使用keras CNN卷积神经网络训练mnist手写数字识别并输入图片预测
前言
CNN卷积网络结构由输入层、输出层、卷积层、池化层、全连接层构成。
相比于传统的NN,CNN更好的诠释了神经网络,也使得模型就更加稳健。
本次实验使用CNN来训练mnist手写数字识别并预测。
准备工作
TensorFlow版本:1.13.1
Keras版本:2.1.6
Numpy版本:1.18.0
matplotlib版本:2.2.2
导入所需的库
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Convolution2D,Activation,MaxPooling2D,Flatten,Dense
from keras.optimizers import Adam
使用datasets中的mnist数据集,np_utils用于将标签转换成One-Hot编码格式,Sequential用于构建模型,Convolution2D用于卷积,Activation用于激活函数使用,MaxPooling2D池化操作,Flatten扁平化操作,Dense神经元层,Adam为优化器。
设置参数
nb_class = 10 #代表10个类别
nb_epoch = 4 #迭代4次epoch
batchsize = 128 #批次 根据自己的电脑配置设置
划分数据集
#训练集 训练集标签 测试集 测试集标签
(X_train,Y_train),(X_test,Y_test) = mnist.load_data()
X_train = X_train.reshape(-1,28,28,1) #-1代表未知,系统自己找,也可以自己设置60000,因为图片只有黑白通道所以设置1 RGB图片设置3
X_test = X_test.reshape(-1,28,28,1)
One-Hot编码
#标签转换为One-hot格式 [0,0,0,0,0,1,0,0,0,0] = 5
Y_train = np_utils.to_categorical(Y_train,nb_class)
Y_test = np_utils.to_categorical(Y_test,nb_class)
构建模型
#初始化模型
model = Sequential()
#1st
model.add(Convolution2D(
input_shape=(28,28,1) #输入图片的维度
filters=32, #32个卷积核 (28,28,1) ---> (28,28,32)
kernel_size=(5,5), #卷积核设置(5,5)
padding='same', #步长
))
model.add(Activation('relu'))
model.add(MaxPooling2D(
pool_size=(2,2), #设置2*2的核 (28,28,32) ---> (14,14,32)
strides=(2,2), #跳过2*2执行
padding='same', #步长
))
#2nd
model.add(Convolution2D(
filters=64, #64个卷积核 (28,28,32) ---> (28,28,64)
kernel_size=(5,5), #卷积核设置(5,5)
padding='same', #步长
input_shape=(28,28,1) #输入图片的维度
))
model.add(Activation('relu'))
model.add(MaxPooling2D(
pool_size=(2,2), #设置2*2的核 (14,14,32) ---> (7,7,64)
strides=(2,2), #跳过2*2执行
padding='same', #步长
))
#1st Dense
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
#2nd Dense
model.add(Dense(10)) #tabel
model.add(Activation('softmax'))
第一次卷积32个卷积核,由原来的(28,28,1)卷积后为(28,28,32)
池化后由原来的(28,28,32)变为(14,14,32)
第二次卷积由第一次卷积的(28,28,32)变为(28,28,64)
池化后由上一次的(14,14,32)变为(7,7,64)
卷积池化完之后进行Flatten扁平化操作,俗话称“降维打击”
扁平成一维之后Dense设置为10个神经元,采用softmax激活函数,因为这是个多分类问题数字只有0-9个数字。
编译模型
#Optimizer and setup Param
adam = Adam(lr = 0.0001) #学习率 越小越慢 越大越容易过拟合
#compile model
model.compile(
optimizer=adam, #优化器
loss='categorical_crossentropy', #损失函数
metrics=['accuracy'], #评价指标
)
学习率设置为0.0001,学习率越小越慢,越大越容易过拟合。
loss损失函数sparse_categorical_crossentropy与categorical_crossentropy的区别:
sparse_categorical_crossentropy要求target为非One-hot编码,函数内部进行One-hot编码实现。
categorical_crossentropy要求target为One-hot编码。
One-hot格式如: [0,0,0,0,0,1,0,0,0,0] = 5
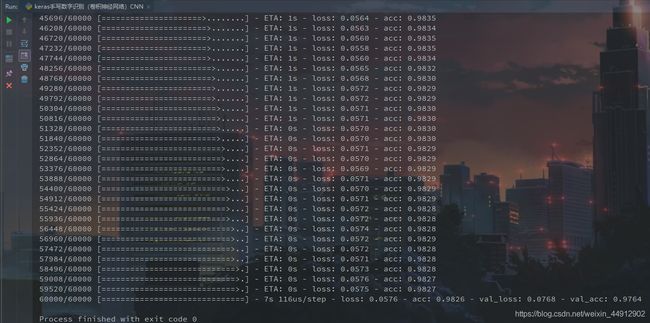
训练模型
#fit model
model.fit(
x=X_train,
y=Y_train,
epochs=nb_epoch, #迭代次数
batch_size=batchsize, #批次
validation_data=(X_test,Y_test) #验证集
)
保存模型
model.save('./model_mnistCNN.h5')
模型预测
导入所需的库
from keras.models import load_model
import numpy as np
import cv2
加载模型
model = load_model('./model_mnistCNN.h5')
处理读入的图片
#这里我读入一张shape为(224,222,3)的图片
pred_img = cv2.imread(filename) #读取图片
#重新resize图片大小 从原图(224,222,3) ---> (28,28,3)
pred_img = cv2.resize(pred_img,(28,28)) #resize图片大小
#将图片转换成灰度图 从(28,28,3) ---> (28,28)
pred_img = cv2.cvtColor(pred_img,cv2.COLOR_BGR2GRAY) #BGR转灰度图
#将图片转换成np数组格式
pred_img = np.array(pred_img) #转换np数组格式
#-1代表未知 系统自己找 也可以自己设置60000 最后1代表灰度只有黑白色
pred_img = pred_img.reshape(-1,28,28,1) #reshape图片
#将处理好的图片丢到模型中预测
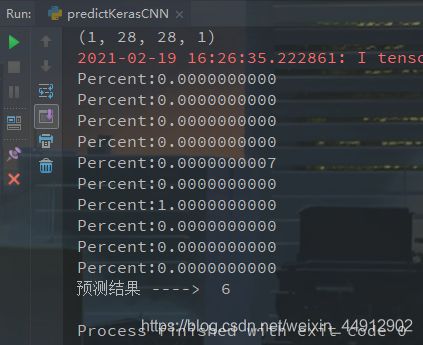
prediction = model.predict(pred_img) #使用模型测试图片
Final_prediction = [result.argmax() for result in prediction][0] #取预测出来的最大值 #[1,5,3,4,2,9,8,7]
#遍历输入0-9的概率
for i in prediction[0]:
print('Percent:{:.10f}'.format(i))
return Final_prediction
预测图片:

预测结果:
完整代码
train.py
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Convolution2D,Activation,MaxPooling2D,Flatten,Dense
from keras.optimizers import Adam
nb_class = 10 #代表10个类别
nb_epoch = 4 #迭代4次epoch
batchsize = 128 #批次 根据自己的电脑配置设置
(X_train,Y_train),(X_test,Y_test) = mnist.load_data()
X_train = X_train.reshape(-1,28,28,1) #-1代表未知,系统自己找,也可以自己设置60000,因为图片只有黑白通道所以设置1 RGB图片设置3
X_test = X_test.reshape(-1,28,28,1)
#归一化(收敛)
# X_train = X_train.astype('float32')
# X_test = X_test.astype('float32')
# X_train /= 255.0
# X_test /= 255.0
#- 7s 117us/step - loss: 0.0870 - acc: 0.9741 - val_loss: 0.0742 - val_acc: 0.9769
#标签转换为One-hot格式 [0,0,0,0,0,1,0,0,0,0] = 5
Y_train = np_utils.to_categorical(Y_train,nb_class)
Y_test = np_utils.to_categorical(Y_test,nb_class)
#初始化模型
model = Sequential()
#1st
model.add(Convolution2D(
filters=32, #32个卷积核
kernel_size=(5,5), #卷积核设置(5,5)
padding='same', #步长
input_shape=(28,28,1) #输入图片的维度
))
model.add(Activation('relu'))
model.add(MaxPooling2D(
pool_size=(2,2), #设置2*2的核
strides=(2,2), #跳过2*2执行
padding='same', #步长
))
#2nd
model.add(Convolution2D(
filters=64, #64个卷积核
kernel_size=(5,5), #卷积核设置(5,5)
padding='same', #步长
input_shape=(28,28,1) #输入图片的维度
))
model.add(Activation('relu'))
model.add(MaxPooling2D(
pool_size=(2,2), #设置2*2的核
strides=(2,2), #跳过2*2执行
padding='same', #步长
))
#1st Dense
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
#2nd Dense
model.add(Dense(10)) #tabel
model.add(Activation('softmax'))
#Optimizer and setup Param
adam = Adam(lr = 0.0001) #学习率 越小越慢 越大越容易过拟合
#compile model
model.compile(
optimizer=adam,
loss='categorical_crossentropy',
metrics=['accuracy'],
)
#fit model
model.fit(
x=X_train,
y=Y_train,
epochs=nb_epoch,
batch_size=batchsize,
validation_data=(X_test,Y_test)
)
model.save('./model_mnistCNN.h5')
predict.py
from keras.models import load_model
import numpy as np
import cv2
model = load_model('./model_mnistCNN.h5')
def pred(filename):
pred_img = cv2.imread(filename) #读取图片
#使用cv.resize将原图大小(224, 222,3) 转换成 (28,28,3)
resize_img = cv2.resize(pred_img,(28,28)) #resize图片大小
#将图片从BGR转换成GRAY 也就是灰度值转换从 (28,28,3) 转换成 (28,28,1)
gray_img = cv2.cvtColor(resize_img,cv2.COLOR_BGR2GRAY) #BGR转灰度图
#将图片保存到np数组中
arr_img = np.array(togray_img) #转换np数组格式
#-1代表未知 系统自己找 也可以自己设置60000 最后的1代表灰度图片 只有黑白
reshape_img = arr_img.reshape(-1,28,28,1) #reshape图片
#将图片丢到模型中预测
prediction = model.predict(reshape) #使用模型测试图片
Final_prediction = [result.argmax() for result in prediction][0] #取预测出来的最大值 #[1,5,3,4,2,9,8,7]
#遍历0-9的概率
for i in prediction[0]:
print('Percent:{:.10f}'.format(i))
return Final_prediction
if __name__ =='__main__':
res = pred('./data1.png')
print('预测结果 ----> ',res)
踩坑点
- 在我们使用opencv的时候,使用imread图片的时候路径不能出现"\“这样的斜杠,必须是”/"这样的斜杠才能被cv识别路径。
- 在我们预测图片的时候,图片必须是字体是白色,背景是黑色,不然预测是错误的。这个问题可以通过opencv来对图片的颜色进行调整或变换。
总结
相比传统神经网络(NN)的优点:
1.参数共享机制(parameterssharing)
因为,对于不同的区域,我们都共享同一个filter,因此就共享这同一组参数。这也是有道理的,通过前面的讲解我们知道,filter是用来检测特征的,那一个特征一般情况下很可能在不止一个地方出现,比如“竖直边界”,就可能在一幅图中多出出现,那么我们共享同一个filter不仅是合理的,而且是应该这么做的。
由此可见,参数共享机制,让我们的网络的参数数量大大地减少。这样,我们可以用较少的参数,训练出更加好的模型,典型的事半功倍,而且可以有效地避免过拟合。同样,由于filter的参数共享,即使图片进行了一定的平移操作,我们照样可以识别出特征,这叫做“平移不变性”。因此,模型就更加稳健了。
2.连接的稀疏性(sparsityofconnections)
由卷积的操作可知,输出图像中的任何一个单元,只跟输入图像的一部分有关系。而传统神经网络中,由于都是全连接,所以输出的任何一个单元,都要受输入的所有的单元的影响。这样无形中会对图像的识别效果大打折扣。比较,每一个区域都有自己的专属特征,我们不希望它受到其他区域的影响。
正是由于上面这两大优势,使得CNN超越了传统的NN,开启了神经网络的新时代。