卷积神经网络
文章目录
-
- 什么是卷积神经网络(CNN)
- 卷积的基本定义
- 卷积层
- Pad
- 池化层
- 激活层
- BatchNorm层
- 全连接层
- Dropout层
- 常见的卷积神经网络结构
什么是卷积神经网络(CNN)
以卷积结构为主,搭建起来的深度网络(一般都指深层结构的)
CNN目前在很多很多研究领域取得了巨大的成功,例如: 语音识别,图像识别,图像分割,自然语言处理等。对于大型图像处理有出色表现。
一般将图片作为网络的输入,自动提取特征,并且对图片的变形(平移,比例缩放)等具有高度不变形
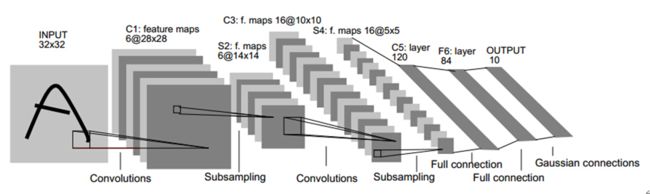
(图片来源于网络,侵删)
上图是手写识别的卷积神经网络模型,我们可以发现卷积神经网络的重要组成部分:
卷积层、池化层、激活层、BN层、LOSS层、其它层
卷积的基本定义
卷积就是一种运算,是对图像和滤波矩阵做内积(逐个元素相乘再求和)的操作。
每一种卷积对应一种特征。
其中滤波矩阵在深度学习中,我们称之为卷积核。换句话说,我们一般可以将卷积看成滤波器。比如我们可以通过滤波器对图像进行降噪,图像的噪点就是高频信号。
在图像处理中,有很多滤波器可以供我们选择。每一种滤波器帮助我们提取不同的特征。比如水平/垂直/对角线边缘等等。
可以看这篇回答,挺通俗易懂的。
卷积层
卷积的核心是卷积核,核就是一组权重,它决定了一个像素点如何通过周围的其他像素点计算获得新的像素点数值。核也被称之为卷积矩阵,它会对一块区域的像素做调和运算或卷积运算。
一般最常用为2D卷积核(k_w * k_h),如 1x1,3x3, 5x5, 7x7
卷积核的数值都是奇数,因为奇数的卷积核有一个中心点
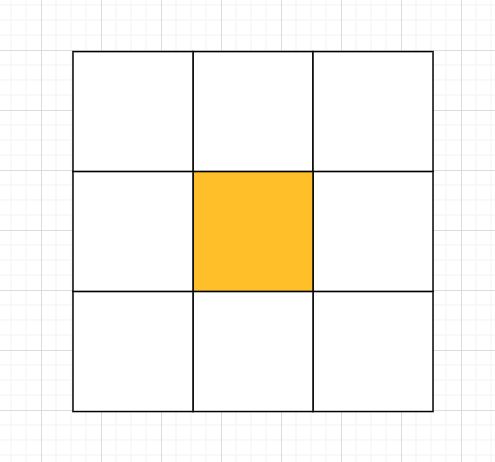
我们可以利用有中心点的特性来保护图片位置信息,padding时对称。
大家感兴趣可以看看这篇文章。
卷积还具有 权值共享 与 局部连接(局部感受野/局部感知)的特性。
在卷积层中权值共享是用来控制参数的数量。假如在一个卷积核中,每一个感受野采用的都是不同的权重值(卷积核的值不同),那么这样的网络中参数数量将是十分巨大的。
那么感受野是什么?感受野是卷积神经网络每一层输出的特征图(Feature Map)上的像素点在原始图像上映射的区域大小。
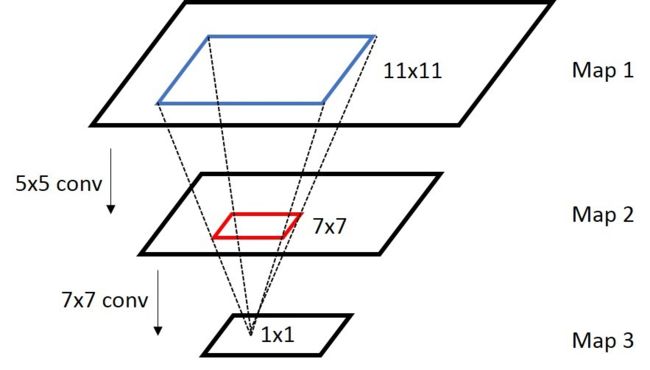
(图片来源于网络,侵删)
神经网络中,卷积核越大,虽然感受野越大,但参数越多,结构就越复杂,越容易过拟合。另一方面,需要更多的数据来训练,训练的难度也会更大。所以一般我们采用小卷积核堆加的方式来,保证感知野尽量大,同时结构尽可能简单,降低计算量。
Pad
pad可以让你的输入图像不变小,而可以使用更深层的卷积.确保Feature Map整数倍变化,对尺度敏感的任务非常重要.
池化层
池化层的作用是对输入的特征图错开行或列,压缩特征图大小,降低参数量和计算复杂度,也对特征进行了压缩,提取主要特征,将语义相似的特征融合起来,对微小的平移和形变不敏感。包括平均池化和最大池化和随机池化,平均池化领域内方差小,更多的保留图像的背景信息,最大池化领域内均值偏移大,更多的保留图像的纹理信息,随机池化(Stochastic Pooling)则介于两者之间。
值得注意的是:池化层是无参的。
池化层相较于卷积层相对简单许多。如果图像太大的时候,就需要减少训练参数的数量,池化层须在随后的卷积层之间周期性地被引进。池化的直接目的是为了减少图像的空间大小。池化在每一个纵深维度上独自完成,因此图像的纵深保持不变。取一小块区域,比如一个55的方块,如果是最大值池化,那就选这25个像素点最大的那个输出,如果是平均值池化,就把25个像素点取平均输出。这样在原来55的一个区域,现在只要一个值就能表示出来了。池化操作可以看做是一种强制性的模糊策略,不断强制模糊增加特征的旋转不变性。这样当图片无论如何旋转时,经过池化之后结果特征都是近似的。
激活层
激活函数(Activation Function): 如果一旦将线性分量运用于输入,就会需要运用一个非线性函数来组合实现达到任意函数的目的。激活函数能将输入信号转换为输出信号。形如f(x * W+ b)就是应用激活函数后的输出看起来的样子,其中f()就是激活函数。如图(添加激活函数后的神经元模型):
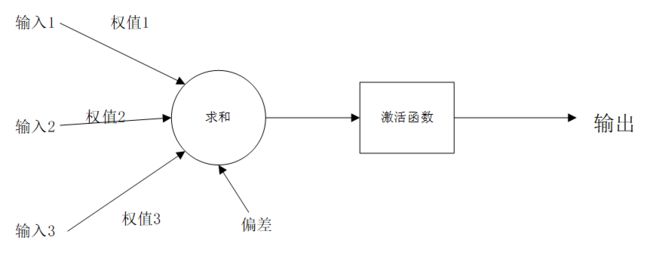
通俗点讲:激活函数 增加网络的非线性,进而提高网络的表达能力
基本的常见激活函数有Sigmoid,ReLU和Softmax,下面简单介绍一下:
1)Sigmoid:
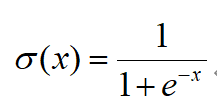
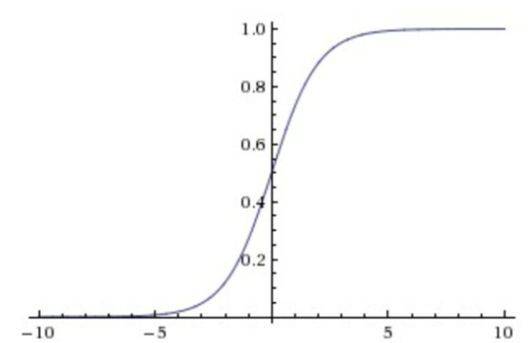
它会将输入的数值压缩到0到1范围内,比较适合输出需求为概率的情况。但它在神经元的激活在接近0或1处时会饱和,在这些区域时的梯度几乎为0,这就会导致梯度消失,这就会导致几乎没有信号能通过神经传回上一层神经层。
Sigmoid函数的输出不是以零为中心的。如果是以零为中心的话,假设输入神经元的数据总是为正数的话,那么关于w的梯度在反向传播的过程中,将会出现一种情况:要么全是正数,要么全是负数,这就会导致梯度下降,权重更新时,出现形如“Z”字型的下降。
下图: Sigmoid的函数图像
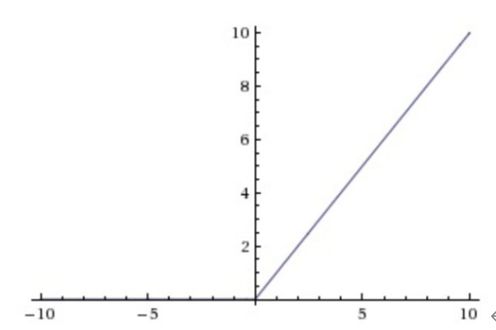
2)ReLU:
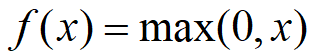
与Sigmoid激活函数相比的它具有的独特性是:单侧抑制的特性和稀疏激活性。保留了step函数的生物学启发(只有输入超出阀值时神经元才会被激活)
相较于Sigmoid激活函数,ReLU激活函数能够巨大地加速随机梯度下降的收敛的速度;但由于ReLU单元比较脆弱,可能导致数据多样性的丢失,且过程是不可逆的。所以使用时,需要谨慎。
3)Softmax:
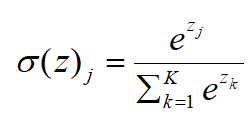
Softmax激活函数通常用于输出层,一般用于问题的分类。与Sigmoid激活函数相比,输出被归一化的总和为1是唯一的区别,其他就很类似。Sigmoid激活函数会阻止有二进制输出,当遇到一个多类分类问题,Softmax激活函数会简单化为每个类分配值的过程。
BatchNorm层
通过归一化将数据分布拉回标准正态分布,使得梯度一直处于比较大的状态;同时如果直接归一化为均值为0方差为1的标准正太分布,就抹掉了前面学习的非线性表达能力,因此在batchnorm的实现过程中,增加了平移和缩放参数。保留了非线性。
BatchNorm层的优点:
-
减少了参数的人为选择,使得调参更容易
-
初始化要求也没那么高,减少了对学习率的要求,可以使用更大的学习率;
-
降低了数据之间的绝对差异,有去相关的作用,更多考虑相对差异,有利于分类;
-
BN是一种正则,可以代替dropout,取消L2正则项参数,或者采取更小的L2正则项约束参数。
-
BN本身就是归一化网络,一定程度上可以缓解过拟合,解决梯度消失问题。
全连接层
全连接层将学到的“分布式特征表示”映射到样本标记空间。它是在整个卷积神经网络中起到“分类器”的作用,将二维空间转化成一维向量,将全连接层的输出送入分类器或回归器来做分类和回归。
Dropout层
Dropout(随机失活正则化),是一种正则化方法,通过对网络某层的节点都设置一个被消除的概率,之后在训练中按照概率随机将某些节点消除掉,以达到正则化,降低方差的目的。
Dropout层可以解决过拟合问题,取平均的作用,减少神经元之间复杂的共适应关系
常见的卷积神经网络结构
LeNet、AlexNet、ZFNet、VGGNet、Inception和ResNet和轻量型卷积神经网络等等(这里就不展开讲了,太多了,感兴趣自行研究)
卷积的概念展开来讲还是太多太深奥了,数学公式一大堆,小牛这段时间就简单学习比较常见的部分,有些原理明白但无法用直白的语言写出来,这部分写的很吃力也不知道该写些什么,就把笔记和以前写的论文部分贴了贴。后面会尽快进入代码部分。(这部分写起来快自闭了- -)
参考:
《深度学习模型微服务化管理系统的设计与实现》
https://mlnotebook.github.io/post/CNN1/
https://zhuanlan.zhihu.com/p/47184529
https://blog.csdn.net/baidu_27643275/article/details/88711329
https://zhuanlan.zhihu.com/p/106142812
本篇文章到这里就结束啦,如果喜欢的话,多多支持,欢迎关注!
