间间隔可以用配置文件的属性mapreduce.client.completion.pollinterval来设置