最新最全GPT-3模型网络结构详细解析
最近,GPT3很火,现在有很多讲GPT-3的文章,比如讲解它可以做什么, 思考它的带来的影响, 可视化其工作方式。看了这些文章并不足以详细了解GPT-3模型,仍然需要认真研究相关论文和博客。
因此,本文主要目标:帮助其他人对GPT-3体系结构有一个尽可能详细的了解。
原始模型
首先,原始的Transformer和GPT模型的网络结构如下图所示:


上图详细描述了GPT-3网络结构基础,要深入学习其网络结构,仍需进一步深入研究。
输入与输出
在了解其他内容之前,我们需要知道:GPT的输入和输出是什么?
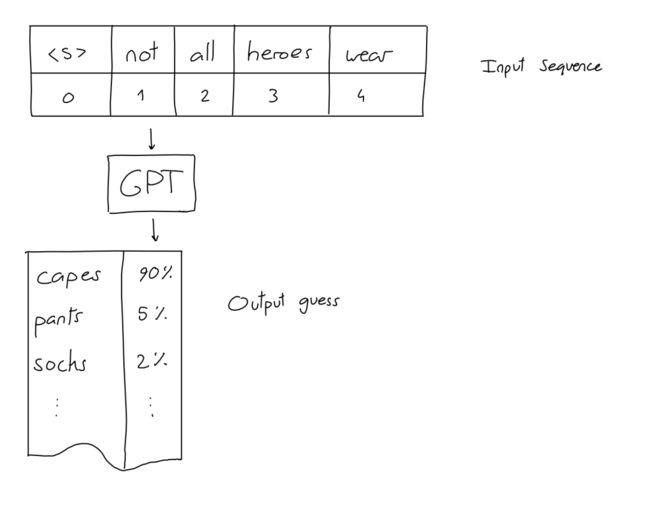
输入是N个单词(也称为Token)的序列。输出是对最有可能在输入序列末尾放置的单词的预测。
所有基于GPT模型的应用,如对话,故事和示例生成,都是通过这种简单的输入输出方案实现的:给它一个输入序列–得到下一个单词。比如:
并非所有英雄都穿 -> 斗篷
当然,我们经常想得到一个以上的多个单词,但这不是问题:得到下一个单词后,将其添加到序列中,得到下一个单词。比如:
并非所有英雄都披着斗篷 -> 但
并非所有英雄都披着斗篷 ,但-> 全部
并非所有英雄都披着斗篷,但全部 -> 恶棍
并非所有英雄都披着斗篷,但全部恶棍 -> 做
重复所需的次数,最终得到需要的长文本。
实际上,确切地说,以上说法有两点需要纠正。
1.输入序列实际上固定在2048个字(对于GPT-3)以内。仍然可以将短序列作为输入:只需用“空”值填充所有额外位置。
2. GPT输出不仅是一个预测(概率),而是一系列预测(长度2048)(每个可能单词的概率)。序列中每个“next”位置都是一个预测。但是在生成文本时,通常只查看序列中最后一个单词的预测。
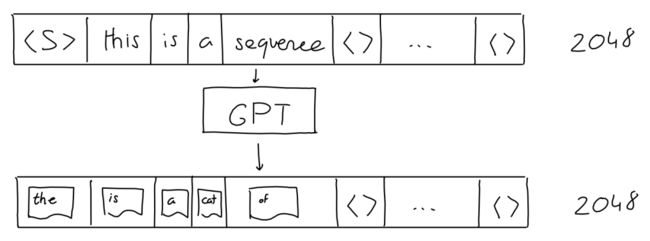
如上图所示。顺序输入,顺序输出。
编码
但是请稍等,GPT实际上无法理解单词。作为一种机器学习算法,它可以对数字向量进行运算。那么我们如何将单词变成向量呢?
第一步是将所有单词收集在一起构成词汇表,这使我们能够为每个单词赋予一个值(id)。Aardvark是0,aaron是1,依此类推。(GPT的词汇表包含50257个单词)。
最终,我们可以将每个单词转换为大小为50257的单点编码矢量,其中仅索引i处的维(单词的值)为1,所有其他维度均为0。

当然,我们对序列中的每个单词都执行此操作,

结果是一个2048 x 50257的1和0矩阵。
注意:为了提高效率,GPT-3实际上使用字节级(byte-level)字节对编码(BPE)进行Token化。这意味着词汇表中的“单词”不是完整的单词,而是经常在文本中出现的字符组(对于字节级BPE,字节)。使用GPT-3字节级BPE Token生成器,将“Not all heroes wears capes”分成Token输入“ Not”,“ all”,“ heroes”,“ wear”,“ cap”,“ es”,其ID为3673、477、10281,词汇中的5806、1451和274。 (https://huggingface.co/transformers/tokenizer_summary.html)详细介绍了bpe原理,以及github实现,也可以自己尝试。
向量化
50257对于矢量来说相当大,并且大部分都用零填充。那是很多浪费的空间。
为了解决这个问题,模型学习了一个embedding函数:一个神经网络,该神经网络采用50257长度的1和0的向量,并输出n长度的数字的向量。在这里,模型试图将单词含义的信息存储(或投影)到较小的空间中。
例如,如果embedding维数为2,就好比将每个单词存储在2D空间中的特定坐标处。

另一种直观的思考方式是,每个维度都是虚构的属性,例如“softness”或“ shmlorbness”,并且为每个属性赋予一个值,我们就可以准确知道哪个词是什么意思。
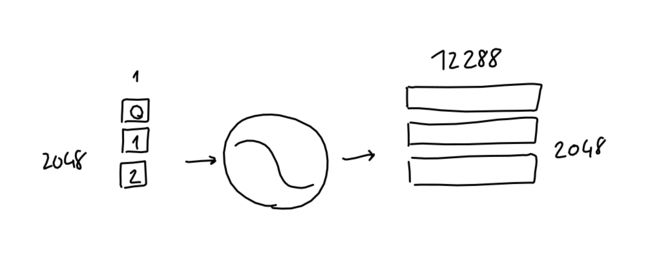
当然,embedding尺寸通常大于2:GPT使用12288尺寸。
在实践中,每个单词one-hot表示都与学习的embedding网络权重相乘,最终得到12288维embedding向量。
用算术术语来说,我们将2048 x 50257序列编码矩阵与50257 x 12288 embedding权重矩阵(已学习)相乘,最后得到2048 x 12288序列embedding矩阵。

从现在开始,将绘制二维矩阵,将其作为小小的块,并在其旁边标注尺寸。如果适用,将矩阵行分开以明确表示每一行对应于序列中的一个单词。
还要注意,由于矩阵乘法计算法则限制,所以将embedding函数(又称embedding权重矩阵)分别应用于每个单词编码(即序列编码矩阵中的行)。换句话说,结果与将每个单词编码向量分别传递给embedding函数并在最后将所有结果串联在一起是相同的。这意味着什么:此过程最终,没有信息流过整个序列,也没有关于Token的绝对或相对位置的信息。
位置信息编码(Positional Encoding)
为了对当前Token在序列中的位置进行编码,作者采用了Token的位置(标量i,在[0-2047]中),并将其传递给12288个正弦函数,每个函数的频率都不同。
![]()
其实,为何如此有效的确切原因尚不完全清楚。作者将其解释为产生许多相对位置编码,这对于模型很有用。对于其他可能的模型来分析此选择:考虑通常将信号表示为周期性样本之和的方式(请参见傅立叶变换或SIREN网络体系结构),或者语言自然呈现各种长度的循环的可能性(例如诗歌) 。
对于每个Token,结果是12288个数字向量。与embedding一样,将这些向量组合成具有2048行的单个矩阵,其中每一行是序列中Token的12288列位置编码。
最后,可以简单地将具有与序列embedding矩阵相同形状的该序列位置编码矩阵添加到该矩阵中。

注意力机制(基础版本)
简而言之,Attention的目的是:对于序列中的每个输出,预测输入标记对输出影响程度。在这里,想象一个由3个Token组成的序列,每个Token都由512个值的embedding表示。
该模型学习3个线性投影,所有这些投影都应用于序列embedding。换句话说,学习了3个权重矩阵,这些矩阵将我们的序列embedding转换为3个单独的3x64矩阵,每个矩阵分别用于不同的任务。
![]()
前两个矩阵(“queries”和“keys”)相乘(QK T),得出3x3矩阵。该矩阵(通过softmax归一化)表示每个Token相对于其他Token的重要性。
注意:此(QK T)是GPT作用于输入序列的唯一操作。这也是矩阵行交互的唯一操作。
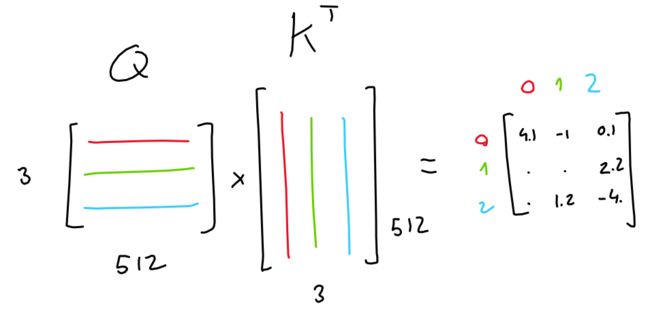
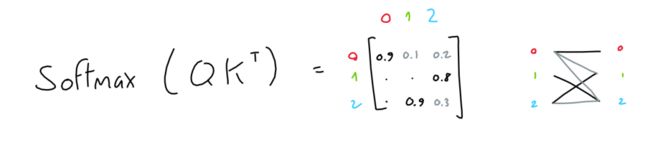
第三个矩阵(“值”)与该重要性矩阵相乘,从而为每个Token生成所有其他Token值的混合(按其各自Token的重要性加权)。
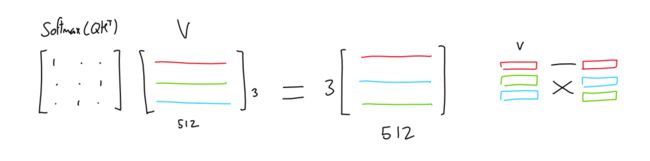
例如,如果重要性矩阵只有一个和零(每个Token只有一个重要的其他Token),则结果就像在值矩阵中选择基于哪个Token最重要的行。
其实,这至少有助于理解注意力的计算过程,而不是凭直觉来理解。
多头注意力机制
现在,在作者提出的GPT模型中,他们使用了多头注意力。所有这些意味着,上述过程被重复了很多次(GPT-3中为96x),每个过程都有不同的可学习的query,key,value投影权重。
每个attention head的结果(单个2048 x 128矩阵)被串联在一起,产生2048 x 12288矩阵,然后将其乘以线性投影(不会改变矩阵形状),以达到良好的效果。

注意:本文提到GPT-3使用稀疏注意力,这使得计算效率更高。老实说,我没有花时间确切地了解它是如何实现的。
前馈
前馈部分是一个具有1个隐藏层的传统的多层感知器。进行输入,与学习的权重相乘,添加学习的偏差,再次进行,以获得结果。
此处,输入和输出形状都相同(2048 x 12288),但是隐藏层的大小为4 * 12288。

需要明确的是:我也将此操作绘制为一个圆,但是与体系结构中其他学习的投影(embedding,query/key/value投影)不同,此“圆”实际上由两个投影组成(学习加权矩阵乘以输入)连续添加学习偏见,最后经过ReLU激活。
Add和Norm
在“多头注意力”和“前馈”模块之后,该模块的输入将添加到其输出中,并对结果进行归一化。这在深度学习模型中很常见(自ResNet起)。

注意:在我的任何草图中都没有反映出以下事实:自GPT-2起,“layer归一化已移至每个子模块的输入,类似于激活前的残留网络,并且在最终层之后添加了附加的层归一化自我注意模块”
解码
通过所有96层GPT-3的注意力/神经网络机制后,输入数据已处理为2048 x 12288矩阵。对于该序列中的2048个输出位置中的每一个,该矩阵都应包含一个12288个向量的信息,其中应显示哪个单词。但是我们如何提取这些信息?
如果你还记得“embedding”部分,我们学习了一种映射,该映射将给定(一个字的单次编码)的单词转换为12288个向量的embedding。事实证明,我们可以反转此映射以将输出的12288向量矢量embedding转换回50257字编码。这个想法是,如果我们花所有的精力学习从单词到数字的良好映射,那么我们不妨重新实用它!

当然,这样做不会像开始时那样给我们零和一的东西,但这是一件好事:在快速softmax之后,我们可以将结果值视为每个单词的概率。
此外,GPT论文还提到了参数top-k,该参数将输出中要采样的可能单词的数量限制为k个最可能的预测单词。例如,当top-k参数为1时,我们总是选择最可能的单词。
整体架构
整个网络结构:一些矩阵乘法,一些代数,而且也拥有最先进的自然语言处理能力。我已将所有零件绘制到一个原理图中,单击以查看完整版本。
