tensorflow 小于_Pytorch/Tensorflow-gpu训练并行加速trick(含代码)
为什么研究训练加速
之前只是直接用的一些API,大概知道哪些会方便一些快一些,但是具体的加速方式没细研究,也没有严格对比过对速度的提升。前一阵子做一些的项目,发现数据集在很大的情况下gpu的利用率很低,训练速度很慢,回想起来以前经常会在nvidia-smi里看到gpu利用率一直周期性跳动的问题。正好最近研究训练时GPU内存占用问题,就顺便系统地研究一下。本来想先看看pytorch的,看到有人提出Estimator+tf.data的解决方案,就先对比研究一下tensorflow的提速trick。
不同的任务,数据量,前处理复杂度,batch size, 不同的硬件,CPU, GPU,集群等,如何在特定条件下,取得最优的训练效率,是一个很有意义的课题。不管是在校的学生还是休闲炼丹爱好者,在抱怨算力太低之前,先把自己手上的这块cpu和gpu的内存和利用率压榨干净,也许能解决不少问题。
本文内容:
- tensorflow训练加速
- tf.data API中的prefetch和多线程对训练速度的影响
- Estimator方法(TBD)
- Dataloader中的num_workers和pin_memory设置
- torch.multiprocessing
- 超出显存的batch size设置
- 16-bit混合精度
Tensorflow训练加速
TF三种读取数据方式
- placeholder:定义feed_dict将数据feed进placeholder中,优点是比较灵活,方便大伙debug。官方:当只有一个GPU时,它与tf.data API的性能表现非常接近,当有多个GPU时就不如后者了。且大数据量下表现往往不佳。
- TensorFlow的queue_runner:这种方法是使用Python实现的,其性能受限于C++ multi-threading ,而tf.data API使用了C++ multi-threading ,大大降低了overhead。
- tf.data(官方力荐):它正在取代queue_runner成为官方推荐的构建Pipeline的API,经常与tf.estimator.Estimator一起使用。也是本文主要测试的方案。
tf.data API
关于tf.data,官网上是这么介绍的:除GPU 和 TPU 等硬件加速设备外, 高效的数据输入pipeline也可以很大程度提升模型的能,减少模型的训练时间。
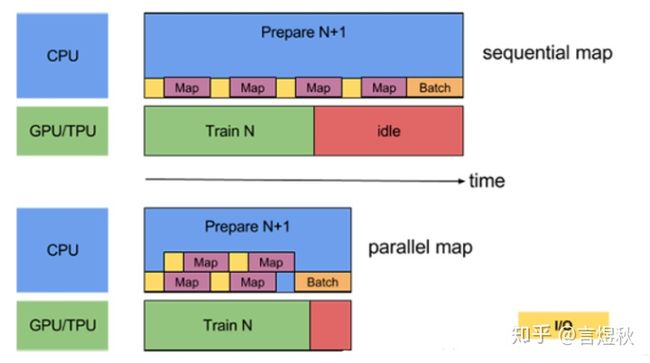
这里的“高效pipeline”简单来讲指的是:GPU要等CPU准备好数据才能跑,能否让CPU提前准备,趁GPU一个batch的数据时,把下一个epoch的数据准备好呢?


现在CPU都是多核的,如果数据的读取、预处理1、预处理2等都跑在一个cpu上,那么其他cpu也是空闲的,所以把数据的读取、预处理1、预处理2都分别分配在不同的cpu上,可以最大限度的减少idle的时间。
上述功能可以通过 tf.data.Dataset.prefetch(n) 这个函数实现,这里最重要的是这个n的设置,最好设置成一个training step需要使用的elements个数。源码
构建dataset最常用的方式就是 tf.data.Dataset.from_tensor_slices(),也可直接读取TFrecord,CSV等格式数据,这个文档也都有介绍。
几个常用函数:
- batch():参数为batch size。
- repeat():参数同样是一个整型数字,描述了整个dataset需要重复几次(epoch),如果没有参数,则重复无限次。
- shuffle():打乱数据,这里的参数是buffer_size,顾名思义,dataset会取所有数据的前buffer_size数据项,填充buffer, 然后,从buffer中随机选择一条数据输出,然后把空出来的位置从dataset中顺序选择最新的一条数据填充到buffer中。
- map(map_func,num_parallel_calls):常常用作预处理,图像解码等操作,第一个参数是一个函数句柄,dataset的每一个元素都会经过这个函数的到新的tensor代替原来的元素。第二个参数num_parallel_calls控制在CPU上并行和处理数据,将不同的预处理任务分配到不同的cpu上,实现并行加速的效果。num_parallel_calls一般设置为cpu内核数量,如果设置的太大反而会降低速度。源码
TRICK
tf.contrib.data.map_and_batch:
如果batch size成百上千的话,并行batch creation可以进一步提高pipline的速度,可以把map和batch混在一起来并行处理,使用上直接把map和batch两个函数替换为:
dataset = dataset.apply(tf.contrib.data.map_and_batch(map_func=parse_fn, batch_size=batch_size))Parallelize Data Extraction
单机时使用pipline可以取得很好的效果,但是在分布式训练时pipline则可能会成为瓶颈。
本地和远程存储的区别:
- Time-to-first-byte: remote storage的延时较长。
- Read throughput: 虽然remote storage具有较大的带宽,但是读取一个文件时只能使用很小的一部分带宽。
除此之外,即使把远端的数据读到了本地,还是需要串并转换和解码(TCP/IP协议),这些都会增加overhead。相比本地存储的数据,如果不进行有效的prefetch分布式训练的overhead会更长。
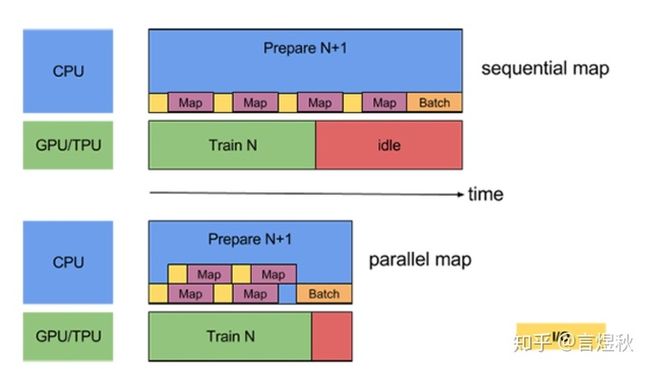
为了减轻数据导出的overhead,tensorflow提供了tf.contrib.data.parallel_interleave(并行交错) ,The number of datasets to overlap(dataset的重叠) can be specified by the cycle_length argument.
使用时把第一行改为第二行
#dataset = files.interleave(tf.data.TFRecordDataset)
dataset = files.apply(tf.contrib.data.parallel_interleave(tf.data.TFRecordDataset, cycle_length=FLAGS.num_parallel_readers))下图说明了为 parallel_interleave 转换提供 cycle_length=2 的效果
pipeline顺序
在把数据传给网络前,我们进行一些预处理,比如map、batch、cache、prefetch、interleave、shuffle等等,这些操作的前后顺序也会影响处理速度。
最佳策略:
- 将 prefetch(n)(其中 n 是单步训练使用的元素数/批次数)添加到输入pipeline的末尾,以便将在 CPU 上执行的转换与在GPU上执行的训练并行。
- 通过设置 num_parallel_calls 参数并行处理 map 转换。将其值设为可用 CPU 核心的数量。
- 使用的batch较大时,使用 map_and_batch 混合转换。
- 如果要处理远程存储的数据并/或需要反序列化,使用 parallel_interleave 转换来并行从不同文件读取(和反序列化)数据的操作。
- 向量化传递给 map 转换的低开销用户定义函数,以分摊与调度和执行相应函数相关的开销。
- 如果内存可以容纳数据,可以使用 cache 转换在第一个周期中将数据缓存在内存中,以便后续周期可以避免与读取、解析和转换该数据相关的开销。
- 如果预处理操作会增加数据大小,建议先进行 interleave、prefetch 和 shuffle 操作以减少内存使用量。
- 在repeat 前先进行 shuffle 转换,最好用 shuffle_and_repeat 混合转换。
具体的实现有的前文已经写过,没提到的可以参考(官方文档的翻译+归纳):
1. Tensorflow高效流水线Pipelinewww.cnblogs.com
PS:关于shuffle(),batch(),repect()的不同顺序的含义(函数首字母表示):
- SBR:把所有数据先打乱,然后按照batch size打包成batch输出,整体数据重复N遍(N个epoch)
- SRB:把所有数据先打乱,再把所有数据重复N遍,然后将重复N遍的所有数据放在一起,最后按照batch size打包成batch输出。(不常用,可能出现一个batch内有重复数据)
- BRS:把所有数据按照batch size先打包成batch,然后把打包成batch的数据重复N遍,最后再将所有batch打乱进行输出(打乱的是batch,某些batch的尺寸小于等于batch_size,因为是对batch进行打乱,所以这些batch不一定是最后一个)
整个epoch和每个batch的数据分布的多样性,会影响训练模型的鲁棒性。
运行pipeline
使用Iterator来得到数据集dataset类型的数据接口。
Dataset类型提供直接生成迭代器的函数:
- tf.data.Dataset.make_one_shot_iterator() :不需要用户显示地初始化,但是仅仅能迭代(遍历)一次数据集。
- tf.data.Dataset.make_initializable_iterator() : 需要用户显示地初始化,并且在初始化时可以送入之间定义的placeholder,达到更加灵活的使用。
- get_next() :迭代器,获取数据tensors(构建数据集所用的from_tensors_slice的参数形式)。
注意最后收尾的get_next要放在训练的循环外,只把调用的img,label ==sess.run(dataset) 放在循环内,不然会越跑越慢,原因显而易见,一定要搞清迭代器的逻辑。
实验
为了对比效果,先搭了一个普通读取数据方式的二分类训练流程,因为要探究如何提升低算力下的训练效率,就先在自己电脑上跑。
CPU : AMD Ryzen 5 3600 || GPU: 1660s
数据量为1000train+400valid的数据集,格式为jpeg,在前处理会统一resize到(64,64)。label为0或1,image path和label储存在txt文件中。
为了方便训练,测试,可视化数据集等脚本的调用,尽量把读取数据的代码单独存放。
普通读取方式
class Dataset(object):
def __init__(self, dataset_type):
self.annot_path = './DATA/train.txt' if dataset_type == 'train' else './DATA/test.txt'
self.batch_size = 8 if dataset_type == 'train' else 1 # 2
self.data_aug = True if dataset_type == 'train' else False
self.train_input_size = 64
self.annotations = self.load_annotations(dataset_type)
self.img_num = len(self.annotations)
self.step_per_epoch = int(np.ceil(self.img_num / self.batch_size))
self.step_index_epoch = 0
def load_annotations(self, dataset_type):
with open(self.annot_path, 'r') as f:
txt = f.readlines()
annotations = [line.strip() for line in txt if len(line.strip().split()[1:]) != 0]
np.random.shuffle(annotations)
return annotations
def __iter__(self):
return self
def __next__(self):
with tf.device('/cpu:0'):
batch_image = np.zeros((self.batch_size, self.train_input_size, self.train_input_size, 3))
batch_label = np.zeros((self.batch_size, 1))
i = 0
if self.step_index_epoch < self.step_per_epoch: # in one epoch
while i < self.batch_size: # in one batch
# try:
img_index = self.step_index_epoch * self.batch_size + i
if img_index >= self.img_num: # last batch cannot be rounded up
img_index -= self.img_num
annotation = self.annotations[img_index] # txt ===> ano
image, label = self.parse_annotation(annotation)
batch_image[i, :, :, :] = image # (h,w,c)
batch_label[i,:] = label
i += 1
self.step_index_epoch += 1
return batch_image, batch_label
else: # next epoch
self.step_index_epoch = 0
np.random.shuffle(self.annotations)
raise StopIteration
def parse_annotation(self, annotation): # get image and label from txtfile
line = annotation.split()
image_path = line[0]
label = line[1]
if not os.path.exists(image_path):
print(("%s does not exist ... " % image_path))
image = np.array(cv2.imread(image_path))
image = cv2.resize(image,(self.train_input_size, self.train_input_size))
return image, label
def __len__(self):
return self.step_per_epoch训练时通过以下代码调用:
for epoch in range(1, self.epoch):
train_epoch_loss, test_epoch_loss = [], []
for train_data in Dataset('train'):
_, train_summary, train_step_loss, train_predict, _, train_step = self.sess.run(
[self.train_op, self.merge_train_op, self.loss, self.predict, self.acc, self.step],
feed_dict = {
self.inputs: train_data[0],
self.labels: train_data[1],
self.training:True })
train_epoch_loss.append(train_step_loss)
for test_data in Dataset('test'):
test_step_loss, test_predict = self.sess.run(
[self.loss, self.predict],
feed_dict = {
self.inputs: test_data[0],
self.labels: test_data[1],
self.training:False })
test_epoch_loss.append(test_step_loss)
train_epoch_loss, test_epoch_loss = np.mean(train_epoch_loss), np.mean(test_epoch_loss)结果(单位默认为秒):
第1个epoch: train_cost:3.426 // test_cost:1.003
第2,3,4.....个epoch : train_cost: 1.76 // test_cost: 0.83 (后面基本在这个数值附近保持很小的波动)
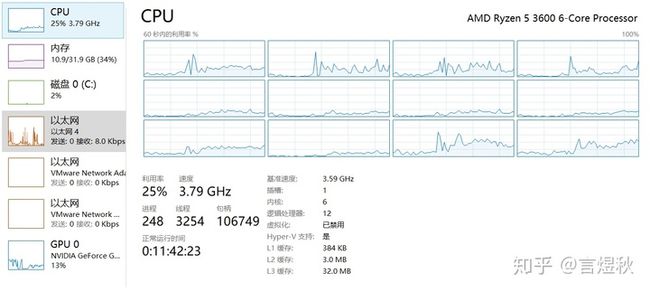
GPU利用率在30 - 50 %间浮动
CPU:可以看到大概只有6个线程比较忙,其他的虽然也被调动起来了但基本上在摸鱼。
使用td.data读取数据
这里有很多细节,建议还是去看一下tensorflow的官方文档:
tf.data: Build TensorFlow input pipelines | TensorFlow Coretensorflow.google.cn
首先读取数据: tf.data.Dataset.from_tensor_slices((image_paths, labels))
新构建的基于tf.data读取方式的dataset.py如下
def Dataset(file_list, batch_size):
def Dataset(file_list, batch_size):
image_paths, labels, img_num = gen_data(file_list)
dataset = tf.data.Dataset.from_tensor_slices((image_paths, labels))
# dataset = tf.data.TFRecordDataset(tf_records_filename)
dataset = dataset.map(_parse_data, num_parallel_calls=6)
dataset = dataset.shuffle(buffer_size=1000)
dataset = dataset.batch(batch_size)
dataset = dataset.repeat(1)
dataset = dataset.prefetch(2)
iterator = dataset.make_one_shot_iterator()
# iterator = dataset.make_initializable_iterator()
next_element = iterator.get_next()
return iterator, next_element, img_num
def _parse_data(image_path, label):
image_size = 64
image_channel = 3
file_contents = tf.read_file(image_path)
image = tf.image.decode_jpeg(file_contents, image_channel)
image = tf.image.resize_images(image, (image_size, image_size), method=0)
# image = tf.image.random_brightness(image, max_delta=60)
# image = tf.image.random_contrast(image, lower=0.2, upper=1.8)
image = tf.cast(image, tf.float32)
image = image / 256.0
label = tf.expand_dims(label,axis=0)
return (image, label)
def gen_data(file_list):
with open(file_list, 'r') as f:
lines = f.readlines()
image_paths, labels = [], []
for line in lines:
line = line.strip().split()
image_path = line[0]
label = line[1]
image_paths.append(image_path)
labels.append(label)
image_paths = np.asarray(image_paths, dtype=np.str)
labels = np.asarray(labels, dtype=np.float32)
return image_paths, labels, len(lines)训练时通过以下代码调用
train_iterator, train_next_element, len_train = Dataset('./DATA/train.txt', batch_size=self.batch_size_train)
test_iterator, test_next_element, len_test = Dataset('./DATA/test.txt', batch_size=self.batch_size_test)
image_batch_train_np, label_batch_train_np = train_next_element
image_batch_test_np, label_batch_test_np = test_next_element
# self.sess.run(test_iterator.initializer) 该阶段只需要初始化一次
for epoch in range(1, self.epoch):
train_epoch_loss, test_epoch_loss = [], []
# self.sess.run(train_iterator.initializer)#每个epoch初始化一次
for i in range(int(np.ceil(len_train/self.batch_size_train))):
image_batch, label_batch = self.sess.run([image_batch_train_np, label_batch_train_np])
_, train_summary, train_step_loss, train_predict, _, train_step = self.sess.run(
[self.train_op, self.merge_train_op, self.loss, self.predict, self.acc, self.step],
feed_dict = {self.inputs: image_batch,
self.labels: label_batch,
self.training:True })
train_epoch_loss.append(train_step_loss)
for i in range(int(np.ceil(len_test / self.batch_size_test))):
image_batch, label_batch = self.sess.run([image_batch_test_np, label_batch_test_np])
test_step_loss, test_predict = self.sess.run(
[self.loss, self.predict],
feed_dict = {self.inputs: image_batch,
self.labels: label_batch,
self.training:False })
test_epoch_loss.append(test_step_loss)PS:注释部分为使用iterator = dataset.make_initializable_iterator()的代码,会导致速度变慢约20%。
结果:
第一个epoch依旧会长一些,但比未使用tf.data时还是快了很多:
第1个epoch:train_cost: 3.24916 // test_cost:1.05556
第2,3,4.....个epoch :train_cost:1.22807 // test_cost:0.69816(后面基本在这个数值附近保持很小的波动)
CPU:

GPU:利用率在45-70%之间周期浮动
PS: 理论每个任务的 num_parallel_calls 的设置和 prefetch()的设置都要根据具体情况来设定。上述实验仅证明了tf.data本身的加速效果。然而这两个参数的设定实测发现影响不大,原因是batch,数据量太小,也几乎没有前处理。
此时将image size改为256,GPU利用率稳定在了96%。但两个参数对训练速度影响仍不大:
- num_parallel_calls 不设置,prefetch(2)训练一轮时间12.15s,gpu利用率稳定96%。
- num_parallel_calls 不设置,prefetch(1)训练一轮时间11.47s,gpu利用率稳定96%。
- num_parallel_calls =6, prefetch(1)训练一轮时间11.40s。gpu利用率稳定96%。
- num_parallel_calls =6, prefetch(4)训练一轮时间11.44s。gpu利用率稳定96%。

实际上cpu只在每个epoch的load数据阶段利用率比较大。那么当前处理任务繁重时,是否可以调整cpu和gpu的工作量比例,达到最佳速度呢?
image size改为64(保证显存够),在decode_jpeg后,加入对image做10次翻转的前处理:
不设置num_parallel_calls :
for i in range(10):
image = tf.image.flip_up_down(image)- prefetch 不设置: train_cost:3.61072 GPU利用率 2-74%
- prefetch = 2: train_cost:3.39067 GPU利用率 2-61%
- prefetch = 3: train_cost:3.44768 GPU利用率 2-67%
- prefetch = 4: train_cost:3.36775 GPU利用率 2-61%
此时将num_parallel_calls 设置为6:
- prefetch 不设置: train_cost:2.61407 GPU利用率 2-78%
- prefetch = 2: train_cost:2.53957 GPU利用率 2-75%
- prefetch = 3: train_cost:2.54157 GPU利用率 2-74%
- prefetch = 4: train_cost:2.54957 GPU利用率 2-78%
- prefetch = 6: train_cost:2.51907 GPU利用率 2-71%
- prefetch = 10: train_cost:2.47456 GPU利用率 2-71%
- prefetch = 40: train_cost:2.24550 GPU利用率 1-74%
- prefetch = 80: train_cost:1.85542 GPU利用率 36-64%
- prefetch = 120: train_cost:1.61136 GPU利用率 56-61%
- prefetch = 240: train_cost:1.57235 GPU利用率 58-62%
- prefetch = 360: train_cost:1.58837 GPU利用率 59-62%
- prefetch = 480: train_cost:1.69238 GPU利用率 60-63%

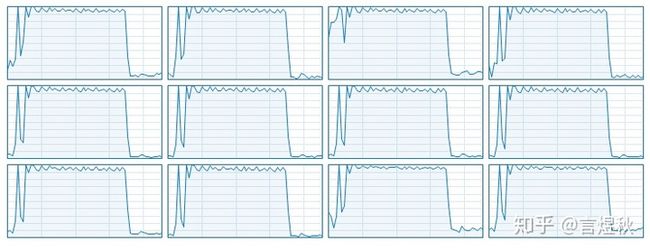
可以看出在prefetch=120时,根据图中CPU各个线程的利用率曲线跳变幅度,看出cpu的利用率已经比较稳定,不会在每个step都出现相对空闲(周期性突降)。
当cpu和gpu的并行程度较大时,可以发现gpu的利用率不仅不会周期跳变(实际上出现较低利用率时往往说明训练并行度很差, 会有较长时间停留在这个最低利用率上),随着最低利用率的上升,峰值利用率也会稍有降低,维持在一个小范围内波动。(这可能是gpu内部的并行因输入数据时域上的均匀而“节省”了峰值算力)
但要注意在前处理比较复杂的情况下,设置太大的prefetch会导致gpu运行完数据后,因cpu仍在预处理下一批数据而导致的gpu空闲。整体速度可能会不增反降。(prefetch=480时)
上述实验因网路太小,最后得到的最佳prefetch相对较大。实际训练时要根据各部分计算量比例权衡。
上文没有对比使用tf.image的速度提升,当前处理较复杂时可以考虑使用tf.image或者把前处理后的数据保存为TFrecord。
如果你的网络大小和batch size等参数由于任务原因已经固定,同时cpu性能较差,由于数据搬运造成的耗时始终达不到一个和gpu较好的平衡,且内存较大,可以考虑使用cache函数,将 dataset = dataset.cache('./cache.data')加在map函数前既可。
Pytorch训练加速
Dataloader
pytorch的框架Dataloader,封装了num_workers和pin_memory两个参数,只需要在原来使用基础上调整两个参数即可。
dataloader = DataLoader(
xxdataset,
batch_size=args.train_batchsize,
shuffle=True,
num_workers=args.workers,
drop_last=False,
pin_memory=False)num_workers:同理,增加子线程的个数,来分担主线程的数据处理压力,多线程协同处理数据和传输数据,不用放在一个线程里负责所有的预处理和传输任务。线程数的设置太大太小都会降低训练效率。num_wokers尽量设置为偶数。
pin_memory:当服务器或者电脑的内存较大,性能较好的时候,建议打开pin_memory,可以省掉了将数据从CPU传入到缓存RAM里面,再给传输到GPU上的时间。设置为True时则将数据直接映射到GPU的相关内存块上,节省了一些数据传输的时间。
在模型训练过程中,不只要关注GPU的各种性能参数,还需要查看CPU处理的怎么样。。但是对于CPU,不能一味追求超高的占用率。很多情况下CPU占用率很高,但时间主要用于加载和传输数据上。实际上很可能浪费了数倍的加载数据时间,当DataLoader的num_workers=0(default),或者不设置这个参数,会出现这个情况。
在一语义任务上实测发现,num_wokers设置为核心数时达到了最快训练速度,且GPU的利用率也稳定在了86-100%的状态。
未设置pin_memory:
- num_wokers = 0 ,训练10个step耗时:17.54s
- num_wokers = 1 ,训练10个step耗时:12.47s
- num_wokers = 2 ,训练10个step耗时:7.39s
- num_wokers = 4 ,训练10个step耗时:5.22s
- num_wokers = 6 ,训练10个step耗时:3.91s
- num_wokers = 8 ,训练10个step耗时:4.58s
在num_wokers = 6的基础上,打开pin_memory,耗时进一步降低到了3.88s。
torch.multiprocessing
torch.multiprocessing 是对 Python 的 multiprocessing 模块的一个封装,并且百分比兼容原始模块,也就是可以采用原始模块中的如 Queue 、Pipe、Array 等方法。并且为了加快速度,还添加了一个新的方法--share_memory_(),它允许数据处于一种特殊的状态,可以在不需要拷贝的情况下,任何进程都可以直接使用该数据。
通过该方法,可以共享 Tensors 、模型的参数 parameters ,可以在 CPU 或者 GPU 之间共享它们。
下面展示一个采用多进程训练模型的例子:
# Training a model using multiple processes:
import torch.multiprocessing as mp
def train(model):
for data, labels in data_loader:
optimizer.zero_grad()
loss_fn(model(data), labels).backward()
optimizer.step() # This will update the shared parameters
model = nn.Sequential(nn.Linear(n_in, n_h1),
nn.ReLU(),
nn.Linear(n_h1, n_out))
model.share_memory() # Required for 'fork' method to work
processes = []
for i in range(4): # No. of processes
p = mp.Process(target=train, args=(model,))
p.start()
processes.append(p)
for p in processes:
p.join()梯度累加实现超出显存的batch size
在你已经达到计算资源上限的情况下,你的batch size仍然太小(比如8),然后我们需要模拟一个更大的batch size来进行梯度下降,以提供一个良好的估计。
假设我们想要达到128的batch size大小。我们需要以batch size为8执行16个前向传播和向后传播,然后再执行一次优化步骤。
# clear last step
optimizer.zero_grad()
# 16 accumulated gradient steps
scaled_loss = 0
for accumulated_step_i in range(16):
out = model.forward()
loss = some_loss(out,y)
loss.backward()
scaled_loss += loss.item()
# update weights after 8 steps. effective batch = 8*16
optimizer.step()
# loss is now scaled up by the number of accumulated batches
Lightning
上述代码在lightning中,全部都给你做好了,只需要设置accumulate_grad_batches=16:
trainer = Trainer(accumulate_grad_batches=16)
trainer.fit(model)Lightning是在Pytorch之上的一个封装,它可以自动训练,同时可以完全控制关键的模型组件。
eg:为MNIST定义LightningModel并使用Trainer来训练模型。
from pytorch_lightning import Trainer
model = LightningModule(…)
trainer = Trainer()
trainer.fit(model)为了记录日志存储loss时,loss仍然包含有整个图的副本。在这种情况下,调用.item()来释放它:
losses.append(loss.item())Lightning会确保不会保留计算图的副本。
16-bit 精度
16bit精度是将内存占用减半的惊人技术。大多数模型使用32bit精度数字进行训练。然而,最近的研究发现,16bit模型也可以工作得很好。混合精度意味着对某些内容使用16bit,但将权重等内容保持在32bit。
要在Pytorch中使用16bit精度,请安装NVIDIA的apex库,并对你的模型进行这些更改。
# enable 16-bit on the model and the optimizer
model, optimizers = amp.initialize(model, optimizers, opt_level= O2 )
# when doing .backward, let amp do it so it can scale the loss
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()amp包会处理好大部分事情。如果梯度爆炸或趋向于0,它甚至会缩放loss。
在lightning中,启用16bit并不需要修改模型中的任何内容,也不需要执行我上面所写的操作。设置Trainer(precision=16)就可以了。
trainer = Trainer(amp_level= O2 , use_amp=False)
trainer.fit(model)参考
夕小瑶:训练效率低?GPU利用率上不去?快来看看别人家的tricks吧~
【Tensorflow】tf.data API使用方法
1. Tensorflow高效流水线Pipeline
tf.data学习指南(超实用、超详细)_我的博客有点东西-CSDN博客
TensorFlow tf.data 导入数据(tf.data官方教程) * * * * *
深度学习PyTorch,TensorFlow中GPU利用率较低,CPU利用率很低,且模型训练速度很慢的问题总结与分析_是否龍磊磊真的一无所有的博客-CSDN博客
鑫鑫淼淼焱焱:PyTorch系列 | 如何加快你的模型训练速度呢?
9个让PyTorch模型训练提速的技巧!_Evan-yzh的博客-CSDN博客