2020年AI竞赛获奖方案复盘系列(二) 遥感语义分割竞赛trick-2020华为云人工智能大赛
前言
这是去年博主参加的一个语义分割竞赛,最终取得了top3%(13/377)。这是博主第一次参加遥感图像语义分割竞赛,借着这次机会博主开始了语义分割的学习旅程,比起最终名次,博主更在意的是在这个过程中能学到什么。在上次复盘了违法广告目标检测竞赛之后,博主充分意识到了复盘的重要性,因此迫不及待地对这次遥感分割竞赛进行复盘。
没看过之前违法广告的目标检测竞赛复盘的朋友可以也关注下检测赛,因为是2020年的竞赛里面很多的model和trick都是最新的,也涉及很多cvpr2020的论文。下面是传送门:
违法广告目标检测赛传送门
回到本篇文章,这次遥感分割赛主要是根据高清遥感卫星影响图来对各种道路进行分割,这些道路有的是“通天大道”,有的是“羊肠小道”,充满了细节部分。最终博主团队的模型是0.833,冠军是0.841,所以相差不是很多,博主认为主要的难点是如何平衡模型既看到大的整体大的目标,又看到非常微小的小路。博主复盘的时候感觉自己在冲刺阶段的思路出现了问题,我当时有三种思路,都是基于训练好大模型(对于大的道路分割效果优秀)的基础上通过finetune迫使模型学习细节。第一种是通过使用Focal loss/OHEM做finetune去强迫模型去学习细节;第二种是通过微小的学习率和batchsize去finetune迫使模型关注每张图片的细节;第三种是在多尺度的输入上进行finetune。
事实证明这三种finetune的思路都不是那么的work,也导致博主最后遗憾的以微弱劣势没能冲进top10。
现在如果重新再来我可能更多会考虑:
- FPN/BiFPN
- 再在remain high resoluton上做一些尝试,比如deformable convoluton之类的。
- 使用多个大model蒸馏小model,这些大model会被设置成有的关注细节有点会更关注整体。
- 一种基于OCRNet和large kernel matters论文博主发现的涨点技巧,我最后会提到。
另一个难点是这场比赛对于模型的推理时间和显存占用非常的约束。我没有具体去测试flops,但是ensmble大参数量的模型是几乎不可能的。后来又传出TTA会被扣分,所以我们也没用TTA(太老实了)。但是同样也让我认识到了要多关注模型的轻量化,关注inference time/flops才有实用的价值。
好了,以上的博主的一些murmur,下面我们还是重点来看我们能从前排大佬里吸到多少欧气吧!
在开始学习之前,请没参加过这场大赛的朋友先浏览下大赛的赛题:
2020华为人工智能大赛传送门
第八名(吸到1点欧气)
1.LinkNet (loss:dice+bce 1:1)
选手采用了LinkNet34(backbone是Resnet34),linknet我之前关注的较少,但是听说这次好几个前排都用了,说明这个网络效果还是不错的,如果把backbone进一步的提升比如senet或者res2net之类的应该这个选手还能提升。
在做竞赛的时候backbone还是要多试一下比较保险,我们这次是deeplabv3+/unet两个支线,大把精力都花在了魔改和EDA上面。再比如后面一个kaggle竞赛中,基于vision transformer的模型在分类上霸榜了,在kaggle 小麦检测中yolov5也完成了霸榜(虽然后来被禁用了)。所以针对不同的数据集,最佳的baseline也是完全不一样的。反思这点,我觉得应该至少熟悉准备4-5个比较靠谱的baseline才能有效地避免一开始就输在起跑线。对于分割赛很显然unet/deeplabv3+/hrnet+ocr/linknet/senet+fpn之类的都应该出现在list上。
说到这里突然想到前几天和一个kaggler聊天,他说他们团队都是专人负责model设计的,也有人专门复杂augmentation,也有人负责train等等,这种团队分配明显是更合理的。我们团队都是端到端的搞,每人负责一个路线。在前期为了多学知识这种思路是可取的,但是后面应该还是更好的分配人力。这些和技术无关了,只是我们的一点反思。
LinkNet的架构非常简单,比Unet还简单,主要focus在flops和推理速度上,致力于实时的语义分割。它有一个变种D-linknet,值得学习,尤其是这个论文就是base在遥感道路分割上的。附上论文的传送门:
D-LinkNet :LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Sate
D-linknet知乎推荐文章
D-linknet是专门为了遥感道路分割设计出来的网络,在论文里主要提到了这类问题的三大难点:
- 遥感影像具备高分辨率,道路有些会跨度极大,需要很大的感受野,覆盖全图。
- 部分道路很细长狭小,需要保留精准的定位信息才能恢复这类细小道路。
- 道路具备自然连通性。
回想这个比赛中,我们也是基本focus在了这些问题上,分别用了空洞卷积/可变形卷积来适配感受野,尝试了膨胀腐蚀和去除孔洞的后处理来保障连通性,但是对于问题二细小道路的定位做的不好。
D-linknet使用的空洞卷积在模型的中间,使用的是串联的方式叠加感受野,同时maintain resoution。空洞卷积无论是串联还是并联都能表现出很好的性能。
D-linknet的架构如下图:
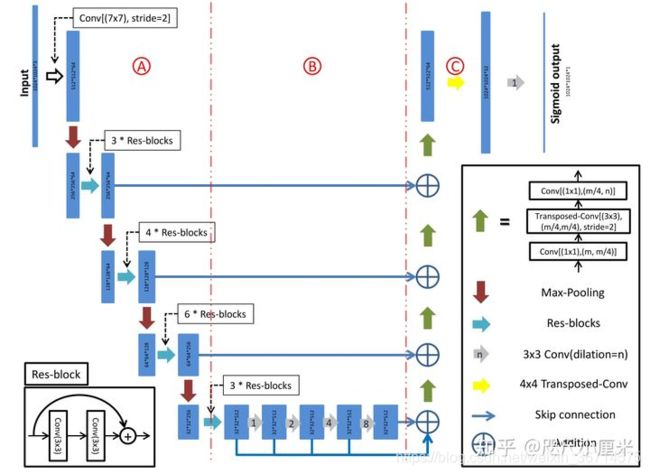
D-linknet的空洞卷积叠加没有使用图森组论文中提到的HDC设计,而是1,2,4,8,16这样叠加。可能会导致棋盘效应,影响分割精度。
HDC可以参考下面这个知乎分析:
关于空洞卷积的HDC
同时大家仔细看这个图,中间的部分很像unet的bridge结构,一定程度上能够指导我们如何设计unet的bridge结构。我在部分比赛中发现unet的bridge结构也是会对最终的结果产生很大的影响。在这里它是dilation的堆叠+skip connection。值得注意的是它的原图是1024的输入,分辨率还是蛮高的,所以才使用32倍下采样。如果输入图片是512或者更小,32倍下采样丢失的位置信息就比较难恢复了。
最终的输出这组选手使用了8倍的TTA,也是说明了linknet系列的轻量化。
第七名(吸到1点欧气)
先放个架构设计图,是四模融合,也足以说明deeplabv3+是比较轻量的。值得学习的部分是OCRnet的使用算是新的技术。
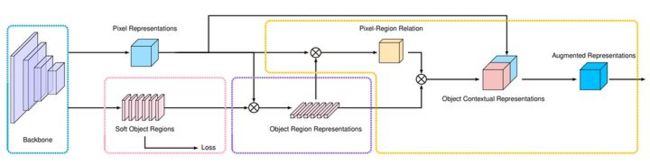
1.OCRNet
OCRnet的和核心思想是在构建上下文信息时显式地增强了来自于同一类物体的像素的贡献,是从语义分割的本质思考得来的思路。
微软亚研院分析了当前语义分割model的三个最大问题:
- 多层下采样导致的定位信息丢失。
- 像素级特征的感受野不够,且物体具有多尺度。
- 边界错误,边界的feature的表达能力比较低。很多语义分割的错误都来自于边界。
从而针对性的提出了:
- HRnet:用于maintain high resolution
- OCRnet:用于增强像素上下文语义信息
- SegFix:用于解决边界错误的问题。
下图是OCRnet的架构:
HRnet/ OCRNet的这部分我打算专门写一个源码解析系列,在这里就不赘述了。
第六名(吸到1点欧气)
1.模型选择
使用了HRnet+OCR,关于为什么使用这个模型的思路较好,这里直接收录选手的思路:
低分辨的特征包含丰富的语义信息,但由于下采样操作,导致它丢失了部分位置信息。而高分辨率的特征相反,它的语义信息相对较少,但位置信息保留较多,定位相对准确,有利于检测小目标。由于道路大多都是长且窄的形状,就要求模型必须定位准确,也就是说道路的检测依赖于高分辨率的特征。现有的大多数网络都是由高分辨率特征下采样到低分辨率特征,再从低分辨率特征中恢复高分辨率特征,但是丢失的位置信息不能完全恢复。而HRNet在整个阶段都保持高分辨率的特征,有利于道路的检测。此外,HRNet的不同分支产生不同分辨率的特征,这些特征之间交互获取信息,最后得到包含多尺度信息的高分辨率特征。因此选择HRNet作为我们backbone。此外,我们认为道路分割不依赖于非常高级的语义信息,因此就不需要非常深的网络,而且在训练数据量有限的情况下,大网络有庞大的参数量,会有过拟合的风险。因此我们选择的是HRNet系列中的小模型:HRNet18。分割头选择OCR注意力模块,利用目标上下文增强特征表示。整个网络结构小,训练速度和推理速度都较快。在实验中,发现HRNet18在速度和精度上都优于hrnet32、hrnet48和deeplabv3+(resnest50)。
这里能学到的就是从问题中选择模型的一种思路(至于信不信的哈哈哈…)。
HRnet/ OCRNet的这部分我打算专门写一个源码解析系列,在这里就不赘述了。
2.loss的设计
这里学习到的也是loss设计的思路:
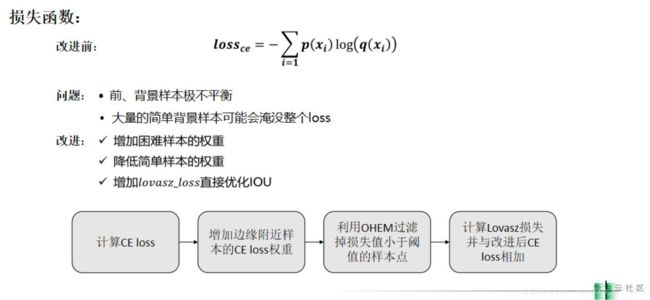
交叉熵损失的问题在于无法解决前景和背景之间的数据不均衡问题。在比赛结束的阶段,大部分的model都能比较好的预测出主体的道路部分,但是会存在细小的道路还有困难的样本识别不好。选手为了解决以上的问题对于边缘附近的pixel进行了损失加权,然后使用了OHEM对于简单样本进行了过滤,最后的loss是lovasz+bce。lovasz是IOU的可导替代形式,可以优化IOU,在部分比赛中有良好效果。
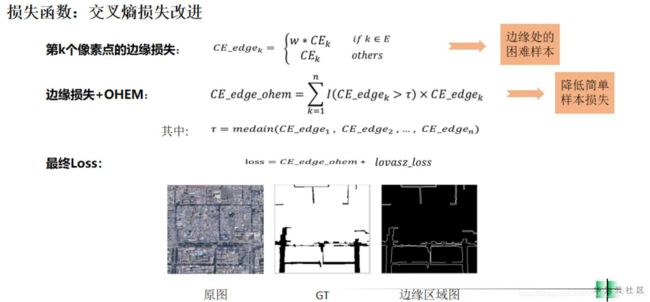
参考上图,选手对于边缘进行了提取,对于边缘的ce loss进行了增加,然后对loss进行了阈值设置,小于阈值的部分被看作简单样本不参与反向传播。最后使用了bce+lovasz softmax。
3.指数滑动平均(EMA)
没用过,暂时保留,回来一定补上。
第五名(吸到一口华子)
1.一些小点
- RandomGridShuffle:把图像裁成四个块,然后打乱顺序,一个不是很常见的augmentation。
- BCE Loss+余弦模拟退火做训练,找到最佳模型后用Lovasz Hinge Loss + StepLR 做微调(也是Lovasz的作者推荐的使用方式),微调的时候使用了线性启动。
- FPN/Unet + EfficientNetB5
第四名(吸到2点欧气)
首先作者分享了源码,掌声~~
源码传送门
1.前景背景不平衡
选手通过计算,得到前景和背景的像素占比约为12.2%和87.8%,像素类别极度不平衡,故我们在loss中加入权重(3: 1),以减轻类别不平衡带来的影响。
说明加权这种方法虽然简单,但是不一定弱,在解决不平衡的问题也要测试这个笨办法。
2.忽略边缘预测
感觉是个骚操作,没有详细说明,回来看看源码一定补上。
第三名(吸到一杆大烟枪)
1.一些小点
- unet+efficientnetB5
- lovasz+focal loss
- Radam+LookAhead 优化器 + 余弦模拟退火
- 多尺度训练,不同batch间图片尺寸进行调整。
- 膨胀预测
以上都是较为常见的技巧,说明用好了也能拿前三。
第一名(吸到1点欧气)
首先,开源了代码,掌声鼓励,传送门如下:
比赛源码传送门
1.方案设计
编码模块选用ImageNet预训练的ResNeXt200网络,在E-D架构的基础上,提出一种通道注意力增强的特征自适应融合方法,并设计基于梯度的边缘约束模块。在增强空间细节和语义特征的同时,提高道路边缘的特征响应,实现多尺度道路准确提取。架构如下:
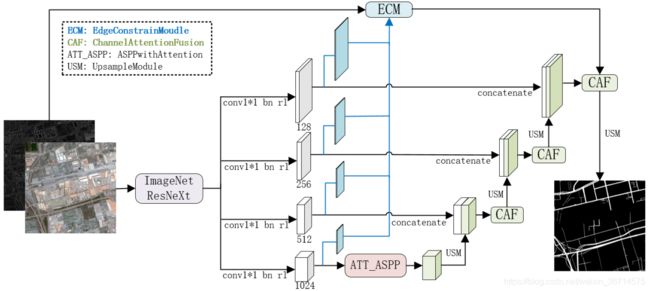
这个架构的特点:
- 输入是四通道,加了一个通道是Sobel算子算出来的梯度信息,这样保证边缘的提取更为准确。
- backbone选择了非常深的Resnext200,可以提取到更深的语义信息,说明有了梯度信息的输入,可以使用较深的网络而还能获得良好的定位信息的恢复。
- 中间的结构有点像D-linknet,只是串联的空洞卷积变成了ASPP结构。
- 上采样融合之后加了CAF,类似channel维度的注意力机制。我在多个比赛中也发现上采样融合之后是比较好的加入注意力的位置,可以理解为channel concat之后需要通道注意力平衡各通道权重的重要性。
- ECM这条路线是一个类似FPN的结构,可以弥补定位的信息。
我在这个比赛结束后,就征得选手的同意,复现了这个网络并且在kaggle的另一场比赛中去校验,可惜的是在病理分割上表现不佳,可能是这个设计思路更适合依赖边缘精度的遥感道路分割。
总结
写完前十名的方案复盘后,我发现并没有我想象的或者说之前参加目标检测比赛的招数层出不穷。虽然也是八仙过海,各显神通。但是整体来说没有特别亮点的地方。
在这个榜单中HRnet+OCRnet也算是占据了半壁江山,说明确实泛化性也是不错的,我后面打算做一期源码的分析,好好整理一下这两个框架,或许再加上Segfix一起吧。
在这次复盘中,收获最大的也不是这些trick,而是如何在比赛中进行思路上调整。一切都要回归到数据中,EDA的探索,发现了什么问题再对症下药,而不是乱做一起,魔改到底。
比如发现了小目标识别不行:就要考虑多尺度训练、FPN、增大resolution…
比如发现了边缘识别不行:就要考虑增加边缘loss、增加梯度信息
比如发现了某类识别不行:就要考虑是不是数据平衡问题?是不是要单独对这个类进行离线数据增强?又或者是这个类不需要很深的语义特征从而考虑maintain resolution?
比如发现了数据不平衡:就要考虑数据增强、loss加权、在线重采样、focal loss、或者是之前目标检测文章提到的留一半?
比如发现了整体效果都不行:就要考虑是不是类别语义信息很差,考虑用OCRnet? 做更多的feature间的融合?等等。
…
…
你们想象吧,我先休息去了…
[本篇完]