在进行基因分析中,我们时常会对样本或基因之间的相关性进行分析,虽然R语言中的cor函数可以进行计算,但并没有提供合适的可视化方法,今天我们介绍一个R包-ggcorr(https://briatte.github.io/ggcorr/),可以对数据的相关性分析进行可视化。
安装
ggcorr可通过GGally包进行安装:
#有两种安装方式
install.packages("GGally")
#or
source("https://raw.githubusercontent.com/briatte/ggcorr/master/ggcorr.R")#仅仅安装该功能
依赖包
ggcorr的主要依赖包是ggplot2软件包(ggplot2高效实用指南 (可视化脚本、工具、套路、配色))。
library(ggplot2)
举个栗子|篮球统计
nba = read.csv("http://datasets.flowingdata.com/ppg2008.csv")
#让我们看一下数据格式
head(nba)
Name G MIN PTS FGM FGA FGP FTM FTA FTP X3PM X3PA X3PP ORB DRB TRB AST STL BLK TO PF
Dwyane Wade 79 38.6 30.2 10.8 22.0 0.491 7.5 9.8 0.765 1.1 3.5 0.317 1.1 3.9 5.0 7.5 2.2 1.3 3.4 2.3
LeBron James 81 37.7 28.4 9.7 19.9 0.489 7.3 9.4 0.780 1.6 4.7 0.344 1.3 6.3 7.6 7.2 1.7 1.1 3.0 1.7
Kobe Bryant 82 36.2 26.8 9.8 20.9 0.467 5.9 6.9 0.856 1.4 4.1 0.351 1.1 4.1 5.2 4.9 1.5 0.5 2.6 2.3
Dirk Nowitzki 81 37.7 25.9 9.6 20.0 0.479 6.0 6.7 0.890 0.8 2.1 0.359 1.1 7.3 8.4 2.4 0.8 0.8 1.9 2.2
Danny Granger 67 36.2 25.8 8.5 19.1 0.447 6.0 6.9 0.878 2.7 6.7 0.404 0.7 4.4 5.1 2.7 1.0 1.4 2.5 3.1
Kevin Durant 74 39.0 25.3 8.9 18.8 0.476 6.1 7.1 0.863 1.3 3.1 0.422 1.0 5.5 6.5 2.8 1.3 0.7 3.0 1.8
我们可以看到top3分别是Wade,James,Kobe(洛杉矶的凌晨4点。。。。再也见不到了o(╥﹏╥)o)。
让我们将整个数据集直接用ggcorr进行分析,计算每一列数值列之间的相关性,并绘制一个下三角热图展示:
ggcorr(nba)
## Warning in ggcorr(nba): data in column(s) 'Name' are not numeric and were
## ignored
# 颜色设置的一个Warning,暂时忽略
## Warning: Non Lab interpolation is deprecated
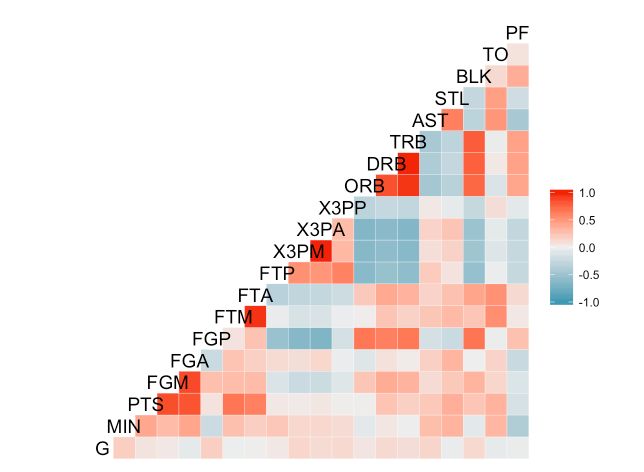
相关性矩阵是一个对称阵,这里用下三角热图展示全部信息。每个格子的颜色代表对于行与列的相关性,颜色越红正相关性越强,越蓝负相关性越强。可以看出:
PTS (Percent of Team's Points, 每场得分), FGM (Field Goals Made, 投篮命中率), FGA (Field Goals Attempted, 尝试投篮次数)之间正相关性比较强,确实多尝试才能获得更高的分数;DRB (Defensive Rebounds,防守篮板), ORB (Defensive Rebounds,进攻篮板), TRB (Defensive Rebounds,总篮板)之间正相关性比较强;3PA (Defensive Rebounds, 三分投篮),3PM (3 Point Field Goals Made,3分命中),3PP (3 Point Field Goal Percentage,3分命中率), FTP (Free Throw Percentage,罚球命中率)之间正相关,但与篮板强负相关,这也是挺符合场上分工的。
更多篮球术语见:
https://www.basketball-reference.com/about/glossary.html
https://stats.nba.com/help/glossary/#3ppct
关联数据集
ggcorr的第一个参数称为data。可以是一个数据框(如上所示)或一个矩阵,在绘制之前将其转换为数据框:
ggcorr(matrix(runif(5), 2, 5))
ggcorr也可以通过cor_matrix接受相关矩阵,在这种情况下,它的第一个参数必须设置为NULL,以指示ggcorr应该使用相关矩阵:
ggcorr(data = NULL, cor_matrix = cor(nba[, -1], use = "everything"))
相关性方法
ggcorr支持cor函数提供的所有相关方法。
相关矩阵中需要考虑的第一个设置是要使用的observations的选择。此设置可以采用以下任何值:“everything”,“ all.obs”,“complete.obs”,“na.or.complete”或“ pairwise.complete.obs”(ggcorr使用的默认值)。
ggcorr要求的第二个设置是要计算的相关系数的类型。有三个可能的值:“pearson”(ggcorr和cor使用的默认值),“kendall”或“spearman”。cor function的文档中说明了每个设置之间的差异。一般而言,除非数据是序数,否则默认选择应为“pearson”,即基于pearson的方法产生相关系数。
例如:
# Pearson correlation coefficients, using pairwise observations (default method)
ggcorr(nba[, -1], method = c("pairwise", "pearson"))
# Pearson correlation coefficients, using all observations
ggcorr(nba[, -1], method = c("everything", "pearson"))
# Kendall correlation coefficients, using complete observations
ggcorr(nba[, -1], method = c("complete", "kendall"))
# Spearman correlation coefficients, using strictly complete observations
ggcorr(nba[, -1], method = c("all.obs", "spearman"))
R语言 - 热图绘制 (heatmap)
R语言 - 热图简化
R语言 - 热图美化
绘图参数
控制色阶
默认情况下,ggcorr使用从-1到+1的连续色标显示矩阵中表示相关性的强度。要切换到分类颜色,需要添加nbreaks参数,该参数指定色标中应包含多少种区块颜色:
ggcorr(nba[, 2:15], nbreaks = 5)

使用nbreaks参数时,通过digits参数控制色阶中显示的位数。digits参数默认为两位数字,但是如上例所示,如果breaks不需要更高的精度,它将默认为一位数字。
对色阶的进一步调控包括:name参数,用于设置其标题;legend.size参数,用于设置图例文本的大小;以及legend.position参数,用于控制图例的显示位置。使用方式和ggplot2相同:
ggcorr(nba[, 2:15], name = expression(rho), legend.position = "bottom", legend.size = 12) +
guides(fill = guide_colorbar(barwidth = 18, title.vjust = 0.75)) +
theme(legend.title = element_text(size = 14))
控制调色板
ggcorr使用默认的颜色渐变,该渐变从鲜红色到浅灰色再到鲜蓝色。可以通过低,中和高参数来修改此梯度,这与ggplot2中的scale_gradient2控制参数类似:
ggcorr(nba[, 2:15], low = "steelblue", mid = "white", high = "darkred")
## Warning: Non Lab interpolation is deprecated
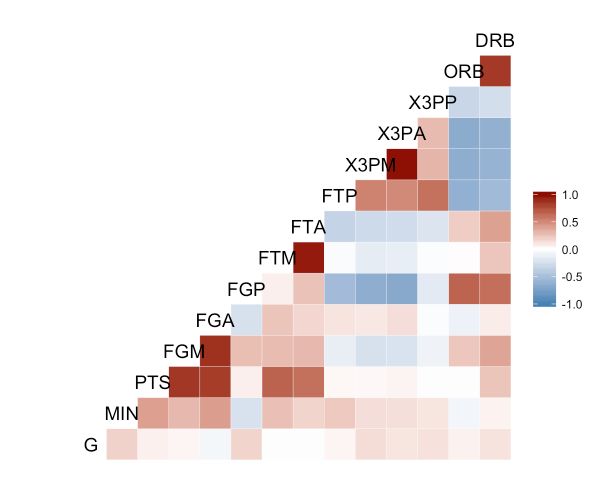
默认情况下,渐变的中点设置为0.0,表示零相关。中点参数可用于修改此设置。特别是,将中点设置为NULL时将自动选择中值相关系数为中点,并向用户显示该值:
ggcorr(nba[, 2:15], midpoint = NULL)
## Color gradient midpoint set at median correlation to 0.08
控制色阶颜色的最后一个选择是通过调色板参数使用ColorBrewer调色板。仅当色阶进行分类时(即使用nbreaks参数时),才应使用此参数:
ggcorr(nba[, 2:15], nbreaks = 4, palette = "RdGy")
论文图表基本规范
学术图表的基本配色方法
数据可视化基本套路总结
控制几何形状
默认情况下,ggcorr使用彩色图块表示相关系数的强度,类似于热图表示方式。
ggcorr也可以将相关性表示为按比例大小的圆圈,就是将其geom参数设置为“circle”:
ggcorr(nba[, 2:15], geom = "circle", nbreaks = 5)
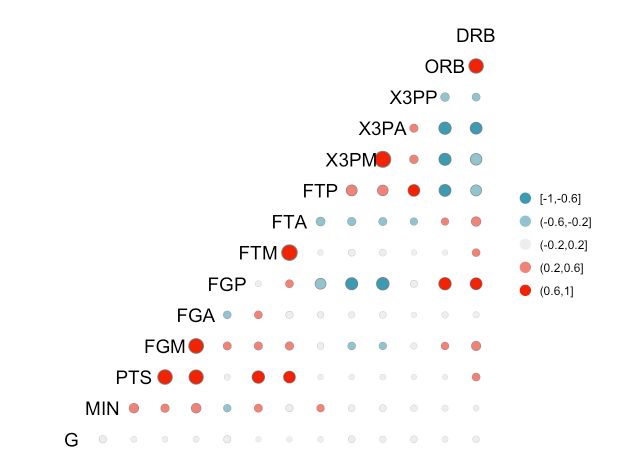
此外,用户可以通过min_size和max_size参数设置圆的最小和最大尺寸:
ggcorr(nba[, 2:15], geom = "circle", nbreaks = 5, min_size = 0, max_size = 6)
R语言学习 - 散点图绘制
Volcano plot | 别再问我这为什么是火山图
控制系数显示
ggcorr可以通过将label参数设置为TRUE来在相关矩阵的顶部显示相关系数:
ggcorr(nba[, 2:15], label = TRUE)
label_color和label_size参数允许设置系数标签的样式:
ggcorr(nba[, 2:15], nbreaks = 4, palette = "RdGy", label = TRUE, label_size = 3, label_color = "white")

label_round参数进一步控制系数标签中显示的位数(默认为一位数字),label_alpha参数控制标签的透明度。如果label_alpha设置为TRUE,则透明度级别将像相关系数一样变化,并且相关系数的绝对值越小,透明度越高:
ggcorr(nba[, 2:15], label = TRUE, label_size = 3, label_round = 2, label_alpha = TRUE)
控制变量标签
在上面的几个示例中,变量标签(在相关矩阵的对角线上显示)的呈现不一定是最佳的。要修改这些标签的外观,要做的就是将geom_text支持的任何参数直接传递给ggcorr。以下示例显示了如何在将标签向左移动并更改其颜色的同时减小标签的尺寸:
ggcorr(nba[, 2:15], hjust = 0.75, size = 5, color = "grey50")
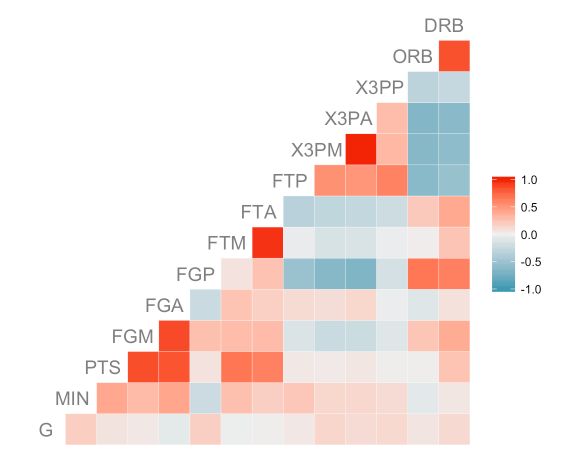
相关矩阵中的变量标签可能会出现的一个问题是,变量标签太长而无法在图的左下方完整显示。如下图:
ggcorr(nba[, 3:16], hjust = 0.75, size = 5, color = "grey50")
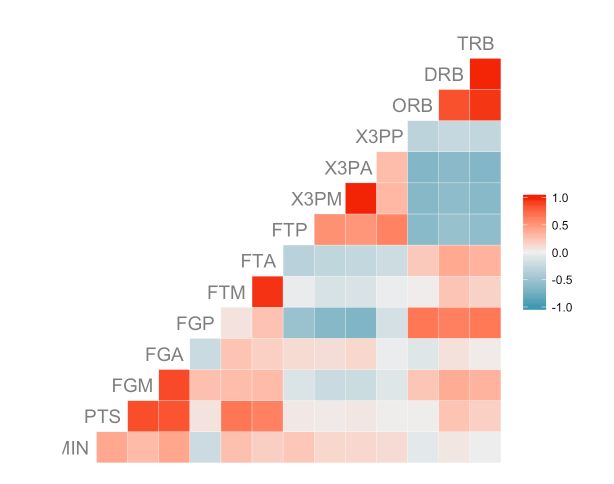
要解决此问题,ggcorr可以通过layout.exp参数在绘图的水平轴上添加一些空格,有助于显示长名称的变量:
ggcorr(nba[, 3:16], hjust = 0.75, size = 5, color = "grey50", layout.exp = 1)
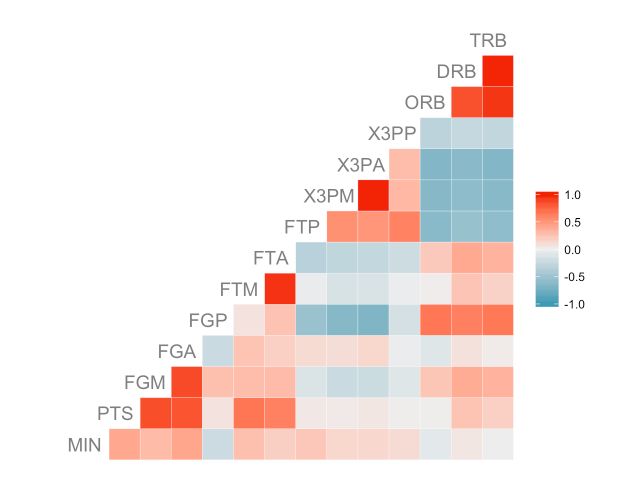
还等什么呢,快来试一试吧!
基因共表达聚类分析和可视化
SOM基因表达聚类分析初探
获取pheatmap聚类后和标准化后的结果
一文学会网络分析——Co-occurrence网络图在R中的实现
ggcor在微生物生态领域的使用实战
ggcor |相关系数矩阵可视化