第四章 前馈神经网络
第四章 前馈神经网络
- 第四章 前馈神经网络
-
- 神经元
-
- Sigmoid 型函数
-
- Logistic函数
- Tanh函数
- Hard-Logistic 函数和 Hard-Tanh 函数
- ReLU 函数
-
- 带泄露的 ReLU
- 带参数的 ReLU
- ELU 函数
- Softplus 函数
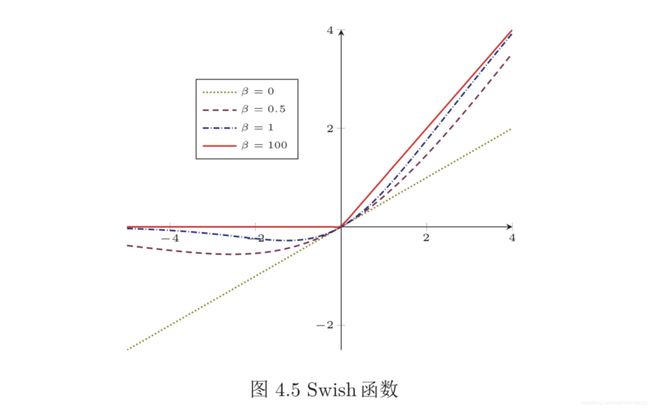
- Swish 函数
- 高斯误差线性单元
- Maxout 单元
- 网络结构
-
- 前馈网络
- 记忆网络
- 图网络
- 前馈神经网络
-
- 通用近似定理
- 应用到机器学习
- 参数学习
- 反向传播算法
-
- 使用误差反向传播算法的前馈神经网络训练过程可以分为以下三步:
- 自动梯度计算
-
- 数值微分
- 符号微分
- 自动微分
- 优化问题
-
- 非凸优化问题
- 梯度消失问题
- 总结和深入阅读
第四章 前馈神经网络
人工神经网络(Artificial Neural Network,ANN)是指一系列受生物学和 神经学启发的数学模型。这些模型主要是通过对人脑的神经元网络进行抽象,构 建人工神经元,并按照一定拓扑结构来建立人工神经元之间的连接,来模拟生 物神经网络。在人工智能领域,人工神经网络也常常简称为神经网络(Neural Network,NN)或神经模型(Neural Model)。
神经网络最早是作为一种主要的连接主义模型。20 世纪 80 年代中后期,最 流行的一种连接主义模型是分布式并行处理(Parallel Distributed Processing, PDP)模型 [McClelland 等人,1986],其有 3 个主要特性:(1)信息表示是分布式 的(非局部的)(;2)记忆和知识是存储在单元之间的连接上(;3)通过逐渐改变单 元之间的连接强度来学习新的知识。
连接主义的神经网络有着多种多样的网络结构以及学习方法,虽然早期模 型强调模型的生物可解释性(Biological Plausibility),但后期更关注于对某种特 定认知能力的模拟,比如物体识别、语言理解等。尤其在引入误差反向传播来改 进其学习能力之后,神经网络也越来越多地应用在各种机器学习任务上。随着训 练数据的增多以及(并行)计算能力的增强,神经网络在很多机器学习任务上已 经取得了很大的突破,特别是在语音、图像等感知信号的处理上,神经网络表现 出了卓越的学习能力。
在本章中,我们主要关注采用误差反向传播来进行学习的神经网络,即作为 一种机器学习模型的神经网络。从机器学习的角度来看,神经网络一般可以看作 是一个非线性模型,其基本组成单元为具有非线性激活函数的神经元,通过大量神经元之间的连接,使得神经网络成为一种高度非线性的模型。神经元之间的连 接权重就是需要学习的参数,可以在机器学习的框架下通过梯度下降方法来行学习。
神经元
人工神经元(Artificial Neuron),简称神经元(Neuron),是构成神经网络 的基本单元,其主要是模拟生物神经元的结构和特性,接收一组输入信号并产出 输出。
生物学家在 20 世纪初就发现了生物神经元的结构。一个生物神经元通常具 有多个树突和一条轴突。树突用来接收信息,轴突用来发送信息。当神经元所获 得的输入信号的积累超过某个阈值时,它就处于兴奋状态,产生电脉冲。轴突尾 端有许多末梢可以给其他个神经元的树突产生连接(突触),并将电脉冲信号传 递给其它神经元。
1943 年,心理学家 McCulloch 和数学家 Pitts 根据生物神经元的结构,提出 了一种非常简单的神经元模型,MP 神经元[McCulloch 等人,1943]。现代神经网 络中的神经元和 MP 神经元的结构并无太多变化。不同的是,MP 神经元中的激 活函数 f 为 0 或 1 的阶跃函数,而现代神经元中的激活函数通常要求是连续可导 的函数。

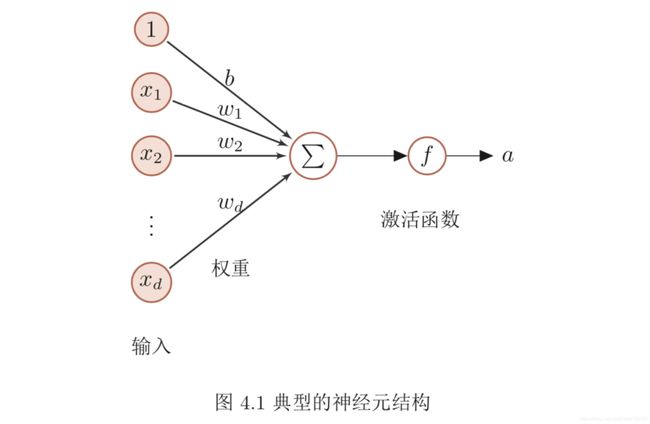

Sigmoid 型函数
Sigmoid 型函数是指一类 S 型曲线函数,为两端饱和函数。常用的 Sigmoid 型
函数有 Logistic 函数和 Tanh 函数。
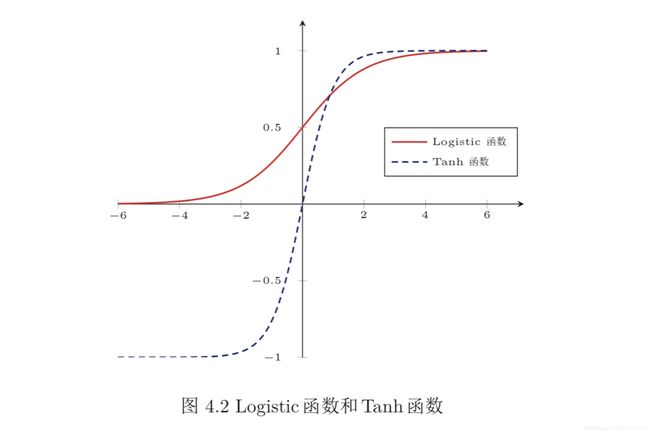
Logistic函数

Tanh函数

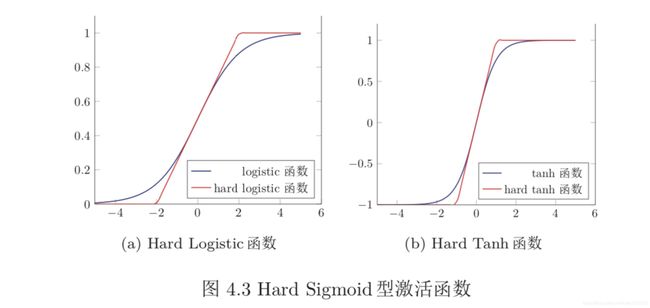
Hard-Logistic 函数和 Hard-Tanh 函数


ReLU 函数


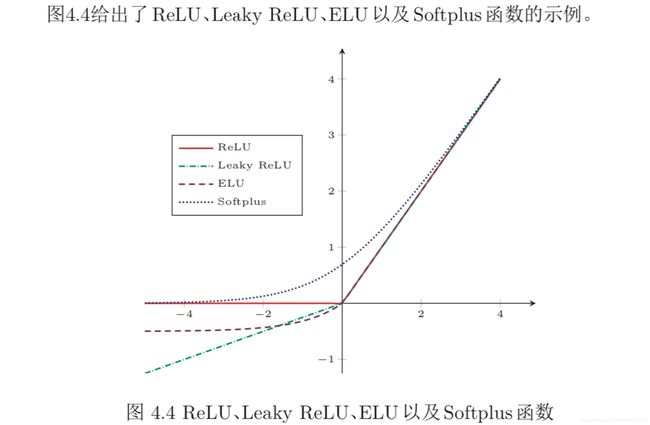
带泄露的 ReLU

带参数的 ReLU

ELU 函数

Softplus 函数

Swish 函数

高斯误差线性单元

Maxout 单元


网络结构
一个生物神经细胞的功能比较简单,而人工神经元只是生物神经细胞的理 想化和简单实现,功能更加简单。要想模拟人脑的能力,单一的神经元是远远不 够的,需要通过很多神经元一起协作来完成复杂的功能。这样通过一定的连接方 式或信息传递方式进行协作的神经元可以看作是一个网络,就是神经网络。
到目前为止,研究者已经发明了各种各样的神经网络结构。目前常用的神经 网络结构有以下三种:
前馈网络
前馈网络中各个神经元按接收信息的先后分为不同的组。每一组可以看作 一个神经层。每一层中的神经元接收前一层神经元的输出,并输出到下一层神经 元。整个网络中的信息是朝一个方向传播,没有反向的信息传播,可以用一个有 向无环路图表示。前馈网络包括全连接前馈网络 [本章中的第4.3节] 和卷积神经 网络 [第5章] 等。
前馈网络可以看作一个函数,通过简单非线性函数的多次复合,实现输入空 间到输出空间的复杂映射。这种网络结构简单,易于实现。
记忆网络
记忆网络,也称为反馈网络,网络中的神经元不但可以接收其它神经元的信 息,也可以接收自己的历史信息。和前馈网络相比,记忆网络中的神经元具有记 忆功能,在不同的时刻具有不同的状态。记忆神经网络中的信息传播可以是单向 或双向传递,因此可用一个有向循环图或无向图来表示。记忆网络包括循环神经 网络 [第6章]、Hopfield 网络 [第8.3.4.1节]、玻尔兹曼机 [第12.1节]、受限玻尔兹曼 机 [第12.2节] 等。
记忆网络可以看作一个程序,具有更强的计算和记忆能力。 为了增强记忆网络的记忆容量,可以引入外部记忆单元和读写机制,用来保
存一些网络的中间状态,称为记忆增强神经网络(Memory Augmented NeuralNetwork,MANN)[第8.3.3节],比如神经图灵机 [Graves 等人,2014] 和记忆网络[Sukhbaatar 等人,2015] 等。
图网络
前馈网络和记忆网络的输入都可以表示为向量或向量序列。但实际应用中 很多数据是图结构的数据,比如知识图谱、社交网络、分子(Molecular )网络等。 前馈网络和记忆网络很难处理图结构的数据。
图网络是定义在图结构数据上的神经网络 [第6.8.2节]。图中每个节点都由 一个或一组神经元构成。节点之间的连接可以是有向的,也可以是无向的。每个 节点可以收到来自相邻节点或自身的信息。
图网络是前馈网络和记忆网络的泛化,包含很多不同的实现方式,比如 图 卷积网络(Graph Convolutional Network,GCN)[Kipf等人,2016]、图注意力 网络(Graph Attention Network,GAT)[Veličković等人,2017]、消息传递网络
(Message Passing Neural Network,MPNN)[Gilmer等人,2017]等。 图4.6给出了前馈网络、记忆网络和图网络的网络结构示例,其中圆形节点
表示一个神经元,方形节点表示一组神经元。

前馈神经网络
给定一组神经元,我们可以以神经元为节点来构建一个网络。不同的神经网 络模型有着不同网络连接的拓扑结构。一种比较直接的拓扑结构是前馈网络。前馈神经网络(Feedforward Neural Network,FNN)是最早发明的简单人工神经网络。
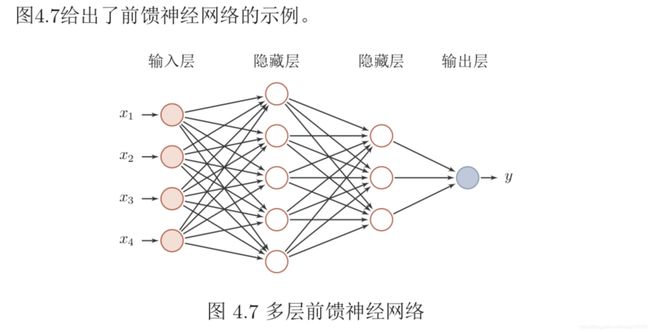
在前馈神经网络中,各神经元分别属于不同的层。每一层的神经元可以接收 前一层神经元的信号,并产生信号输出到下一层。第 0 层称为输入层,最后一层称为输出层,其它中间层称为隐藏层。整个网络中无反馈,信号从输入层向输出层单向传播,可用一个有向无环图表示。
前馈神经网络也经常称为多层感知器(Multi-Layer Perceptron,MLP)。但 多层感知器的叫法并不是十分合理,因为前馈神经网络其实是由多层的 Logistic 回归模型(连续的非线性函数)组成,而不是由多层的感知器(不连续的非线性 函数)组成 [Bishop,2007]。

通用近似定理
前馈神经网络具有很强的拟合能力,常见的连续非线性函数都可以用前馈 神经网络来近似。

通用近似定理在实数空间 Rd 中的有界闭集上依然成立。
根据通用近似定理,对于具有线性输出层和至少一个使用“挤压”性质的激 活函数的隐藏层组成的前馈神经网络,只要其隐藏层神经元的数量足够,它可 以以任意的精度来近似任何一个定义在实数空间 Rd 中的有界闭集函数 [Funa- hashi等人; Hornik等人,1993; 1989]。所谓“挤压”性质的函数是指像Sigmoid函 数的有界函数,但神经网络的通用近似性质也被证明对于其它类型的激活函数, 比如 ReLU,也都是适用的。
通用近似定理只是说明了神经网络的计算能力可以去近似一个给定的连续
函数,但并没有给出如何找到这样一个网络,以及是否是最优的。此外,当应用到 机器学习时,真实的映射函数并不知道,一般是通过经验风险最小化和正则化来 进行参数学习。因为神经网络的强大能力,反而容易在训练集上过拟合。
应用到机器学习


参数学习
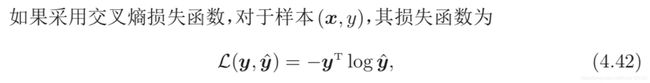


反向传播算法






使用误差反向传播算法的前馈神经网络训练过程可以分为以下三步:


自动梯度计算
神经网络的参数主要通过梯度下降来进行优化。当确定了风险函数以及网 络结构后,我们就可以手动用链式法则来计算风险函数对每个参数的梯度,并用 代码进行实现。但是手动求导并转换为计算机程序的过程非常琐碎并容易出错, 导致实现神经网络变得十分低效。实际上,参数的梯度可以让计算机来自动计 算。目前,主流的深度学习框架都包含了自动梯度计算的功能,即我们可以只考 虑网络结构并用代码实现,其梯度可以自动进行计算,无需人工干预,这样可以 大幅提高开发效率。
自动计算梯度的方法可以分为以下三类:数值微分、符号微分和自动微分。
数值微分


符号微分
符号微分(Symbolic Differentiation)是一种基于符号计算的自动求导方法。 符号计算也叫代数计算,是指用计算机来处理带有变量的数学表达式。这里的变 量看作是符号(Symbols),一般不需要代入具体的值。符号计算的输入和输出都 是数学表达式,一般包括对数学表达式的化简、因式分解、微分、积分、解代数方 程、求解常微分方程等运算。
自动微分
自动微分(Automatic Differentiation,AD)是一种可以对一个(程序)函数 进行计算导数的方法。符号微分的处理对象是数学表达式,而自动微分的处理对 象是一个函数或一段程序。自动微分可以直接在原始程序代码进行微分,因此自 动微分成为目前大多数深度学习框架的首选。
优化问题
非凸优化问题
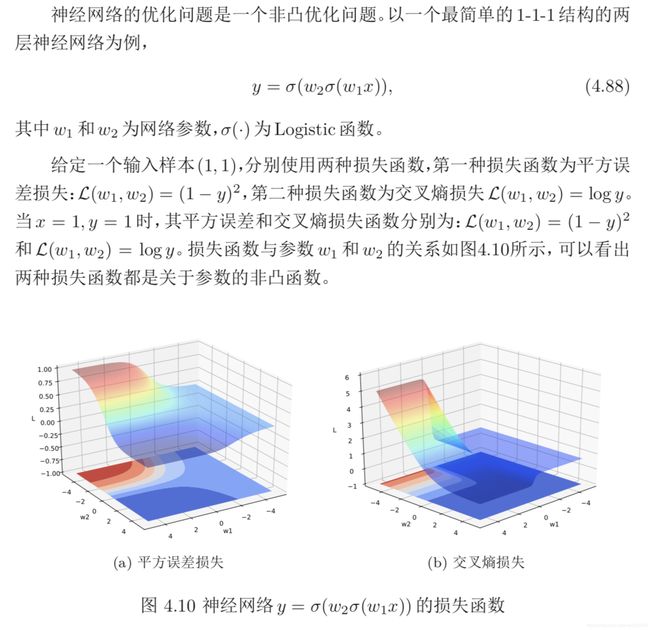
梯度消失问题

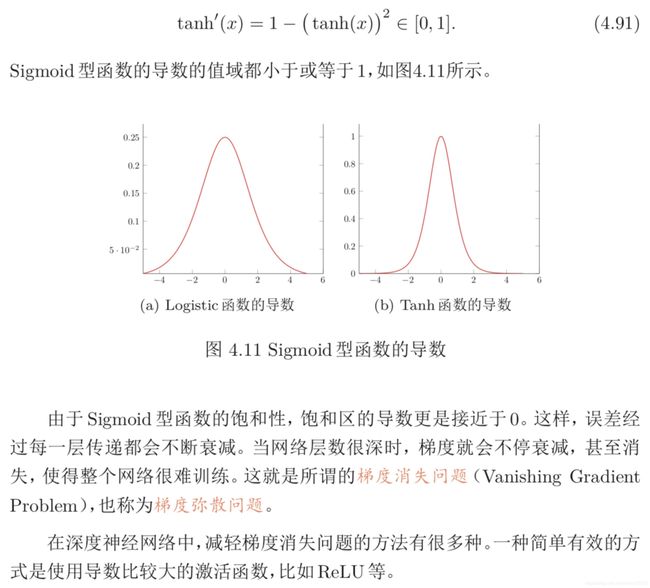
总结和深入阅读
神经网络是一种典型的分布式并行处理模型,通过大量神经元之间的交 互来处理信息,每一个神经元都发送兴奋和抑制的信息到其它神经元 [McClel- land 等人,1986]。和感知器不同,神经网络中的激活函数一般为连续可导函数。 表4.2给出了常见激活函数及其导数。在一个神经网络中选择合适的激活函数十 分重要。Ramachandran 等人[2017] 设计了不同形式的函数组合方式,并通过强 化学习来搜索合适的激活函数,在多个任务上发现 Swish 函数具有更好的性能。
本章介绍的前馈神经网络是一种类型最简单的网络,相邻两层的神经元之 间为全连接关系,也称为全连接神经网络(Fully Connected Neural Network, FCNN)或多层感知器。前馈神经网络作为一种机器学习方法在很多模式识别和 机器学习的教材中都有介绍,比如《Pattern Recognition and Machine Learning》 [Bishop,2007],《Pattern Classification》[Duda等人,2001]等。
前馈神经网络作为一种能力很强的非线性模型,其能力可以由通用近似定 理来保证。关于通用近似定理的详细介绍可以参考 [Haykin,2009]。
前馈神经网络在 20 世纪 80 年代后期就已被广泛使用,但是大部分都采用两层网络结构(即一个隐藏层和一个输出层),神经元的激活函数基本上都是 Sigmoid 型函数,并且使用的损失函数也大多数是平方损失。虽然当时前馈神经 网络的参数学习依然有很多难点,但其作为一种连接主义的典型模型,标志人工 智能从高度符号化的知识期向低符号化的学习期开始转变。
