zillow房价预测比赛_【干货】Kaggle实战记录——回归篇之房价预测

经过短短几个月的修炼之旅,机器学习的神秘面纱终于被我揭开了一层(还有一万层: D),作为横跨统计学,数学,计算机三门学科的领域,要想涉足其中自然对个人的综合能力来说是个不小的考验。趁着周末闲来无事,是时候写篇记录贴记录我的Kaggle首战比赛之旅了~
Kaggle是由联合创始人、首席执行官安东尼·高德布卢姆(Anthony Goldbloom)2010年在墨尔本创立的,主要为开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的平台。该平台已经吸引了80万名数据科学家的关注,这些用户资源或许正是吸引谷歌的主要因素。
Kaggle 绝大多数参赛选手都是用 Python 和 R 这两门语言的。因为我主要使用 Python,所以本文涉及到的步骤都是根据 Python 来实现的。好了闲话少说,让我们直接进入正文。
比赛的链接地址如下:
House Prices: Advanced Regression Techniques

由于这是个练习赛,如上图所示,我们的任务目标也很明确——根据多个feature来预测房价,概括起来无非就是一个字,准就完事儿了! : ) : )
一、数据预处理

拿到数据后我们需要做的第一件事就是看看数据长什么样,有哪些feature(在数学跟统计学里也可以称其为变量)可以用来做feature engineering,哪些feature需要筛选掉,由于会用到线性模型,所以得考虑多重共线性以及数据是否服从高斯分布等等一系列问题。
train.csv是我们要用来训练模型用的数据,除去其中的序号Id以及我们的target——SalePrice,总共有79个feautre,其中有36个是类别,43个是数值型。听起来是不是很多,没错,feature engineering就是最花时间但也是非常值得投入时间去做的环节,根据很多大神的经验来看,这一环节的性价比极高。所以feature engineering特别重要!!真的特别重要!!特别!!重要!!
借用 机器学习中,有哪些特征选择的工程方法? 里的一张图来大致描述下特征工程的框架
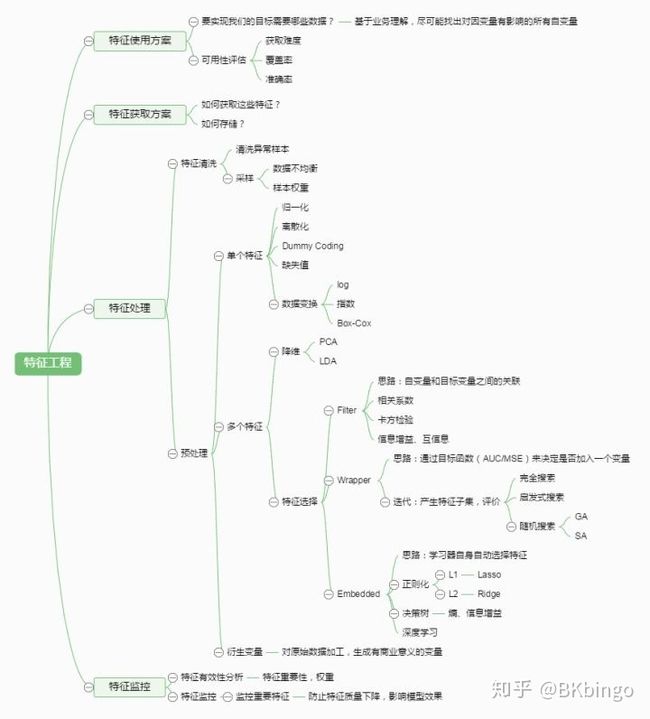
好了,看完之后,就让我们先迈出第一步吧
首先加载数据集
import pandas as pd
data_train = pd.read_csv('train.csv')
print(data_train.info())
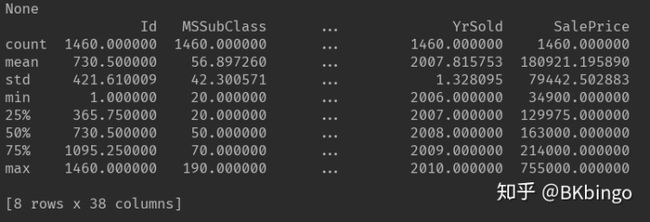
print(data_train.describe())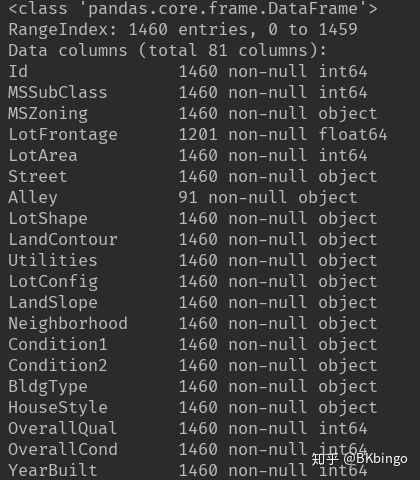
(其实可以用Jupyter Notebook来展示,原谅我的懒癌,就直接从pycharm里搬运好了)
首先从上述两个图我们得到如下两个信息:
1.观测到的数据是有缺失值的
2.数据的分布情况,例如均值,方差等
我们不妨合并train.csv跟test.csv这个测试集来进行一个整体的feature engineering,代码如下:
data_train = pd.read_csv('train.csv') # 加载数据
data_test = pd.read_csv('test.csv')
data_test_results = pd.read_csv('sample_submission.csv')
train_num = data_train.shape[0]
y_train = data_train.SalePrice
y_train = boxcox(y_train,0.5)
all_data = pd.concat((data_train, data_test)).reset_index(drop=True)
all_data.drop(['SalePrice','Id'], axis=1, inplace=True)其中all_data就是我们合并训练集跟测试集并去除Id跟Saleprice后得到的数据,之后进行一个非常简易(low)的特征处理。
特征工程的后续改进补充就先挖个坑,咱们好歹先把框架搭起来,有钢筋才能搭房嘛。
import numpy as np
import pandas as pd
from sklearn import preprocessing
from scipy.special import boxcox,inv_boxcox
def processing_data(X):
number_X = X.select_dtypes(exclude=object)
my_imputer = preprocessing.Imputer(strategy='mean')
new_number_X = my_imputer.fit_transform(number_X)
for i in number_X.columns:
if abs(number_X[i].skew()) > 0.75:
number_X[i] = boxcox(number_X[i], 0.5)
number_X = pd.DataFrame(new_number_X,columns=number_X.columns)
print('--------------------数字型特征已处理完毕--------------------')
category_X = X.select_dtypes(include=object)
for i in category_X.columns:
category_X[i] = category_X[i].fillna('noinfo')
print('--------------------类别特征已处理完毕--------------------')
X = pd.concat([number_X,category_X],axis=1)
return X
all_data=processing_data(all_data)
all_data=pd.get_dummies(all_data,drop_first=True)具体来说我这里进行了如下四个简易操作:
1.将数值型feature里的缺失值填补为他们每个featuer的均值
2.将数值型feature里skew(偏度)绝对值大于0.75的特征进行一个boxcox变换。没有听过boxcox也不要紧。。。其实这也不是个什么神秘的方法。。。因为当你去查它的公式会发现当λ=0时,它事实上就等价于log(x+1)变换(但此时python中应该用boxcox1p,它比boxcox多在x前加了个1),将非正态的数据修正为接近正态分布的数据,以便满足线性模型的需要。
3.将类别型feautre里的缺失值全部填补为“noinfo”,意思就是。。。呃。。。没有信息,是不是太随意了哈哈哈,这么随意的处理能拿高分才怪(滑稽脸)另外,机器学习领域有一句被传烂了的话叫做:特征工程决定了机器学习的上限,而算法和模型只是逼近这个上限。这句话并非人云亦云,而是非常值得重视的一句话(手动再次划重点)。
4.最后将类别型feautre变笨(手动滑稽)开个玩笑,get_dummies就是将类别变量向量化,比如这样
key1 key2
0 0 b
1 1 b
2 2 a
#get_dummies后key1不变,key2变为
key1 key2_a key2_b
0 0 0 1
1 1 0 1
2 2 1 0在get_dummies前我们来看看各feature之间的相关系数吧
def draw_corr_picture(X): # 绘制相关系数图
corrmat = X.corr()
plt.subplots(figsize=(12,12))
sns.heatmap(corrmat,vmax=0.9,square=True,cmap='Blues')
plt.show()
draw_corr_picture(all_data)
很明显GargeArea跟GarageCars两兄弟相关性这么高,那就直接剔除其中一个保留一个就好了,其他的也同理
类似的我们也可以把target——SalePrice加进来再绘制一张图,跟SalePrice相关性高的feature也统统做剔除处理~
接下来再看看各个feature分布,比如我们的目标值SalePrice的分布
import seaborn as sns
import matplotlib.pyplot as plt
sns.distplot(data_train.SalePrice)
plt.show()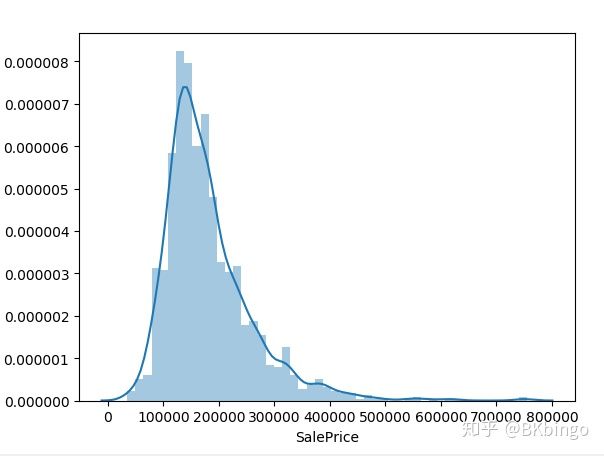
上图折线图是一个PDF(概率密度分布图),直方图则是一个频数直方图,y轴刻度优先取折线图的刻度。(可以在seaborn里调整参数来调整显示,强烈安利这个包,它是基于matplotlib的高级api)你会发现它是个右偏分布,貌似可以抢救一下成正态分布,于是我们来进行一下boxcox变换后再看。
data_train.SalePrice = boxcox(data_train.SalePrice,lmbda=0)
sns.distplot(data_train.SalePrice)
plt.show()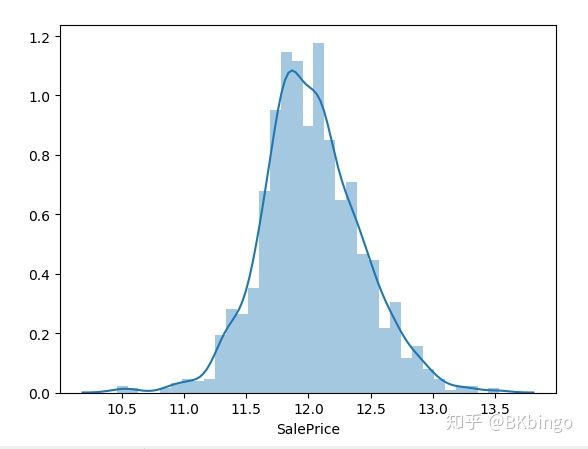
经过一个log(x+1)的修正让它端正了态度:)你是一个成熟的数据集了,该学会自己修正自己了。
二、模型选择
经过一系列操(zhe)作(teng)之后,原始数据勉强算是清洗处理完了,接下来就是最激动人心的撸basemodel的时刻了!
from xgboost import XGBRegressor
from sklearn.model_selection import GridSearchCV,RandomizedSearchCV,Kfold
from sklearn import preprocessing
from sklearn.metrics import mean_squared_log_error
import lightgbm as lgb
from sklearn.pipeline import make_pipeline
from scipy.special import boxcox,inv_boxcox
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor
from sklearn.svm import SVR
from sklearn.linear_model import Lasso,LassoCV,ridgeCV首先先导入一些必要的模块,比如模型,评估方法,交叉验证等
其次我们来利用调参神器GridsearchCV定义一个寻找最优参数的方法,其中RandomizedSearchCV是随机网格搜索,而GridsearchCV则是网格暴力搜索,随机的比较快,但准确性较差,暴力搜索的准确性较高,但耗时久,按需求不同可选择使用,但两者都容易陷入局部最优解,所以辅之以经验来调参会稳如皮皮虾:)。下面来演示下我常用的xgboost的调参示例。
按照以往经验将参数设置好一个范围,以dict的形式传递给GridsearchCV后让它来帮你检索最优参数,其中cv是交叉验证的折数,默认为3折,在这里我就设为常规的5吧。
下面为简易的搜索参数的小型示例代码,还可以将其内容扩充下,比如增加输出经过cross validation后(也就是交叉验证,简称cv)排名前十的参数等功能(见下图)。
def find_best_param(model):
xgb_param_test = {
'n_estimators': [300,400,500,600,700,800,900,1000,1500,2000,],
'max_depth': [ 3, 4, 5, 6, 7],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'min_child_weight': [0, 2, 5, 10, 20],
'max_delta_step': [0, 0.2, 0.6, 1, 2],
'subsample': [0.6, 0.7, 0.8, 0.85, 0.95],
'colsample_bytree': [0.5, 0.6, 0.7, 0.8, 0.9],
'reg_alpha': [0, 0.25, 0.5, 0.75, 1],
'reg_lambda': [0.2, 0.4, 0.6, 0.8, 1],
'scale_pos_weight': [0.2, 0.4, 0.6, 0.8, 1]
}
rfr_param_test = {
'n_estimators': [10,20,30,40,50,60,70,80],
'max_depth': [3, 4, 5],
}
#注意RandomizedSearchCV跟GridSearchCV的参数 param_distributions跟param_grid作用相同,但名字不同
#grid_search = RandomizedSearchCV(estimator=model, param_distributions=rfr_param_test, scoring='r2', cv=5)
grid_search = GridSearchCV(estimator=model, param_grid=rfr_param_test, scoring='r2', cv=5)
grid_search.fit(X_train,y_train)
print(grid_search.best_params_)
xgbreg = XGBRegressor()
find_best_param(xgbreg)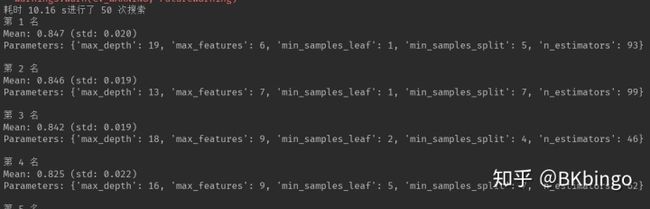
经过了漫长的等待时间,我们得到了局部最优解的参数,不敢说是全局最优解,具体原因请参考算法理论知识。这里强烈推荐两个coursera上的机器学习课程,一个是斯坦福大学的吴恩达(Andrew Ng)教授的公开课,另一个是台湾大学的林轩田教授的公开课。
偶然间发现B站上有人从coursera上搬运了他们俩的视频过来,真的是用B站来学习系列: )
机器学习(Machine Learning)- 吴恩达(Andrew Ng)
林轩田机器学习基石(国语)
机器学习技法(林轩田)
咳咳,安利时间结束,让我们来跑一跑所有basemodel看看效果怎么样
def rmsle(y, y_pred):
return np.sqrt(mean_squared_log_error(y, y_pred))
stacked_averaged_models = StackingAveragedModels(base_models=(gboost,krr),meta_model=lasso)
stacked_averaged_models.fit(X_train.values, y_train)
stacked_train_pred = stacked_averaged_models.predict(X_train.values)
stacked_test_pred = stacked_averaged_models.predict(X_test.values)
xgbreg1.fit(X_train, y_train)
xgb_train_pred = xgbreg1.predict(X_train)
xgb_test_pred = xgbreg1.predict(X_test)
lgbreg.fit(X_train, y_train)
lgb_train_pred = lgbreg.predict(X_train)
lgb_test_pred = lgbreg.predict(X_test)
rfr.fit(X_train,y_train)
rfr_train_pred = rfr.predict(X_train)
print('RFr与训练集答案相比的对数误差:{}'.format(rmsle(y_train, rfr_train_pred)))
print('LGBM与训练集答案相比的对数误差:{}'.format(rmsle(y_train, lgb_train_pred)))
print('Xgboost与训练集答案相比的对数误差:{}'.format(rmsle(y_train, xgb_train_pred)))
print('stackmodel与训练集答案相比的对数误差:{}'.format(rmsle(y_train, stacked_train_pred)))
ensemble_pred = 0.4*inv_boxcox(stacked_test_pred,0.5) + 0.3*inv_boxcox(xgb_test_pred,0.5) + 0.3*inv_boxcox(lgb_test_pred,0.5)
print('最终模型与测试集答案相比的对数误差:{}'.format(mean_squared_log_error(data_test_results.SalePrice,ensemble_pred)))首先我们先定义个rmsle函数以便比较每个模型的得分,由于该比赛分数是按MSLE(L就是取对数)来计算的,所以我们也按规矩来办,得分越小效果越好(也有可能是过拟合所以很小)

不幸的事发生了,我们的xgboost明显过拟合了,我们只能重新调参以及顺便再反复测试这些经不起风雨敲打的basemodel。
三、模型融合
根据大神们的经验,以及我的实际感受来看,想要拿到好的名次,模型融合是必不可少的一个环节。在这里我采取了先stacking后blending的方法融合得到我的最终模型。可能有的同学就发现了,前一个代码里的StackingModels是个什么玩意儿。它其实是我定义的一个类,将指定模型融合进去加工出一个最终模型,方法是根据stacking来构造的。
stacking简单介绍可以参考下
Kaggle机器学习之模型融合(stacking)心得
那么stacking用代码怎么实现呢,废话不多说,代码,来!
from sklearn.base import BaseEstimator,RegressorMixin,TransformerMixin,clone
from sklearn.model_selection import KFold
import numpy as np
import pandas as pd
class StackingModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, base_models, meta_model, n_folds=5):
self.base_models = base_models
self.meta_model = meta_model
self.n_folds = n_folds
def fit(self, X, y):
self.base_models_ = [list() for model in self.base_models]
self.meta_model_ = clone(self.meta_model)
kfold = KFold(n_splits=self.n_folds, shuffle=True, random_state=100)
"""
X_predictions为每个模型交叉预测后的联合矩阵,一开始初始化为0矩阵
"""
X_predictions = np.zeros((X.shape[0], len(self.base_models)))
for i, model in enumerate(self.base_models):
for train_index, holdout_index in kfold.split(X, y):
instance = clone(model)
self.base_models_[i].append(instance)
instance.fit(X[train_index], y[train_index])
y_pred = instance.predict(X[holdout_index])
X_predictions[holdout_index, i] = y_pred
self.meta_model_.fit(X_predictions, y)
return self
def predict(self, X):
meta_features = np.column_stack([
np.column_stack([model.predict(X) for model in base_models]).mean(axis=1) for base_models in self.base_models_])
return self.meta_model_.predict(meta_features)上述是一个根据sklearn包来自定义的一个转换器。(注意,如果添加BaseEstimator作为基类,__init__函数就不能接受 *args 和 **kwargs)在这里我们利用之前的Gboost跟核岭回归KRR模型作为基学习器丢进StackingModels,然后将lasso回归作为元学习器后得到最初版的stackingmodel。
再进行一个简单的blending之后,所有工作算是几乎接近尾声了
ensemble_pred = 0.5*inv_boxcox(stacked_test_pred,0.5) + 0.25*inv_boxcox(xgb_test_pred,0.5) + 0.25*inv_boxcox(lgb_test_pred,0.5)最后,导出预测文件
def outcsv():
result = np.column_stack((data_test_results.Id.astype(np.int32),ensemble_pred))
df=pd.DataFrame(result,columns=['Id','SalePrice'])
df['Id'] = df['Id'].astype(int)
pd.DataFrame.to_csv(df,'my_submission.csv',index=False)再去make submission,大功告成!但还不能得意太早,因为这个模型很粗糙,前期特征工程也做得还不够。让我们来看看结果
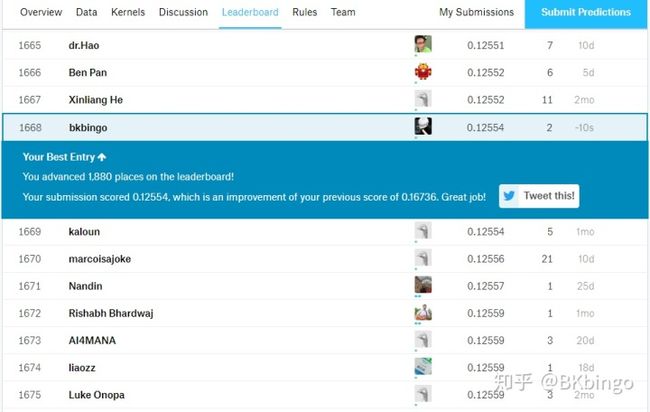
还行吧,没想象中那么糟糕,top35%的排名
再进行一系列调参后再次make submission
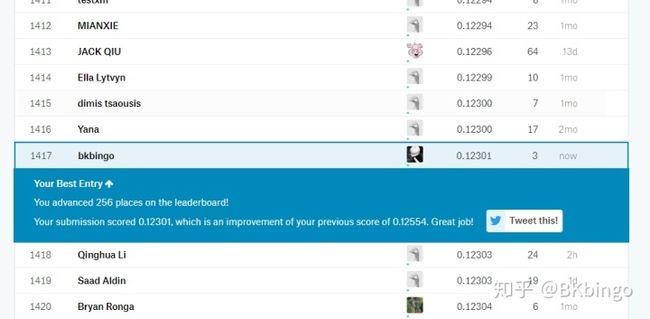
达到了top30%的成绩,好了,模型框架也有了,调参手段也几乎有了,难道就该止步于此吗?答案是NO!
是时候再返回特征工程阶段以及模型调参阶段进行大规模改造了。
四、重复并检查之前的环节
首先让我们来重新审视一遍解决机器学习问题的思维框架,看看问题出在哪儿
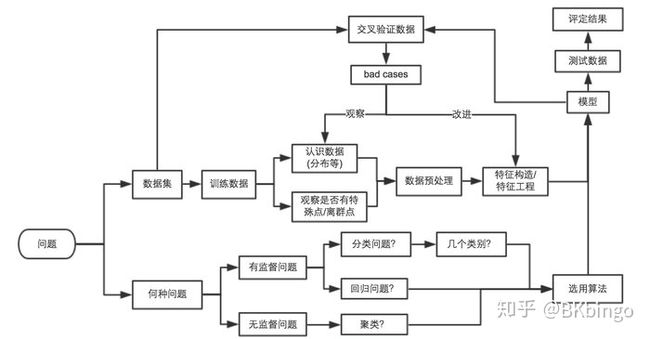
想要获得高分,必须反复推敲每一个环节,0.001分也是分,别看苍蝇虽小,但也是坨肉,就算硬挤也要给它挤出来。
那么如何才能把分挤上去呢?
我们先来看看之前非常随意的feature engineeringi环节(滑稽
这样处理显然是不行的,从模型上传后的PB得分就能看出来(PB是指public leaderboard,与此类似的还有个PV,private leaderboard,比赛结束后会使用PV得分作为最终得分,结束前都是使用PB得分,不同点在于PV是使用了PB的测试集的部分作为测试集)
那么怎样的处理才算是一套标准的处理方法呢?
回顾下之前的特征工程框架图,会发现之前的简易处理并没有处理到异常点(outliers),也并没有仔细检查类别特征是否有需要变为数值型的,或者数值特征是否需要变类别,更别说创建新特征了。经过前几天反复研读了kernel区各个大神的文章以及自己的思考,最后我总结出了如下的特征工程V2版。
outliers = [30,88,462,631,1322]
data_train=data_train.drop(data_train.index[outliers]).reset_index(drop=True)
train_num = data_train.shape[0]
y_train = data_train.SalePrice
y_train = boxcox1p(y_train,0)
all_data = pd.concat((data_train, data_test)).reset_index(drop=True)
all_data.drop(['SalePrice','Id'], axis=1, inplace=True)
def processing_data(X):
data = X
category_X = X.select_dtypes(include=object)
for i in category_X.columns:
category_X[i] = category_X[i].fillna('noinfo')
data['LotFrontage'] = data.groupby('Neighborhood')['LotFrontage'].transform(lambda x: x.fillna(x.median()))
data.select_dtypes(exclude=object).fillna(0)
number_X = data.select_dtypes(exclude=object)
skew_number_X = number_X.skew()
high_skew = skew_number_X[skew_number_X > 0.5]
need_boxcop_index = high_skew.index
for i in need_boxcop_index:
data[i] = boxcox1p(data[i],0)
data = data.drop(['Utilities', 'Street', 'PoolQC',], axis=1)
data['YrBltAndRemod']=data['YearBuilt']+data['YearRemodAdd']
data['TotalSF']=data['TotalBsmtSF'] + data['1stFlrSF'] + data['2ndFlrSF']
data['Total_sqr'] = (data['BsmtFinSF1'] + data['BsmtFinSF2'] + data['1stFlrSF'] + data['2ndFlrSF'])
data['Total_Bathrooms'] = (data['FullBath'] + (0.5 * data['HalfBath']) + data['BsmtFullBath'] + (0.5 * data['BsmtHalfBath']))
data['Total_porch_sf'] = (data['OpenPorchSF'] + data['3SsnPorch'] + data['EnclosedPorch'] + data['ScreenPorch'] + data['WoodDeckSF'])
data['haspool'] = data['PoolArea'].apply(lambda x: 1 if x > 0 else 0)
data['has2ndfloor'] = data['2ndFlrSF'].apply(lambda x: 1 if x > 0 else 0)
data['hasgarage'] = data['GarageArea'].apply(lambda x: 1 if x > 0 else 0)
data['hasbsmt'] = data['TotalBsmtSF'].apply(lambda x: 1 if x > 0 else 0)
data['hasfireplace'] = data['Fireplaces'].apply(lambda x: 1 if x > 0 else 0)
return data
all_data=processing_data(all_data)
print(all_data.shape)
all_data=pd.get_dummies(all_data,drop_first=True)
X_train = all_data[:train_num]
X_test = all_data[train_num:]新版的特征工程内容如下
1.找出异常点。绘制各特征之间的散点图,或者通过聚类的方法判断出训练集中异常点(这也会比较耗时间,可能以后再更新,先挖个坑)
index=[30,88,462,631,1322]的这几个点暂定为异常点,当然可能还有其他的点没找到
2.填补缺失值。老样子,将类别特征中缺失值填补为'noinfo'。别吐槽我:)数值型特征填补为0(注意,之前是填补为均值)。
3.删除特征。Utilities, Street, PoolQC将这三个特征删掉,Utilities里清一色的叫AllPub,只有一个家伙是NoSeWa,要你何用,删了~Street也是,清一色Pave,PoolQC更是,清一色的缺失值,你是来猴子派来的吗(手动滑稽
4.合并特征,比如Total_sqr= BsmtFinSF1+ BsmtFinSF2+ 1stFlrSF +2ndFlrSF,将后四个面积特征合并为总特征。2ndFlrSF,PoolArea,GarageArea,Fireplaces里大于1的统统归为“大于1”类
OK,搞定了,将data一波all in进定义好的processing_data方法中去,数据预处理就基本完成了。
经过了一下午的跑模型时间,新鲜参数终于出炉,在此期间发现随机森林的效果并不如其他基模型,于是最终选择把它剔除(可能它在这个数据集表现不是很好,但随机森林还是很好用的一个算法)
我的最终模型如下,经过了一个简单的blending
stacked_averaged_models = StackingModels(base_models=(ridge,lasso,svr),meta_model=lasso)
ensemble_train_pred = 0.7*inv_boxcox1p(stacked_train_pred,0) + 0.1*inv_boxcox1p(xgb_train_pred,0) +
0.1*inv_boxcox1p(lgb_train_pred,0)+0.1*inv_boxcox1p(gboost_train_pred,0)依照惯例,让我们来上传一下预测文件
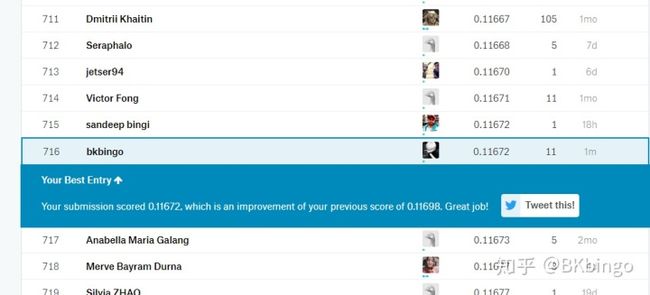

效果显著,一跃进16%,但仍旧不是我的理想成绩,但仍旧可以再次重复第四步骤进行回炉型思考。
经过思考总结,发现本次比赛模型明显的不足点有如下几点:
1.feature engineering没有再更深入的去做,只是粗略的过了一遍,完全可以再改进
2.各个base model的超参数还不是全局最优解,还可以再花点时间调调参
3.对可视化包如matplotlib跟seaborn运用得不充分(也可能是懒癌导致的,tableau呢?也懒得用:D
如还有其他不足以及错误之处,还望大家不吝赐教。(抱拳)
4.模型融合部分可以再细致一些
5.没有养成写pipeline的好习惯,不能记录下每次模型的分数及参数(说出来可能不信,我都是截图发微信文件传输助手来记忆的
6.也有可能是因为没有找队友组队集成多个模型,导致模型乏力(此处应甩锅给我的好友梅博 @白歌 (手动滑稽),赶紧来带我啊喂 )
好了,机器学习回归问题暂告一个段落,下一篇文章可能是分类问题,也有可能是朝着神经网络迈进~
此外
本人在此声明封面图是本人创作,与视觉中国无关!(玩个老梗哈哈哈
参考文章链接如下:
Stacked Regressions : Top 4% on LeaderBoard
如何在 Kaggle 首战中进入前 10%
机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾
GBDT、RF、SVM、XGBoost面试要点整理