TensorFlow模型导出到OpenCV调用
TensorFlow模型导出到OpenCV调用
- 引言
- 1.模型训练
-
- (1)些许改进
- (2)整体训练模型的代码如下:
- (3)生成模型
- (4)控制台结果
- 2.使用tensorboard查看模型架构,找出输入输出(可跳过)
-
- (1)生成事件文件
- (2)在cmd中执行以下语句
- (3)执行结果
- (4)在浏览器中查看
- 3.导出为pb文件
-
- (1)注意事项
- (2)代码如下:
- (3)执行结果如下
- 4.查看pb文件的节点名称(可跳过)
-
- (1)代码如下:
- (2)执行结果如下:
- 5.使用OpenCV查看其网络信息(可跳过)
-
- (1)代码如下:
- (2)结果如下:
- 6.使用OpenCV调用模型,输入图片测试分类结果
-
- (1)代码如下:
- (2)结果如下所示:
- 结论
引言
本人因之前学习的c++,所以对c++的界面编程以及对OpenCV的使用较为熟悉,之前也学习过使用OpenCV调用face_detection基于tensorflow平台的模型文件(pb文件,pbtxt)文件,最近也在学习TensorFlow用来训练自己的分类模型,但对如何将已经训练好的模型进行导出,并应用于OpenCV这方面不是很了解,所以查阅了大量资料,总算能够将其实现。
1.模型训练
参考文章: 手把手教你训练分类自己的图片(车辆分类).
(1)些许改进
- 该文章整体架构很清晰,因为要使用此训练的模型,故在其中加入了模型加载及保存功能,使其变为增量训练模型,这样可以进行多次训练,将上次训练的模型加载进来,在此基础上进行训练,可以保存训练结果。
- 因为使用的训练集的分类只有7类,故将其最后一层全连接层的输出改为7,此处是多加了一层使其输出变为7。
- 在此架构中加入了with tf.name_scope(‘name’): ,这是为了后面使用tensorboard查看整体架构时清晰一些。
- 还在最后一层的位置加入了softmax层,这一层不与后面发生关系,因为后面已经有sparse_softmax_cross_entropy了,此softmax仅仅是为了后面用来导出pb文件来使用的,softmax的节点名称是output。
- 此架构本身具有将读入图片变为特定大小的功能,将img = transform.resize(img, (w, h))前的注释去掉即可。
- 当我们想要训练自己的模型时,直接在此架构的基础上将训练模型改成自己想要训练的模型即可。
- 模型训练所用到的数据
直接使用上方参考文章中的数据即可(数据量并不大,可以自己在百度爬取一些图片加入)
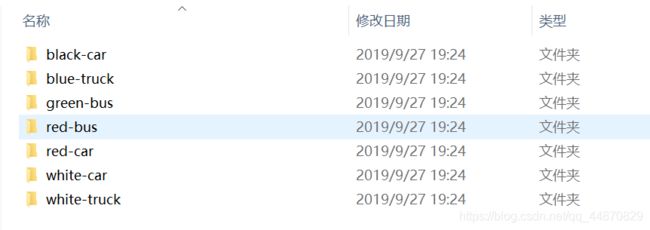
其中black-car有123张,blue-truck有33张,green-bus有22张,red-bus有18张,red-car有114张,white-car有76张,white-truck有36张。总共422张图片。
(2)整体训练模型的代码如下:
1-car_cnn1.py
import os
import glob
import time
import numpy as np
import tensorflow as tf
from skimage import io, transform
# os.environ["TF_CPP_MIN_LOG_LEVEL"] = '1'
# 这是默认的显示等级,显示所有信息
# os.environ["TF_CPP_MIN_LOG_LEVEL"] = '2'
# 只显示 warning 和 Error
os.environ["TF_CPP_MIN_LOG_LEVEL"] = '3'
# 只显示 Error
# 读取图片
def read_img(path, w, h):
cate = [path + x for x in os.listdir(path) if os.path.isdir(path + x)]
# print(cate)
imgs = []
labels = []
print('Start read the image ...')
for index, folder in enumerate(cate):
# print(index, folder)
for im in glob.glob(folder + '/*.jpg'):
# print('Reading The Image: %s' % im)
img = io.imread(im)
img = transform.resize(img, (w, h))
imgs.append(img)
# print(index)
labels.append(index) # 每个子文件夹是一个label
# print(len(labels))
print('Finished ...')
print(len(imgs))
print(len(labels))
return np.asarray(imgs, np.float32), np.asarray(labels, np.float32)
# 打乱顺序 为了均匀取数据
def messUpOrder(data, label):
num_example = data.shape[0]
arr = np.arange(num_example)
np.random.shuffle(arr)
data = data[arr]
label = label[arr]
return data, label
# 将所有数据分为训练集和验证集
def segmentation(data, label, ratio=0.8):
num_example = data.shape[0]
s = np.int(num_example * ratio)
x_train = data[:s]
y_train = label[:s]
x_val = data[s:]
y_val = label[s:]
return x_train, y_train, x_val, y_val
# 构建网络
def buildCNN(w, h, c):
# 占位符
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, shape=[None, w, h, c], name='x-input')
y_ = tf.placeholder(tf.int32, shape=[None, ], name='y_')
# 第一个卷积层 + 池化层(100——>50)
with tf.name_scope('conv2d-pool-1'):
conv1 = tf.layers.conv2d(
inputs=x,
filters=32,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01))
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
# 第二个卷积层 + 池化层 (50->25)
with tf.name_scope('conv2d-pool-2'):
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01))
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
# 第三个卷积层 + 池化层 (25->12)
with tf.name_scope('conv2d-pool-3'):
conv3 = tf.layers.conv2d(
inputs=pool2,
filters=128,
kernel_size=[3, 3],
padding="same",
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01))
pool3 = tf.layers.max_pooling2d(inputs=conv3, pool_size=[2, 2], strides=2)
# 第四个卷积层 + 池化层 (12->6)
with tf.name_scope('conv2d-pool-4'):
conv4 = tf.layers.conv2d(
inputs=pool3,
filters=128,
kernel_size=[3, 3],
padding="same",
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01))
pool4 = tf.layers.max_pooling2d(inputs=conv4, pool_size=[2, 2], strides=2)
re1 = tf.reshape(pool4, [-1, 6 * 6 * 128])
# 全连接层
with tf.name_scope('layer-1'):
dense1 = tf.layers.dense(inputs=re1,
units=1024,
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.contrib.layers.l2_regularizer(0.003))
with tf.name_scope('layer-2'):
dense2 = tf.layers.dense(inputs=dense1,
units=512,
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.contrib.layers.l2_regularizer(0.003))
with tf.name_scope('layer-3'):
dense3 = tf.layers.dense(inputs=dense2,
units=32,
activation=None,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.contrib.layers.l2_regularizer(0.003))
with tf.name_scope('layer-4'):
logits = tf.layers.dense(inputs=dense3,
units=7,
activation=None,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.contrib.layers.l2_regularizer(0.003))
# 定义最后一层以此(此层只是用来挤压最后一个全连接层,得到概率,这个层次并未在后面的优化器中使用,只是为了)
#为了得到pb文件,或者在tensorboard可视化,以及用于导入OpenCV中使用
output = tf.nn.softmax(logits, name='output')
return logits, x, y_
# 返回损失函数的值,准确值等参数
def accCNN(logits, y_):
with tf.name_scope('cross_entropy'):
loss = tf.losses.sparse_softmax_cross_entropy(labels=y_, logits=logits)
with tf.name_scope('AdamOptimizer'):
train_op = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss) #优化器
with tf.name_scope('acc'):
correct_prediction = tf.equal(tf.cast(tf.argmax(logits, 1), tf.int32), y_)
acc = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return loss, train_op, correct_prediction, acc
# 定义一个函数,按批次取数据
def minibatches(inputs=None, targets=None, batch_size=None, shuffle=False):
assert len(inputs) == len(targets), 'len(inputs) != len(targets)'
if shuffle:
indices = np.arange(len(inputs)) # [0, 1, 2, ..., 422]
np.random.shuffle(indices) # 打乱下标顺序
#从0开始,到结束,步长为batch_size
for start_idx in range(0, len(inputs) - batch_size + 1, batch_size):
if shuffle:
excerpt = indices[start_idx:start_idx + batch_size]
else:
excerpt = slice(start_idx, start_idx + batch_size)
yield inputs[excerpt], targets[excerpt]
# 训练和测试(加入模型加载及保存功能,使其为增量训练)
def runable(x_train, y_train, train_op, loss, acc, x, y_, x_val, y_val):
# 训练和测试数据,可将n_epoch设置更大一些
n_epoch = 10 #之前是100轮,有点多,改成增量训练模型后就可以多轮次增加训练了
batch_size = 30 #20是每批读取数据的数量
###创建saver对象用于模型保存和加载
saver = tf.train.Saver()
sess = tf.InteractiveSession() #手动启动session对话,还需关闭(也可使用with)
sess.run(tf.global_variables_initializer()) #对全局变量初始化先
###训练之前,检查是否存在已经训练的模型(要在初始化后进行判断)
# 如果存在则加载进来,进行增量训练
if os.path.exists("./model/checkpoint"): # 判断此文件是否存在
saver.restore(sess, "./model/") # 将此模型加载到sess中,sess就有了经过训练的参数了,如权重和偏执,经过梯度下降训练了一段时间的
print("模型加载成功")
for epoch in range(n_epoch):
print('epoch: ', epoch) #打印轮次
# training
train_loss, train_acc, n_batch = 0, 0, 0
for x_train_a, y_train_a in minibatches(x_train, y_train, batch_size, shuffle=True): #定义每轮的训练批次
# print('x_val_a: ', x_val_a.shape())
# print('y_val_a: ', y_val_a.shape())
_, err, ac = sess.run([train_op, loss, acc], feed_dict={
x: x_train_a, y_: y_train_a}) #执行操作并返回参数
train_loss += err
train_acc += ac
n_batch += 1
print("train loss: %f" % (train_loss / n_batch))
print("train acc: %f" % (train_acc / n_batch))
# validation
val_loss, val_acc, n_batch = 0, 0, 0
for x_val_a, y_val_a in minibatches(x_val, y_val, batch_size, shuffle=False):
# print('x_val_a: ', x_val_a)
# print('y_val_a: ', y_val_a)
err, ac = sess.run([loss, acc], feed_dict={
x: x_val_a, y_: y_val_a})
val_loss += err
val_acc += ac
n_batch += 1
print("validation loss: %f" % (val_loss / n_batch))
print("validation acc: %f" % (val_acc / n_batch))
print('*' * 50)
###训练完成后保存模型
saver.save(sess, "./model/")
sess.close() #关闭会话
if __name__ == '__main__':
imgpath = 'dataset/'
w = 100
h = 100
c = 3
ratio = 0.8 # 选取训练集的比例
data, label = read_img(path=imgpath, w=w, h=h)#读取图片
print(0)
data, label = messUpOrder(data=data, label=label)#打乱顺序
print(1)
x_train, y_train, x_val, y_val = segmentation(data=data, label=label, ratio=ratio) #分为训练集和验证集
print('x_train: ', len(x_train))
print('y_train: ', len(y_train))
print(2)
logits, x, y_ = buildCNN(w=w, h=h, c=c) #构建网络返回最后一层结果,此时还不执行,只是操作
print(3)
print(logits)
loss, train_op, correct_prediction, acc = accCNN(logits=logits, y_=y_) #评估网络,返回损失函数,训练,预测值,准确率
#返回损失函数,优化器,预测值,准确率等操作,需在后面的训练函数中执行操作
print(4)
runable(x_train=x_train, y_train=y_train, train_op=train_op, loss=loss, acc=acc, x=x, y_=y_, x_val=x_val, y_val=y_val)
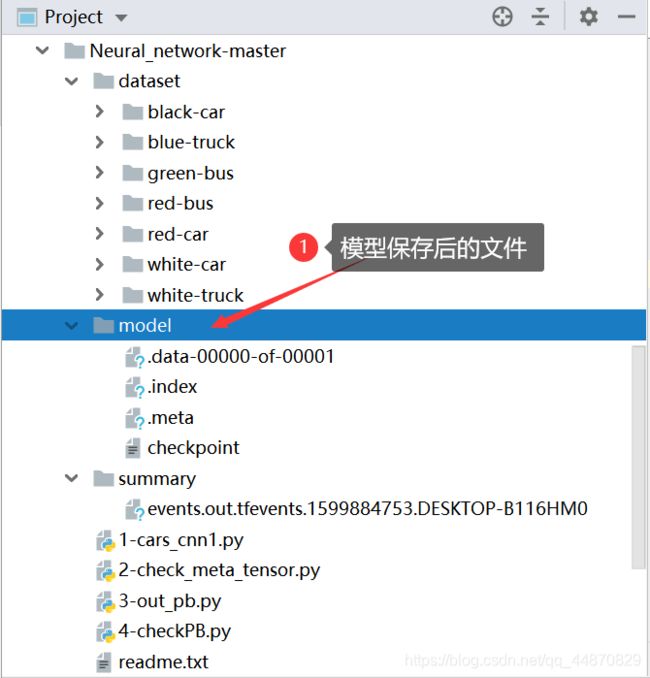
(3)生成模型
会生成四个文件,在后面导出成pb文件时会用到
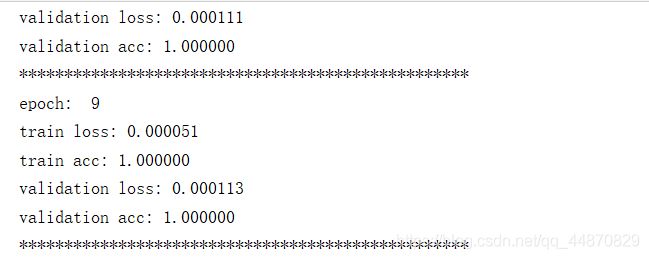
(4)控制台结果
运行了10多次,每次差不多10轮(epoch),总共100轮,最终训练结果的准确率达到100%。在其本身的训练集下,当然其训练集本身图片数量并不多,所得的模型在此训练集表现良好,可以在其数据集下再增加一些图片,这样训练得到的模型会更好一些。
2.使用tensorboard查看模型架构,找出输入输出(可跳过)
实际中此使用tensorboard步骤可以忽略,因为在之前的代码中已经将节点的输出名称命名好了,直接在后面的导出成pb文件的代码中就可以使用了。
(1)生成事件文件
先执行以下代码,生成事件文件,此事件文件会导入到tensorboard,可以在浏览器中查看
2-check_meta_tensor.py
import tensorflow as tf
sess = tf.Session()
tf.train.import_meta_graph("./model/.meta")
tf.summary.FileWriter("./summary", sess.graph)
生成的事件文件如下
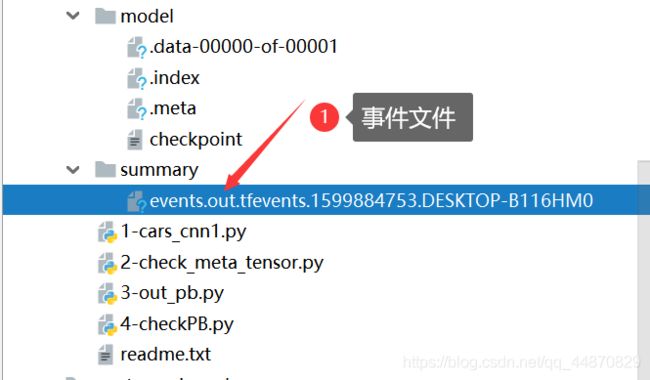
(2)在cmd中执行以下语句
- 进入到python创建的项目的scripts文件下
C:\Users\zhaocai>G:
G:>cd G:\AILearning\AID2002\venv\Scripts - 执行以下操作
G:\AILearning\AID2002\venv\Scripts>tensorboard --logdir=“G:\AILearning\AID2002\Neural_network-master\summary”
(3)执行结果
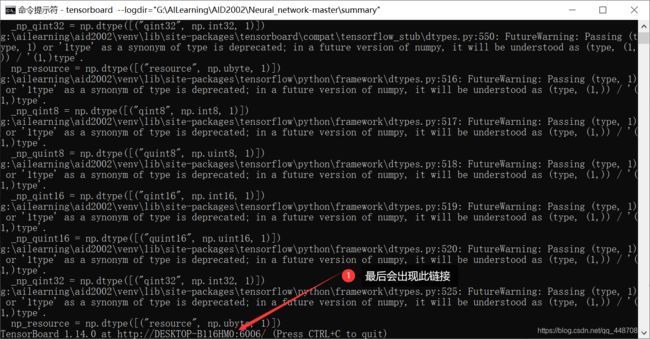
(4)在浏览器中查看
- 在浏览器输入http://localhost:6006/
下方就是该模型的架构,上面的节点名称有的是通过with tf.name_scope(‘name’)命名的,而有的是直接在操作中命名的,如softmax中的output名称。可以在tensorboard中清晰的看到模型的结构。
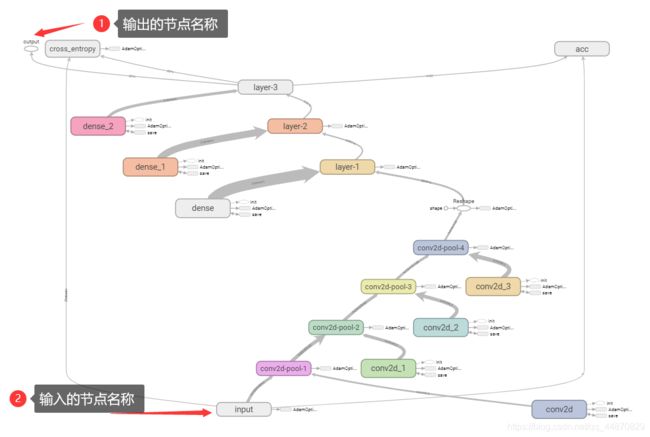
3.导出为pb文件
参考链接:从TensorFlow模型导出到OpenCV部署详解.
(1)注意事项
- 此处要注意的是输出层的名称,在之前训练模型的代码中加入了softmax层,并为其命名为‘output’,就是为了在此导出pb文件而使用的。
- 此处为了适应本地文件,在此代码中做了一些调整
(2)代码如下:
3-out_pb.py
#转换成pb文件
import tensorflow as tf
import os.path
import argparse
from tensorflow.python.framework import graph_util
def freeze_graph(output_node_names):
#checkpoint = tf.train.get_checkpoint_state(model_folder)
#input_checkpoint = checkpoint.model_checkpoint_path
saver = tf.train.import_meta_graph('./model/.meta', clear_devices=True)
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def()
with tf.Session() as sess:
saver.restore(sess, './model/')
for node in input_graph_def.node:
if node.op == 'RefSwitch':
node.op = 'Switch'
for index in range(len(node.input)):
if 'moving_' in node.input[index]:
node.input[index] = node.input[index] + '/read'
elif node.op == 'AssignSub':
node.op = 'Sub'
if 'use_locking' in node.attr: del node.attr['use_locking']
output_graph_def = graph_util.convert_variables_to_constants(
sess,
input_graph_def,
output_node_names
)
with tf.gfile.GFile('classify-car.pb', "wb") as f:
f.write(output_graph_def.SerializeToString())
if __name__ == '__main__':
freeze_graph(['output'])
(3)执行结果如下
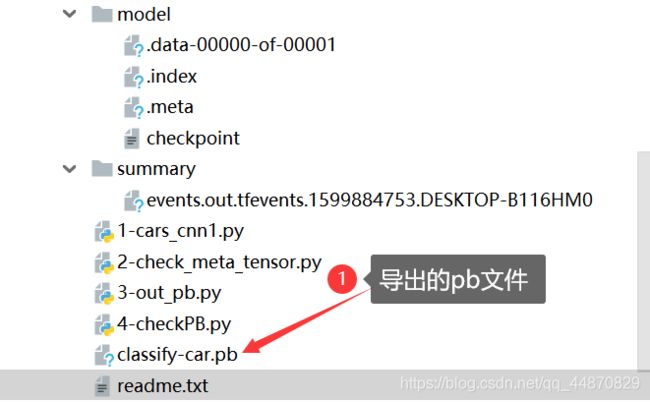
4.查看pb文件的节点名称(可跳过)
参考链接: TensorFlow查看输入节点和输出节点名称.
(1)代码如下:
4-checkPB.py
import tensorflow as tf
import os
# model_dir = './'
out_path = './'
model_name = 'classify-car.pb'
def create_graph():
with tf.gfile.FastGFile(os.path.join(out_path + model_name), 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='')
create_graph()
tensor_name_list = [tensor.name for tensor in tf.get_default_graph().as_graph_def().node]
for tensor_name in tensor_name_list:
print(tensor_name)
(2)执行结果如下:
input/x-input
conv2d/kernel
conv2d/kernel/read
conv2d/bias
conv2d/bias/read
conv2d-pool-1/conv2d/Conv2D
conv2d-pool-1/conv2d/BiasAdd
conv2d-pool-1/conv2d/Relu
conv2d-pool-1/max_pooling2d/MaxPool
conv2d_1/kernel
conv2d_1/kernel/read
conv2d_1/bias
conv2d_1/bias/read
conv2d-pool-2/conv2d/Conv2D
conv2d-pool-2/conv2d/BiasAdd
conv2d-pool-2/conv2d/Relu
conv2d-pool-2/max_pooling2d/MaxPool
conv2d_2/kernel
conv2d_2/kernel/read
conv2d_2/bias
conv2d_2/bias/read
conv2d-pool-3/conv2d/Conv2D
conv2d-pool-3/conv2d/BiasAdd
conv2d-pool-3/conv2d/Relu
conv2d-pool-3/max_pooling2d/MaxPool
conv2d_3/kernel
conv2d_3/kernel/read
conv2d_3/bias
conv2d_3/bias/read
conv2d-pool-4/conv2d/Conv2D
conv2d-pool-4/conv2d/BiasAdd
conv2d-pool-4/conv2d/Relu
conv2d-pool-4/max_pooling2d/MaxPool
Reshape/shape
Reshape
dense/kernel
dense/kernel/read
dense/bias
dense/bias/read
layer-1/dense/MatMul
layer-1/dense/BiasAdd
layer-1/dense/Relu
dense_1/kernel
dense_1/kernel/read
dense_1/bias
dense_1/bias/read
layer-2/dense/MatMul
layer-2/dense/BiasAdd
layer-2/dense/Relu
dense_2/kernel
dense_2/kernel/read
dense_2/bias
dense_2/bias/read
layer-3/dense/MatMul
layer-3/dense/BiasAdd
dense_3/kernel
dense_3/kernel/read
dense_3/bias
dense_3/bias/read
layer-4/dense/MatMul
layer-4/dense/BiasAdd
output
很明显,从输入到输出的节点都已经包括在其内了
5.使用OpenCV查看其网络信息(可跳过)
此处加载网络并未用到pbtxt文件,网上也有将pb文件导出为pbtxt文件的代码,但当将pb导出为pbtxt时,无法也将pbtxt加载到网络中,具体原因暂不明确。
不过此处只加载pb文件就能够使用了
(1)代码如下:
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp> //包含dnn模块的头文件
#include <iostream>
#include <fstream> //文件流进行txt文件读取
using namespace cv;
using namespace cv::dnn; //包含dnn的命名空间
using namespace std;
int main() {
//车辆分类,输入模型的地址
string bin_model = "G:/AILearning/models/classify-car/classify-car.pb";
//加载模型
Net net = readNetFromTensorflow(bin_model);
//获取各层信息
vector<string> layer_names = net.getLayerNames(); //此时我们就可以获取所有层的名称了,有了这些可以将其ID取出
for (int i = 0; i < layer_names.size(); i++) {
int id = net.getLayerId(layer_names[i]); //通过name获取其id
auto layer = net.getLayer(id); //通过id获取layer
printf("layer id:%d,type:%s,name:%s\n", id, layer->type.c_str(), layer->name.c_str()); //将每一层的id,类型,姓名打印出来(可以明白此网络有哪些结构信息了)
}
waitKey(0);
return 0;
}
(2)结果如下:

6.使用OpenCV调用模型,输入图片测试分类结果
(1)代码如下:
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp> //包含dnn模块的头文件
#include <iostream>
#include <fstream> //文件流进行txt文件读取
using namespace cv;
using namespace cv::dnn; //包含dnn的命名空间
using namespace std;
//定义名称,用于后面的显示操作
String objNames[] = {
"black-car","blue-truck",
"green-bus","red-bus","red-car",
"white-car","white-truck" };
int main() {
//模型的pb文件
string bin_model = "G:/AILearning/models/classify-car/classify-car3.pb";
load DNN model
Net net = readNetFromTensorflow(bin_model);
//获取各层信息
//vector layer_names = net.getLayerNames(); //此时我们就可以获取所有层的名称了,有了这些可以将其ID取出
//for (int i = 0; i < layer_names.size(); i++) {
// int id = net.getLayerId(layer_names[i]); //通过name获取其id
// auto layer = net.getLayer(id); //通过id获取layer
// printf("layer id:%d,type:%s,name:%s\n", id, layer->type.c_str(), layer->name.c_str()); //将每一层的id,类型,姓名打印出来(可以明白此网络有哪些结构信息了)
//}
Mat src = imread("G:/AILearning/testImage/2-21.jpg"); //G:\AILearning\testImage
//2-20,2-21,2-11,2-1
if (src.empty()) {
cout << "could not load image.." << endl;
getchar();
return -1;
}
imshow("src", src);
//构建输入(根据建立的网络模型时的输入)
Mat inputBlob = blobFromImage(src, 1.0, Size(100, 100), Scalar(), true, false); //我们要将图像resize成100*100的才是我们神经网络可以接受的宽高
//参数1:输入图像,参数2:默认1.0表示0-255范围的,参数3:设置输出的大小,参数4:均值对所有数据中心化预处理,参数5:是否进行通道转换(需要),参数6:,参数7:默认深度为浮点型
//上方得到的inputBlob是4维的(在变量窗口看dim),所以在imagewatch中无法查看
//设置输入
//现在要将其输入到创建的网络中
net.setInput(inputBlob);
//进行推断得到输出
//让网络执行得到output,调用forward可以得到一个结果
//此处不给参数,得到的是最后一层的结果,也可以输入层数得到任何一层的输出结果
Mat probMat = net.forward(); //通过前面的输出层看最后一层,可以知道输出7个分类
对数据进行序列化(变成1行n列的,可以在后面进行方便的知道是哪个index了)
Mat prob = probMat.reshape(1, 1); //reshape函数可以进行序列化,(输出为1通道1行的数据,参数1:1个通道,参数2:1行)将输出结果变成1行n列的,但前面probMat本身就是7*1*1
// //实际结果probMat和prob相同
// //当其他网络probMat需要序列化的时候,reshape就可以了
此时找到最大的那个
Point classNum;
double classProb;
minMaxLoc(prob, NULL, &classProb, NULL, &classNum);//此时只获取最大值及最大值位置,最小值不管他
int index = classNum.x; //此时得到的是最大值的列坐标。就是其类的索引值,就可以知道其类名了
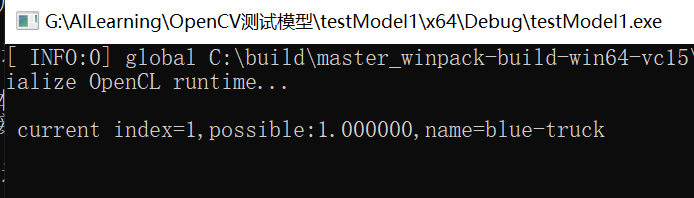
printf("\n current index=%d,possible:%2f,name=%s\n", index, classProb, objNames[index].c_str());
此时可以将名称打印到图片上去
putText(src, objNames[index].c_str(), Point(50, 50), FONT_HERSHEY_SIMPLEX, 0.75, Scalar(0, 0, 255), 2, 8);
imshow("result", src);
waitKey(0);
return 0;
}
(2)结果如下所示:

结论
- 从数据集中随机挑选了10张图片,全部分类正确。但从网上再次下载新的图片对其分类时,有一部分分类出现了错误,这说明我们的训练的模型还不够完善,尽管在422张的数据集上达到了100%的准确率,但这些数据还不够,需要下载更多的图片对其进行训练。
- 可以使用爬虫工具批量爬取图片,使得数据集每个类下的数据达到200张以上即可,当然越多越好,但数量越多,所需的计算时间也会越多,根据具体情况,自己自行确定。
- 本文主要提供了一种从TensorFlow模型训练到使用OpenCV调用的一种方式,这样大家可以将自己训练好的模型能够结合OpenCV真实应用出来,可以训练好模型部署到实际项目中。
- 因为本文章参考了大量网上的公开的文章,故也将此文章公开,希望能对大家有所帮助。