pytorch笔记24-33数据进阶操作
文章目录
-
- 合并与分割
- 数据的运算
- 数据的属性统计
- 进阶操作
合并与分割
cat合并操作
a = torch.rand(4,32,8)
b = torch.rand(5,32,8)
torch.cat([a,b],dim=0).shape
# torch.Size([9, 32, 8])
stack合并:create new dim创建一个新的维度,要求两个tensor.shape完全一样
a = torch.rand(32,8)
b = torch.rand(32,8)
torch.stack([a,b],dim=0).shape
# torch.Size([2, 32, 8])
split数据拆分:按照拆分的长度进行拆分
c = torch.rand(4,32,8)
aa,bb=c.split([2,2],dim=0)
# 或者aa,bb=c.split(2,dim=0),因为[2,2]=2
aa.shape,bb.shape
# (torch.Size([2, 32, 8]), torch.Size([2, 32, 8]))
chunk数据拆分:按照拆分的数量进行拆分,不能整除时会报错,要用split指定操作解决
c = torch.rand(8,32,8)
aa,bb,cc,dd=c.chunk(4,dim=0)
aa.shape,bb.shape,cc.shape,dd.shape
# (torch.Size([2, 32, 8]),
torch.Size([2, 32, 8]),
torch.Size([2, 32, 8]),
torch.Size([2, 32, 8]))
数据的运算
基本运算
a = torch.rand(3,4)
b = torch.rand(4)
a+b # 在计算时会自动对b进行broadcasting操作
*表示对应位置乘,@/.matmul表示矩阵相乘
a = torch.ones(2,2)
b = torch.tensor([[3.,3.],[3.,3.]])
a@b,torch.matmul(a,b)
# (tensor([[6., 6.],
[6., 6.]])
# 比如我们对数据从784降维到512
x = torch.rand(4,784)
w = torch.rand(512,784) # 习惯第一个参数ch-out,第二个参数ch-in
(x@w.t()).shape
# .t()转置只适用于2D,高维使用transpose操作,torch.Size([4, 512])
**表示平方/.pow()
a = torch.full([2,2],3)
a.pow(2),a**2
aa = a**2
aa.sqrt() # 平方根
aa.rsqrt() # 平方根的倒数
# (tensor([[3., 3.],
[3., 3.]]),
tensor([[0.3333, 0.3333],
[0.3333, 0.3333]]))
# 注意这里只能对浮点数进行sqrt
Exp log指数
a = torch.exp(torch.ones(2,2))
a
# tensor([[2.7183, 2.7183],
[2.7183, 2.7183]])
torch.log(a)
# tensor([[1., 1.],
[1., 1.]])
近似取值
a = torch.tensor(3.14)
a.floor(),a.ceil(),a.trunc(),a.frac(),a.round()
# 向下(地板)取整,向上(天花板)取整,取整数,取小数,四舍五入
# (tensor(3.), tensor(4.), tensor(3.), tensor(0.1400), tensor(3.))
clamp限制数据,用在处理梯度较大时,做裁剪
# (min)/(min,max)
grad = torch.rand(2,3)*15
grad.max(),grad.min()
# (tensor(13.5919), tensor(0.8596))
grad.clamp(10) #小于10的取值为10
数据的属性统计
norm-p取范数
一范数:
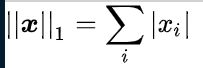
二范数:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8QsoRaI8-1611814879140)(https://www.zhihu.com/equation?tex=%5Cleft+%5C%7C+%5Cboldsymbol%7Bx%7D+%5Cright+%5C%7C_2+%3D+%5Csqrt%7B%5Csum_%7Bi%7Dx_i%5E2%7D)]](http://img.e-com-net.com/image/info8/80c96976e2c144cb87fef7403af5852e.jpg)
a = torch.full([8],1)
b = a.view(2,4)
c = a.view(2,2,2)
a.norm(1),b.norm(1),c.norm(1)
# (tensor(8.), tensor(8.), tensor(8.))
a.norm(2),b.norm(2),c.norm(2) # sqrt操作
# (tensor(2.8284), tensor(2.8284), tensor(2.8284))
#也可查看指定维度的norm
b,b.norm(1,dim=1)
# (tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.]]),
tensor([4., 4.]))
最大、最小、均值
a = torch.arange(8).view(2,4).float()
# tensor([[0., 1., 2., 3.],
[4., 5., 6., 7.]])
a.min(),a.max(),a.mean(),a.prod()# 累乘
# (tensor(0.), tensor(7.), tensor(3.5000), tensor(0.))
a.sum(),a.argmax(),a.argmin() # 返回最值的索引
# (tensor(28.), tensor(7), tensor(0))
# argmax默认将数据打平,若需要返回原维度的最值
a.max(dim=1)
# torch.return_types.max(
values=tensor([3., 7.]),
indices=tensor([3, 3])))
# 保持输出索引与原数据维度一致
a.max(dim=1,keepdim=True)
top-k最值得n-th个数据
a.topk(3,dim=1) # 前3大得数据
a.topk(3,dim=1,largest=False) # 前3小得数据
比较运算
torch.gt(a,0) # greater,找出比0大的元素,返回01
torch.eq(a,b) # 每个位置比较,返回0,1数组
torch.equal(a,b) # 返回True 或False
进阶操作
where
torch.where(cond,a,b )
gather(一张表到另一张表)
pro = torch.randn(4,10)
idx = pro.topk(3,dim=1)
idx = idx[1] #第一张图前3大概率的索引
label = torch.arange(10)+100
torch.gather(label.expand(4,10),dim=1,index=idx)
# tensor([[109, 100, 105],
[105, 107, 108],
[108, 102, 101],
[109, 106, 108]])