CUDA计算
CUDA计算
- 一、GPU硬件架构综述
- 二、CUDA编程模型
-
- (1)逻辑层次上的执行流程
- (2)一些基础CUDA代码的认知
- 三、GPU内存
- 四、在GPU的计算部分如何运作?
-
- 流程粗略总结
- 五、常见GPU内存优化策略
-
- 1、最大化并行
- 2、极小化CPU与GPU数据传输
- 3、极大化使用共享内存
- 4、优化内存使用模式
- 5、程序注意性能可移植性
注明:由于编者知识有限,很多地方表述难免有欠妥当,仅供参考,这篇文章我会不定时更新
GPU并行计算引擎强大,可以大幅度加快计算速度,特别是稠密矩阵向量计算
一、GPU硬件架构综述
GPU设备常见5个指标:
1、核心芯片:直接决定了显卡性能的好坏
2、核心频率:核心工作频率,在同级别的芯片中,核心频率高的则性能要强一些,提高核心频率就是显卡超频的方法之一
3、显存位宽:显存在一个时钟周期内所能传送数据的位数,以 Bit 为单位
4、显存频率:默认情况下,该显存在显卡上工作时的频率,以MHz(兆赫兹)为单位
5、显存大小:主要是全局内存
参考资料:
详解GPU的常见参数及其对显卡的重要性
区分 DDR(内存)和 GDDR(显存)
想深入了解内存部分的可以看这些文章:
内存系列一:快速读懂内存条标签
内存系列二:深入理解硬件原理
内存系列三:内存初始化浅析
本文GPU示例:费米架构(Fermi)
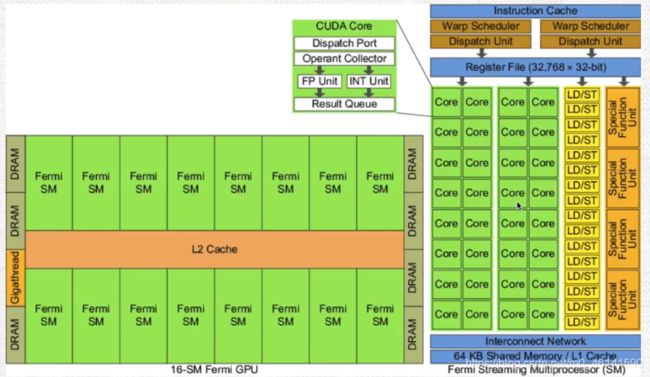
常见专业名词解释:
SPA:流处理器阵列(多个SM集合的Array)
TPC/GPC:流多处理器组成的块
SM:流多处理器( 包含内存单元、作业调度单元、流处理器 )
Cache:高速缓存(L1/L2/L3),一般不同级别速度不同,按优先级作用也不同
Core(SP): 流处理器,CUDA核心
Warp:线程束(基本执行单元)
在SM中重要的组成部分:
Warp Scheduler:线程调度器,可以按优先级执行Warp,切换Warp开销极小
RF:寄存器
SFU:特殊功能单元
Warp:集合固定数目的线程(32个)为一个Warp,作为最基本的执行单位,里面的线程执行相同的命令
所以该架构组成:16个SM + L2 Cache,其中每个SM有30个CUDA核心通过L1 Cache互联
参考资料:CUDA中grid、block、thread、warp与SM、SP的关系
你现在能看懂这副图了吗?

二、CUDA编程模型
GPU需要与CPU协同工作,所以GPU并行计算是指基于CPU+GPU的异构计算架构,它俩通过如图所示的 PCI总线 连接在一起,CPU部分称为 主机端(Host) ,GPU部分称为 设备端(Device)
由于 CPU上下文切换开销大(进程或线程切换),适合控制密集型任务,比如复杂的逻辑运算。
所以推荐使用CPU+GPU的异构计算平台,CPU负责逻辑复杂的串行程序,GPU负责数据密集型的并行计算程序
CUDA就是这样一个模型,既包含Host程序,又包含Device程序

(1)逻辑层次上的执行流程
Host端向Device端串行通讯,让Device端执行指定的核函数

在Device端,执行一个核函数(kernel)会启动很多thread,这些thread称为一个网格(grid),同一个grid上thread共享相同的local Cache,同时grid可以分为很多线程块(block),一个block包含很多thread,一般每32个thread一组称为线程束(warp)。
注意!warp才是执行计算的基本单位!
参考资料:对核函数(kernel)最通俗易懂的理解
(2)一些基础CUDA代码的认知
我们需要提前设置好核函数所需要的资源
下图是配置CUDA核函数计算的相关代码

grid 和 block 都是 dim3 类型的变量,包含维度信息,不同GPU架构下,维度会有所限制。
由于单个 SM 的资源有限,所以 block 中线程数有限,不易太多,目前强的设备可达1024个。
三、GPU内存
与 CPU 设计的三级缓存( L1\L2\L3 Cache )类似,根据读写的频率设立不同的内存分级,GPU是这样做的:

线程从全局内存读数据到共享内存,共享内存生命周期与线程相同,在结束时才放回结果到全局内存,这样可以大大提升访问效率
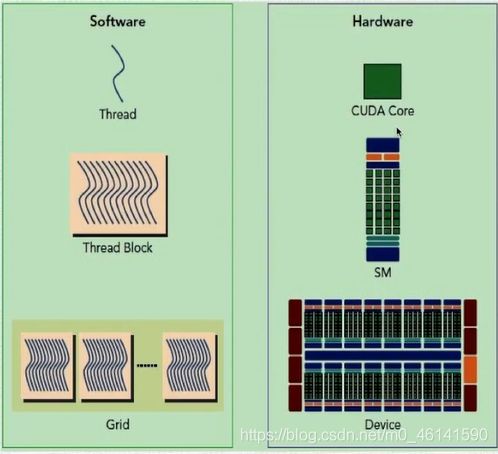
CUDA程序架构以及硬件映射
一个block只会由一个SM调度,block一旦被分配好SM,该block就会一直驻留在该SM中,直到执行结束。一个SM可以同时拥有多个block。
下图显示了 软件逻辑层次 和 硬件层次 都是类似于这种三级结构:
四、在GPU的计算部分如何运作?
当需要执行一个kernel时,会自动形成grid,其中的thread block会被分配到SM上,一个thread block只能在一个SM上被调度,SM中的warp调度器会调度thread block中的线程成束使用(一般是32个Thread),于此,SM可以并发地执行数百个线程,并发能力取决于SM所拥有的资源数
流程粗略总结
1、执行kernel,形成grid
2、调度、分配资源 (thread block分配到SM,等待warp scheduler 调度,SM准备资源)
3、形成warp (thread block中的线程以32个为一组被成束使用)
4、并发执行
需要注意的:
1、可能一个kernel的各个线程块被分配到各个SM,所以grid只是逻辑层,SM才是真正执行的物理层
2、GPU规定warp中所有线程在同一周期执行相同的执行,warp分化会导致性能下降
3、保证每个warp执行命令相同(避免分支流向),内存和线程对齐,不要并发太多的线程束避免对SM资源的浪费
五、常见GPU内存优化策略
数量级 : 10G/s
GPU内存访问带宽,可达到3~4个数量级
瓶颈位于PCI总线,可能只有1个数量级
CPU内存访问带宽大概在2~3个数量级

1、最大化并行
算法设计并行性多一些而不是串型
2、极小化CPU与GPU数据传输
降低CPU和GPU的内存传输,使用尽可能少的通讯次数
3、极大化使用共享内存
尽可能使用共享内存而不是全局内存
重点!GPU规约算法
4、优化内存使用模式
全局内存:最好对齐访问,在特定条件下做合并访问
共享内存:避免bank数据的冲突
5、程序注意性能可移植性
尽量使用更多的计算而不是内存访问,同时也可以保证在更强的GPU上运行程序性能的移植
对于多屏操作,建议显示与纯计算功能分到不同显卡上运行,即便显示所需要的资源很小
最后引用一段问答:
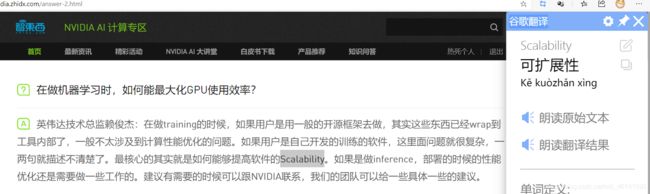
所以建议第一步是明确在硬件层面是否能尽可能最大化利用GPU资源了,再考虑计算性能的优化