前言
金九银十,又是一波跑路。趁着有空把前端基础和面试相关的知识点都系统的学习一遍,参考一些权威的书籍和优秀的文章,最后加上自己的一些理解,总结出来这篇文章。适合复习和准备面试的同学,其中的知识点包括:
- JavsScript
- 设计模式
- Vue
- 模块化
- 浏览器
- HTTP
- 前端安全
JavaScript
数据类型
String、Number、Boolean、Null、Undefined、Symbol、BigInt、Object
堆、栈
两者都是存放数据的地方。
栈(stack)是自动分配的内存空间,它存放基本类型的值和引用类型的内存地址。
堆(heap)是动态分配的内存空间,它存放引用类型的值。
JavaScript 不允许直接操作堆空间的对象,在操作对象时,实际操作是对象的引用,而存放在栈空间中的内存地址就起到指向的作用,通过内存地址找到堆空间中的对应引用类型的值。
隐式类型转换
JavaScript 作为一个弱类型语言,因使用灵活的原因,在一些场景中会对类型进行自动转换。
常见隐式类型转换场景有3种: 运算 、 取反 、 比较
运算
运算的隐式类型转换会将运算的成员转换为 number 类型。
基本类型转换:
true + false // 1
null + 10 // 10
false + 20 // 20
undefined + 30 // NaN
1 + '2' // "12"
NaN + '' // "NaN"
undefined + '' // "undefined"
null + '' // "null"
'' - 3 // -3
-
null、false、''转换number类型都是 0 -
undefined转换number类型是NaN,所以undefined和其他基本类型运算都会输出NaN - 字符串在加法运算(其实是字符串拼接)中很强势,和任何类型相加都会输出字符串(
symbol除外),即使是NaN、undefined。其他运算则正常转为number进行运算。
引用类型转换:
[1] + 10 // "110"
[] + 20 // "20"
[1,2] + 20 // "1,220"
[20] - 10 // 10
[1,2] - 10 // NaN
({}) + 10 // "[object Object]10"
({}) - 10 // NaN
- 引用类型运算时,会默认调用
toString先转换为string - 同上结论,除了加法都会输出字符串外,其他情况都是先转
string再转number
解析引用类型转换过程:
[1,2] + 20
// 过程:
[1,2].toString() // '1,2'
'1,2' + 20 // '1,220'[20] - 10
// 过程
[20].toString() // '20'
Number('20') // 20
20 - 10 // 10
取反
取反的隐式类型转换会将运算的成员转换为 boolean 类型。
这个隐式类型转换比较简单,就是将值转为布尔值再取反:
![] // false
!{} // false
!false // true
通常为了快速获得一个值的布尔值类型,可以取反两次:
!![] // true
!!0 // false
比较
比较分为 严格比较 === 和 非严格比较 == ,由于 === 会比较类型,不会进行类型转换。这里只讨论 == 。
比较的隐式类型转换基本会将运算的成员转换为 number 类型。
undefined == null // true
'' == 0 // true
true == 1 // true
'1' == true // true
[1] == '1' // true
[1,2] == '1,2' // true
({}) == '[object Object]' // true
-
undefined等于null - 字符串、布尔值、
null比较时,都会转number - 引用类型在隐式转换时会先转成
string比较,如果不相等然再转成number比较
预编译
预编译发生在 JavaScript 代码执行前,对代码进行语法分析和代码生成,初始化的创建并存储变量,为执行代码做好准备。
预编译过程:
undefined
例子:
function foo(x, y) {
console.log(x)
var x = 10
console.log(x)
function x(){}
console.log(x)
}
foo(20, 30)
// 1. 创建AO对象
AO {}
// 2. 寻找形参和变量声明赋值为 undefined
AO {
x: undefined
y: undefined
}
// 3. 实参形参相统一
AO {
x: 20
y: 30
}
// 4. 函数声明提升
AO {
x: function x(){}
y: 30
}
编译结束后代码开始执行,第一个 x 从 AO 中取值,输出是函数 x ; x 被赋值为 10,第二个 x 输出 10;函数 x 已被声明提升,此处不会再赋值 x ,第三个 x 输出 10。
作用域
作用域能保证对有权访问的所有变量和函数的有序访问,是代码在运行期间查找变量的一种规则。
函数作用域
函数在运行时会创建属于自己的作用域,将内部的变量和函数定义“隐藏”起来,外部作用域无法访问包装函数内部的任何内容。
块级作用域
在ES6之前创建块级作用域,可以使用 with 或 try/catch 。而在ES6引入 let 关键字后,让块级作用域声明变得更简单。 let 关键字可以将变量绑定到所在的任意作用域中(通常是{...}内部)。
{
let num = 10
}
console.log(num) // ReferenceError: num is not defined
参数作用域
一旦设置了参数的默认值,函数进行声明初始化时,参数会形成一个单独的作用域。等到初始化结束,这个作用域就会消失。这种语法行为,在不设置参数默认值时,是不会出现的。
let x = 1;function f(x, y = x) {
console.log(y);
}f(2) // 2
参数 y 的默认值等于变量 x 。调用函数f时,参数形成一个单独的作用域。在这个作用域里面,默认值变量x指向第一个参数 x ,而不是全局变量 x ,所以输出是2。
let x = 1;
function foo(x, y = function() { x = 2; }) {
x = 3;
y();
console.log(x);
}foo() // 2
x // 1
y 的默认是一个匿名函数,匿名函数内的 x 指向同一个作用域的第一个参数 x 。函数 foo 的内部变量 x 就指向第一个参数 x ,与匿名函数内部的 x 是一致的。 y 函数执行对参数 x 重新赋值,最后输出的就是2,而外层的全局变量 x 依然不受影响。
闭包
闭包的本质就是作用域问题。当函数可以记住并访问所在作用域,且该函数在所处作用域之外被调用时,就会产生闭包。
简单点说,一个函数内引用着所在作用域的变量,并且它被保存到其他作用域执行,引用变量的作用域并没有消失,而是跟着这个函数。当这个函数执行时,就可以通过作用域链查找到变量。
let bar
function foo() {
let a = 10
// 函数被保存到了外部
bar = function () {
// 引用着不是当前作用域的变量a
console.log(a)
}
}
foo()
// bar函数不是在本身所处的作用域执行
bar() // 10
优点:私有变量或方法、缓存
缺点:闭包让作用域链得不到释放,会导致内存泄漏
原型链
JavaScript 中的对象有一个特殊的内置属性 prototype (原型),它是对于其他对象的引用。当查找一个变量时,会优先在本身的对象上查找,如果找不到就会去该对象的 prototype 上查找,以此类推,最终以 Object.prototype 为终点。多个 prototype 连接在一起被称为原型链。
原型继承
原型继承的方法有很多种,这里不会全部提及,只记录两种常用的方法。
圣杯模式
function inherit(Target, Origin){
function F() {};
F.prototype = Origin.prototype;
Target.prototype = new F();
// 还原 constuctor
Target.prototype.constuctor = Target;
// 记录继承自谁
Target.prototype.uber = Origin.prototype;
}
圣杯模式的好处在于,使用中间对象隔离,子级添加属性时,都会加在这个对象里面,不会对父级产生影响。而查找属性是沿着 __proto__ 查找,可以顺利查找到父级的属性,实现继承。
使用:
function Person() {
this.name = 'people'
}
Person.prototype.sayName = function () { console.log(this.name) }
function Child() {
this.name = 'child'
}
inherit(Child, Person)
Child.prototype.age = 18
let child = new Child()
ES6 Class
class Person {
constructor() {
this.name = 'people'
}
sayName() {
console.log(this.name)
}
}
class Child extends Person {
constructor() {
super()
this.name = 'child'
}
}
Child.prototype.age = 18
let child = new Child()
Class 可以通过 extends 关键字实现继承,这比 ES5 的通过修改原型链实现继承,要清晰和方便很多。
基本包装类型
let str = 'hello'
str.split('')
基本类型按道理说是没有属性和方法,但是在实际操作时,我们却能从基本类型调用方法,就像一个字符串能调用 split 方法。
为了方便操作基本类型值,每当读取一个基本类型值的时候,后台会创建一个对应的基本包装类型的对象,从而让我们能够调用方法来操作这些数据。大概过程如下:
String
let str = new String('hello')
str.split('')
str = null
this
this 是函数被调用时发生的绑定,它指向什么完全取决于函数在哪里被调用。我理解的 this 是函数的调用者对象,当在函数内使用 this ,可以访问到调用者对象上的属性和方法。
this 绑定的四种情况:
- new 绑定。
new实例化 - 显示绑定。
call、apply、bind手动更改指向 - 隐式绑定。由上下文对象调用,如
obj.fn(),this指向obj - 默认绑定。默认绑定全局对象,在严格模式下会绑定到
undefined
优先级new绑定最高,最后到默认绑定。
new的过程
- 创建一个空对象
- 设置原型,将对象的
__proto__指向构造函数的prototype - 构造函数中的
this执行对象,并执行构造函数,为空对象添加属性和方法 - 返回实例对象
注意点:构造函数内出现 return ,如果返回基本类型,则提前结束构造过程,返回实例对象;如果返回引用类型,则返回该引用类型。
// 返回基本类型
function Foo(){
this.name = 'Joe'
return 123
this.age = 20
}
new Foo() // Foo {name: "Joe"}// 返回引用类型
function Foo(){
this.name = 'Joe'
return [123]
this.age = 20
}
new Foo() // [123]
call、apply、bind
三者作用都是改变 this 指向的。
call 和 apply 改变 this 指向并调用函数,它们两者区别就是传参形式不同,前者的参数是逐个传入,后者传入数组类型的参数列表。
bind 改变 this 并返回一个函数引用, bind 多次调用是无效的,它改变的 this 指向只会以第一次调用为准。
手写call
Function.prototype.mycall = function () {
if(typeof this !== 'function'){
throw 'caller must be a function'
}
let othis = arguments[0] || window
othis._fn = this
let arg = [...arguments].slice(1)
let res = othis._fn(...arg)
Reflect.deleteProperty(othis, '_fn') //删除_fn属性
return res
}
apply 实现同理,修改传参形式即可
手写bind
Function.prototype.mybind = function (oThis) {
if(typeof this != 'function'){
throw 'caller must be a function'
}
let fThis = this
//Array.prototype.slice.call 将类数组转为数组
let arg = Array.prototype.slice.call(arguments,1)
let NOP = function(){}
let fBound = function(){
let arg_ = Array.prototype.slice.call(arguments)
// new 绑定等级高于显式绑定
// 作为构造函数调用时,保留指向不做修改
// 使用 instanceof 判断是否为构造函数调用
return fThis.apply(this instanceof fBound ? this : oThis, arg.concat(arg_))
}
// 维护原型
if(this.prototype){
NOP.prototype = this.prototype
fBound.prototype = new NOP()
}
return fBound
}
对ES6语法的了解
常用:let、const、扩展运算符、模板字符串、对象解构、箭头函数、默认参数、Promise
数据结构:Set、Map、Symbol
其他:Proxy、Reflect
Set、Map、WeakSet、WeakMap
Set:
- 成员的值都是唯一的,没有重复的值,类似于数组
- 可以遍历
WeakSet:
- 成员必须为引用类型
- 成员都是弱引用,可以被垃圾回收。成员所指向的外部引用被回收后,该成员也可以被回收
- 不能遍历
Map:
- 键值对的集合,键值可以是任意类型
- 可以遍历
WeakMap:
- 只接受引用类型作为键名
- 键名是弱引用,键值可以是任意值,可以被垃圾回收。键名所指向的外部引用被回收后,对应键名也可以被回收
- 不能遍历
箭头函数和普通函数的区别
- 箭头函数的
this指向在编写代码时就已经确定,即箭头函数本身所在的作用域;普通函数在调用时确定this。 - 箭头函数没有
arguments - 箭头函数没有
prototype属性
Promise
Promise 是ES6中新增的异步编程解决方案,避免回调地狱问题。 Promise 对象是通过状态的改变来实现通过同步的流程来表示异步的操作, 只要状态发生改变就会自动触发对应的函数。
Promise 对象有三种状态,分别是:
- pending: 默认状态,只要没有告诉
promise任务是成功还是失败就是pending状态 - fulfilled: 只要调用
resolve函数, 状态就会变为fulfilled, 表示操作成功 - rejected: 只要调用
rejected函数, 状态就会变为rejected, 表示操作失败
状态一旦改变既不可逆,可以通过函数来监听 Promise 状态的变化,成功执行 then 函数的回调,失败执行 catch 函数的回调
浅拷贝
浅拷贝是值的复制,对于对象是内存地址的复制,目标对象的引用和源对象的引用指向的是同一块内存空间。如果其中一个对象改变,就会影响到另一个对象。
常用浅拷贝的方法:
- Array.prototype.slice
let arr = [{a:1}, {b:2}]
let newArr = arr1.slice()
- 扩展运算符
let newArr = [...arr1]
深拷贝
深拷贝是将一个对象从内存中完整的拷贝一份出来,对象与对象间不会共享内存,而是在堆内存中新开辟一个空间去存储,所以修改新对象不会影响原对象。
常用的深拷贝方法:
- JSON.parse(JSON.stringify())
JSON.parse(JSON.stringify(obj))
- 手写深拷贝
function deepClone(obj, map = new WeakMap()) {
if (obj === null || typeof obj !== "object") return obj;
const type = Object.prototype.toString.call(obj).slice(8, -1)
let strategy = {
Date: (obj) => new Date(obj),
RegExp: (obj) => new RegExp(obj),
Array: clone,
Object: clone
}
function clone(obj){
// 防止循环引用,导致栈溢出,相同引用的对象直接返回
if (map.get(obj)) return map.get(obj);
let target = new obj.constructor();
map.set(obj, target);
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
target[key] = deepClone(obj[key], map);
}
}
return target;
}
return strategy[type] && strategytype
}
事件委托
事件委托也叫做事件代理,是一种dom事件优化的手段。事件委托利用事件冒泡的机制,只指定一个事件处理程序,就可以管理某一类型的所有事件。
假设有个列表,其中每个子元素都会有个点击事件。当子元素变多时,事件绑定占用的内存将会成线性增加,这时候就可以使用事件委托来优化这种场景。代理的事件通常会绑定到父元素上,而不必为每个子元素都添加事件。
- 1
- 2
- 3
clickHandler(e) {
// 点击获取的子元素
let target = e.target
// 输出子元素内容
consoel.log(target.textContent)
}
防抖
防抖用于减少函数调用次数,对于频繁的调用,只执行这些调用的最后一次。
/**
- @param {function} func - 执行函数
- @param {number} wait - 等待时间
- @param {boolean} immediate - 是否立即执行
- @return {function}
*/
function debounce(func, wait = 300, immediate = false){
let timer, ctx;
let later = (arg) => setTimeout(()=>{
func.apply(ctx, arg)
timer = ctx = null
}, wait)
return function(...arg){
if(!timer){
timer = later(arg)
ctx = this
if(immediate){
func.apply(ctx, arg)
}
}else{
clearTimeout(timer)
timer = later(arg)
}
}
}
节流
节流用于减少函数请求次数,与防抖不同,节流是在一段时间执行一次。
/**
- @param {function} func - 执行函数
- @param {number} delay - 延迟时间
- @return {function}
*/
function throttle(func, delay){
let timer = null
return function(...arg){
if(!timer){
timer = setTimeout(()=>{
func.apply(this, arg)
timer = null
}, delay)
}
}
}
柯里化
Currying(柯里化)是把接受多个参数的函数变换成接受一个单一参数的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
通用柯里化函数:
function currying(fn, arr = []) {
let len = fn.length
return (...args) => {
let concatArgs = [...arr, ...args]
if (concatArgs.length < len) {
return currying(fn, concatArgs)
} else {
return fn.call(this, ...concatArgs)
}
}
}
使用:
let sum = (a,b,c,d) => {
console.log(a,b,c,d)
}
let newSum = currying(sum)
newSum(1)(2)(3)(4)
优点:
bind
垃圾回收
堆分为新生代和老生代,分别由副垃圾回收器和主垃圾回收器来负责垃圾回收。
新生代
一般刚使用的对象都会放在新生代,它的空间比较小,只有几十MB,新生代里还会划分出两个空间: form 空间和 to 空间。
对象会先被分配到 form 空间中,等到垃圾回收阶段,将 form 空间的存活对象复制到 to 空间中,对未存活对象进行回收,之后调换两个空间,这种算法称之为 “Scanvage”。
新生代的内存回收频率很高、速度也很快,但空间利用率较低,因为让一半的内存空间处于“闲置”状态。
老生代
老生代的空间较大,新生代经过多次回收后还存活的对象会被送到老生代。
老生代使用“标记清除”的方式,从根元素开始遍历,将存活对象进行标记。标记完成后,对未标记的对象进行回收。
经过标记清除之后的内存空间会产生很多不连续的碎片空间,导致一些大对象无法存放进来。所以在回收完成后,会对这些不连续的碎片空间进行整理。
JavaScript设计模式
单例模式
定义:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
JavaScript 作为一门无类的语言,传统的单例模式概念在 JavaScript 中并不适用。稍微转换下思想:单例模式确保只有一个对象,并提供全局访问。
常见的应用场景就是弹窗组件,使用单例模式封装全局弹窗组件方法:
import Vue from 'vue'
import Index from './index.vue'let alertInstance = null
let alertConstructor = Vue.extend(Index)let init = (options)=>{
alertInstance = new alertConstructor()
Object.assign(alertInstance, options)
alertInstance.el)
}let caller = (options)=>{
// 单例判断
if(!alertInstance){
init(options)
}
return alertInstance.show(()=>alertInstance = null)
}export default {
install(vue){
vue.prototype.$alert = caller
}
}
无论调用几次,组件也只实例化一次,最终获取的都是同一个实例。
策略模式
定义:定义一系列的算法,把它们一个个封装起来,并且使它们可以相互替换。
策略模式是开发中最常用的设计模式,在一些场景下如果存在大量的 if/else,且每个分支点的功能独立,这时候就可以考虑使用策略模式来优化。
就像就上面手写深拷贝就用到策略模式来实现:
function deepClone(obj, map = new WeakMap()) {
if (obj === null || typeof obj !== "object") return obj;
const type = Object.prototype.toString.call(obj).slice(8, -1)
// 策略对象
let strategy = {
Date: (obj) => new Date(obj),
RegExp: (obj) => new RegExp(obj),
Array: clone,
Object: clone
}
function clone(obj){
// 防止循环引用,导致栈溢出,相同引用的对象直接返回
if (map.get(obj)) return map.get(obj);
let target = new obj.constructor();
map.set(obj, target);
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
target[key] = deepClone(obj[key], map);
}
}
return target;
}
return strategy[type] && strategytype
}
这样的代码看起来会更简洁,只需要维护一个策略对象,需要新功能就添加一个策略。由于策略项是单独封装的方法,也更易于复用。
代理模式
定义:为一个对象提供一个代用品,以便控制对它的访问。
当不方便直接访问一个对象或者不满足需要的时候,提供一个代理对象来控制对这个对象的访问,实际访问的是代理对象,代理对象对请求做出处理后,再转交给本体对象。
使用缓存代理请求数据:
function getList(page) {
return this.$api.getList({
page
}).then(res => {
this.list = res.data
return res
})
}
// 代理getList
let proxyGetList = (function() {
let cache = {}
return async function(page) {
if (cache[page]) {
return cache[page]
}
let res = await getList.call(this, page)
return cache[page] = res.data
}
})()
上面的场景是常见的分页需求,同一页的数据只需要去后台获取一次,并将获取到的数据缓存起来,下次再请求同一页时,便可以直接使用之前的数据。
发布订阅模式
定义:它定义对象间的一种一对多的依赖关系,当一个对象的状态发送改变时,所有依赖于它的对象都将得到通知。
发布订阅模式主要优点是解决对象间的解耦,它的应用非常广泛,既可以用在异步编程中,也可以帮助我们完成松耦合的代码编写。像 eventBus 的通信方式就是发布订阅模式。
let event = {
events: [],
on(key, fn){
if(!this.events[key]) {
this.events[key] = []
}
this.events[key].push(fn)
},
emit(key, ...arg){
let fns = this.events[key]
if(!fns || fns.length == 0){
return false
}
fns.forEach(fn => fn.apply(this, arg))
}
}
上面只是发布订阅模式的简单实现,还可以为其添加 off 方法来取消监听事件。在 Vue 中,通常是实例化一个新的 Vue 实例来做发布订阅中心,解决组件通信。而在小程序中可以手动实现发布订阅模式,用于解决页面通信的问题。
装饰器模式
定义:动态地为某个对象添加一些额外的职责,而不会影响对象本身。
装饰器模式在开发中也是很常用的设计模式,它能够在不影响源代码的情况下,很方便的扩展属性和方法。比如以下应用场景是提交表单。
methods: {
submit(){
this.$api.submit({
data: this.form
})
},
// 为提交表单添加验证功能
validateForm(){
if(this.form.name == ''){
return
}
this.submit()
}
}
想象一下,如果你刚接手一个项目,而 submit 的逻辑很复杂,可能还会牵扯到很多地方。冒然的侵入源代码去扩展功能会有风险,这时候装饰器模式就帮上大忙了。
Vue
对MVVM模式的理解
MVVM 对应 3个组成部分,Model(模型)、View(视图) 和 ViewModel(视图模型)。
- View 是用户在屏幕上看到的结构、布局和外观,也称UI。
- ViewModel 是一个绑定器,能和 View 层和 Model 层进行通信。
- Model 是数据和逻辑。
View 不能和 Model 直接通信,它们只能通过 ViewModel 通信。Model 和 ViewModel 之间的交互是双向的,ViewModel 通过双向数据绑定把 View 层和 Model 层连接起来,因此 View 数据的变化会同步到 Model 中,而 Model 数据的变化也会立即反应到 View 上。
题外话,你可能不知道 Vue 不完全是 MVVM 模式:
严格的 MVVM 要求 View 不能和 Model 直接通信,而 Vue 在组件提供了 $refs 这个属性,让 Model 可以直接操作 View,违反了这一规定。
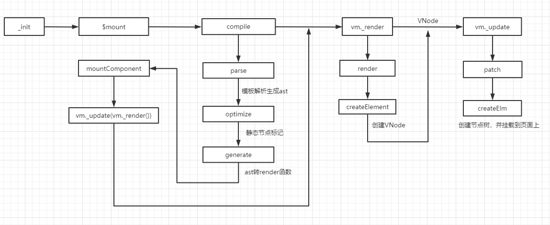
Vue的渲染流程
流程主要分为三个部分:
- 模板编译 ,
parse解析模板生成抽象语法树(AST);optimize标记静态节点,在后续页面更新时会跳过静态节点;generate将AST转成render函数,render函数用于构建VNode。 - 构建VNode(虚拟dom) ,构建过程使用
createElement构建VNode,createElement也是自定义render函数时接受到的第一个参数。 - VNode转真实dom ,
patch函数负责将VNode转换成真实dom,核心方法是createElm,递归创建真实dom树,最终渲染到页面上。
data为什么要求是函数
当一个组件被定义,data 必须声明为返回一个初始数据对象的函数,因为组件可能被用来创建多个实例。如果 data 仍然是一个纯粹的对象,则所有的实例将共享引用同一个数据对象!通过提供 data 函数,每次创建一个新实例后,我们能够调用 data 函数,从而返回初始数据的一个全新副本数据对象。
JavaScript 中的对象作为引用类型,如果是创建多个实例,直接使用对象会导致实例的共享引用。而这里创建多个实例,指的是组件复用的情况。因为在编写组件时,是通过 export 暴露出去的一个对象,如果组件复用的话,多个实例都是引用这个对象,就会造成共享引用。使用函数返回一个对象,由于是不同引用,自然可以避免这个问题发生。
Vue生命周期
- beforeCreate: 在实例创建之前调用,由于实例还未创建,所以无法访问实例上的
data、computed、method等。 - created: 在实例创建完成后调用,这时已完成数据的观测,可以获取数据和更改数据,但还无法与dom进行交互,如果想要访问dom,可以使用
vm.$nextTick。此时可以对数据进行更改,不会触发updated。 - beforeMount: 在挂载之前调用,这时的模板已编译完成并生成
render函数,准备开始渲染。在此时也可以对数据进行更改,不会触发updated。 - mounted: 在挂载完成后调用,真实的dom挂载完毕,可以访问到dom节点,使用
$refs属性对dom进行操作。 - beforeUpdate: 在更新之前调用,也就是响应式数据发生更新,虚拟dom重新渲染之前被触发,在当前阶段进行更改数据,不会造成重渲染。
- updated: 在更新完成之后调用,组件dom已完成更新。要注意的是避免在此期间更改数据,这可能会导致死循环。
- beforeDestroy: 在实例销毁之前调用,这时实例还可以被使用,一般这个周期内可以做清除计时器和取消事件监听的工作。
- destroyed: 在实例销毁之后调用,这时已无法访问实例。当前实例从父实例中被移除,观测被卸载,所有事件监听器呗移除,子实例也统统被销毁。
请说出 Vue 的5种指令
v-if
v-for
v-show
v-html
v-model
computed 和 watch 的区别
-
computed依赖data的改变而改变,computed会返回值;watch观察data,执行对应的函数。 -
computed有缓存功能,重复取值不会执行求值函数。 -
computed依赖收集在页面渲染时触发,watch收集依赖在页面渲染前触发。 -
computed更新需要“渲染Watcher”的配合,computed更新只是设置dirty,需要页面渲染触发get重新求值
Vue 中的 computed 是如何实现缓存的
“计算属性 Watcher ”会带有一个 dirty 的属性,在初始化取值完成后,会将 dirty 设置为 false 。只要依赖属性不更新, dirty 永远为 false ,重复取值也不会再去执行求值函数,而是直接返回结果,从而实现缓存。相反,依赖属性更新会将“计算属性 Watcher ”的 dirty 设置为 true ,在页面渲染对计算属性取值时,再次触发求值函数更新计算属性。
Object.defineProperty(target, key, {
get() {
const watcher = this._computedWatchers && this._computedWatchers[key]
// 计算属性缓存
if (watcher.dirty) {
// 计算属性求值
watcher.evaluate()
}
return watcher.value
}
})
组件通信方式
- props/emit
- parent
- ref
- listeners
- provide/inject
- eventBus
- vuex
双向绑定原理
双向绑定是视图变化会反映到数据,数据变化会反映到视图, v-model 就是个很好理解的例子。其实主要考查的还是响应式原理,响应式原理共包括3个主要成员, Observer 负责监听数据变化, Dep 负责依赖收集, Watcher 负责数据或视图更新,我们常说的收集依赖就是收集 Watcher 。
响应式原理主要工作流程如下:
-
Observer内使用Object.defineProperty劫持数据,为其设置set和get。 - 每个数据都会有自己的
dep。数据取值触发get函数,调用dep.depend收集依赖;数据更新触发set函数,调用dep.notify通知Watcher更新。 -
Watcher接收到更新的通知,将这些通知加入到一个异步队列中,并且进行去重处理,等到所有同步操作完成后,再一次性更新视图。
Vue如何检测数组变化
Vue 内部重写数组原型链,当数组发生变化时,除了执行原生的数组方法外,还会调用 dep.notify 通知 Watcher 更新。触发数组更新的方法共7种:
push
pop
shift
unshift
splice
sort
reverse
keep-alive
keep-alive 是 Vue 的内置组件,同时也是一个抽象组件,它主要用于组件缓存。当组件切换时会将组件的 VNode 缓存起来,等待下次重新激活时,再将缓存的组件 VNode 渲染出来,从而实现缓存。
常用的两个属性 include 和 exclude ,支持字符串、正则和数组的形式,允许组件有条件的进行缓存。还有 max 属性,用于设置最大缓存数。
两个生命周期 activated 和 deactivated ,在组件激活和失活时触发。
keep-alive 的缓存机制运用LRU(Least Recently Used)算法,
nextTick
在下次 dom 更新结束之后执行延迟回调。 nextTick 主要使用了宏任务和微任务。根据执行环境分别尝试采用:
- Promise
- MutationObserver
- setImmediate
- setTimeout
nextTick 主要用于内部 Watcher 的异步更新,对外我们可以使用 Vue.nextTick 和 vm.$nextTick 。在 nextTick 中可以获取更新完成的 dom。
如何理解单向数据流
所有的 prop 都使得其父子 prop 之间形成了一个单向下行绑定:父级 prop 的更新会向下流动到子组件中,但是反过来则不行。这样会防止从子组件意外变更父级组件的状态,从而导致你的应用的数据流向难以理解。
单向数据流只允许数据由父组件传递给子组件,数据只能由父组件更新。当数据传递到多个子组件,而子组件能够在其内部更新数据时,在主观上很难知道是哪个子组件更新了数据,导致数据流向不明确,从而增加应用调试的难度。
但子组件更新父组件数据的场景确实存在,有3种方法可以使用:
- 子组件emit,父组件接受自定义事件。这种方法最终还是由父组件进行修改,子组件只是起到一个通知的作用。
- 子组件自定义双向绑定,设置组件的
model选项为组件添加自定义双向绑定。 -
.sync属性修饰符,它是第一种方法的语法糖,在传递属性添加上该修饰符,子组件内可调用this.$emit('update:属性名', value)更新属性。
Vue3 和 Vue2.x 的差异
- 使用
Proxy代替Object.defineProperty - 新增
Composition API - 模板允许多个根节点
Vue3 为什么使用 Proxy 代替 Object.definedProperty
Object.definedProperty 只能检测到属性的获取和设置,对于新增和删除是没办法检测的。在数据初始化时,由于不知道哪些数据会被用到, Vue 是直接递归观测全部数据,这会导致性能多余的消耗。
Proxy 劫持整个对象,对象属性的增加和删除都能检测到。 Proxy 并不能监听到内部深层的对象变化,因此 Vue 3.0 的处理方式是在 getter 中去递归响应式,只有真正访问到的内部对象才会变成响应式,而不是无脑递归,在很大程度上提升了性能。
路由懒加载是如何实现的
路由懒加载是性能优化的一种手段,在编写代码时可以使用 import() 引入路由组件,使用懒加载的路由会在打包时单独出来成一个 js 文件,可以使用 webpackChunkName 自定义包名。在项目上线后,懒加载的 js 文件不会在第一时间加载,而是在访问到对应的路由时,才会动态创建 script 标签去加载这个 js 文件。
{
path:'users',
name:'users',
component:()=> import(/webpackChunkName: "users"/ '@/views/users'),
}
Vue路由钩子函数
全局钩子
- beforeEach
路由进入前调用
const router = new VueRouter({ ... })
router.beforeEach((to, from, next) => {
// ...
})
- beforeResolve (2.5.0 新增)
在所有组件内守卫和异步组件被解析之后调用
router.beforeResolve((to, from, next) => {
// ...
})
- afterEach
路由在确认后调用
router.afterEach((to, from) => {
// ...
})
路由独享钩子
- beforeEnter
路由进入前调用, beforeEnter 在 beforeEach 之后执行
const router = new VueRouter({
routes: [
{
path: '/foo',
component: Foo,
beforeEnter: (to, from, next) => {
// ...
}
}
]
})
组件钩子
- beforeRouteEnter
路由确认前调用,组件实例还没被创建,不能获取组件实例 this
beforeRouteEnter (to, from, next) {
// ...
// 可以通过回调访问实例
next(vm => {
// vm 为组件实例
})
},
- beforeRouteUpdate (2.2 新增)
路由改变时调用,可以访问组件实例
beforeRouteUpdate (to, from, next) {
// ...
},
- beforeRouteLeave
离开该组件的对应路由时调用,可以访问组件实例 this
beforeRouteLeave (to, from, next) {
// ...
}
vue-router的原理
vue-router原理是更新视图而不重新请求页面。vue-router共有3种模式: hash模式 、 history模式 、 abstract模式 。
hash模式
hash模式使用 hashchange 监听地址栏的hash值的变化,加载对应的页面。每次的hash值变化后依然会在浏览器留下历史记录,可以通过浏览器的前进后退按钮回到上一个页面。
history模式
history模式基于History Api实现,使用 popstate 监听地址栏的变化。使用 pushState 和 replaceState 修改url,而无需加载页面。但是在刷新页面时还是会向后端发起请求,需要后端配合将资源定向回前端,交由前端路由处理。
abstract
不涉及和浏览器地址的相关记录。通过数组维护模拟浏览器的历史记录栈。
vuex 怎么跨模块调用
跨模块调用是指当前命名空间模块调用全局模块或者另一个命名空间模块。在调用 dispatch 和 commit 时设置第三个参数为 {root:true} 。
modules: {
foo: {
namespaced: true,
actions: {
someAction ({ dispatch, commit, getters, rootGetters }) {
// 调用自己的action
dispatch('someOtherAction') // -> 'foo/someOtherAction'
// 调用全局的action
dispatch('someOtherAction', null, { root: true }) // -> 'someOtherAction'
// 调用其他模块的action
dispatch('user/someOtherAction', null, { root: true }) // -> 'user/someOtherAction'
},
someOtherAction (ctx, payload) { ... }
}
}
}
vuex 如何实现持久化
vuex存储的状态在页面刷新后会丢失,使用持久化技术能保证页面刷新后状态依然存在。
- 使用本地存储配合,设置 state 同时设置 storage,在刷新后再初始化 vuex
- vuex-persistedstate 插件
模块化
这里只记录常用的两种模块:CommonJS模块、ES6模块。
CommonJS模块
Node.js 采用 CommonJS 模块规范,在服务端运行时是同步加载,在客户端使用需要编译后才可以运行。
特点
- 模块可以多次加载。但在第一次加载时,结果会被缓存起来,再次加载模块,直接获取缓存的结果
- 模块加载的顺序,按照其在代码中出现的顺序
语法
- 暴露模块:
module.exports = value或exports.xxx = value - 引入模块:
require('xxx'),如果是第三方模块,xxx为模块名;如果是自定义模块,xxx为模块文件路径 - 清楚模块缓存:
delete require.cache[moduleName];,缓存保存在require.cache中,可操作该属性进行删除
模块加载机制
- 加载某个模块,其实是加载该模块的
module.exports属性 -
exports是指向module.exports的引用 -
module.exports的初始值为一个空对象,exports也为空对象,module.exports对象不为空的时候exports对象就被忽略 - 模块加载的是值的拷贝,一旦输出值,模块内的变化不会影响到值,引用类型除外
module.exports 不为空:
// nums.js
exports.a = 1
module.exports = {
b: 2
}
exports.c = 3
let nums = require('./nums.js') // { b: 2 }
module.exports 为空:
// nums.js
exports.a = 1
exports.c = 3
let nums = require('./nums.js') // { a: 1, c: 3 }
值拷贝的体现:
// nums.js
let obj = {
count: 10
}
let count = 20
function addCount() {
count++
}
function getCount() {
return count
}
function addObjCount() {
obj.count++
}
module.exports = { count, obj, addCount, getCount, addObjCount }
let { count, obj, addCount, getCount, addObjCount } = require('./nums.js')
// 原始类型不受影响
console.log(count) // 20
addCount()
console.log(count) // 20
// 如果想获取到变化的值,可以使用函数返回
console.log(getCount()) // 21
// 引用类型会被改变
console.log(obj) // { count: 10 }
addObjCount()
console.log(obj) // { count: 11 }
ES6模块
ES6 模块的设计思想是尽量的静态化,使得编译时就能确定模块的依赖关系,以及输入和输出的变量。
特点
- 由于静态分析的原因,ES6模块加载只能在代码顶层使用
- 模块不能多次加载同一个变量
语法
- 暴露模块:
export或export default - 引入模块:
import
模块加载机制
- 模块加载的是引用的拷贝,模块内的变化会影响到值
// nums.js
export let count = 20
export function addCount() {
count++
}
export default {
other: 30
}
// 同时引入 export default 和 export 的变量
import other, { count, addCount } from './async.js'console.log(other) // { other: 30 }
console.log(count) // 20
addCount()
console.log(count) // 21
ES6 模块与 CommonJS 模块的差异
- CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
- CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
浏览器
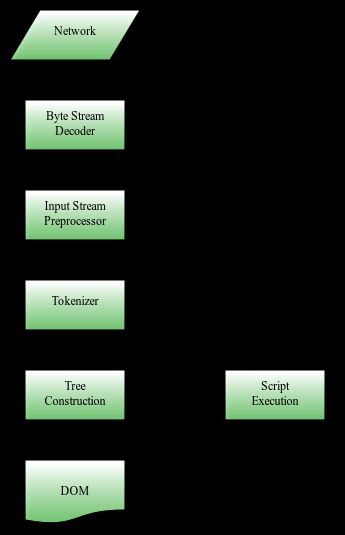
页面渲染流程
- 字节流解码 。浏览器获得字节数据,根据字节编码将字节流解码,转换为代码。
- 输入流预处理 。字符数据进行统一格式化。
- 令牌化 。从输入流中提取可识别的子串和标记符号。可以理解为对HTML解析,进行词法分析,匹配标签生成令牌结构。
- 构建DOM树、构建CSSOM树 。DOM树和CSSOM树的构建过程是同时进行的,在 HTML 解析过程中如果遇到 script 标签,解析会暂停并将执行权限交给 JavaScript 引擎,等到 JavaScript 脚本执行完毕后再交给渲染引擎继续解析。(补充:如果脚本中调用了改变 DOM 结构的 document.write() 函数,此时渲染引擎会回到第二步,将这些代码加入字符流,重新进行解析。)
- 构建渲染树 。DOM树负责结构内容,CSSOM树负责样式规则,为了渲染,需要将它们合成渲染树。
- 布局 。布局阶段根据渲染树的节点和节点的CSS定义以及节点从属关系,计算元素的大小和位置,将所有相对值转换为屏幕上的绝对像素。
- 绘制 。绘制就是将渲染树中的每个节点转换成屏幕上的实际像素的过程。在绘制阶段,浏览器会遍历渲染树,调用渲染器的paint方法在屏幕上显示其内容。实际上,绘制过程是在多个层上完成的,这些层称为渲染层(RenderLayer)。
- 渲染层合成 。多个绘制后的渲染层按照恰当的重叠顺序进行合并,而后生成位图,最终通过显卡展示到屏幕上。
数据变化过程:字节 → 字符 → 令牌 → 树 → 页面
回流、重绘
回流(Reflow)
在布局完成后,对DOM布局进行修改(比如大小或位置),会引起页面重新计算布局,这个过程称为“回流”。
重绘(Repaint)
对DOM进行不影响布局的修改引起的屏幕局部绘制(比如背景颜色、字体颜色),这个过程称为“重绘”。
小结
回流一定会引起重绘,而重绘不一定会引起回流。由于回流需要重新计算节点布局,回流的渲染耗时会高于重绘。
对于回流重绘,浏览器本身也有优化策略,浏览器会维护一个队列,将回流重绘操作放入队列中,等队列到达一定时间,再按顺序去一次性执行队列的操作。
但是也有例外,有时我们需要获取某些样式信息,例如:
offsetTop , offsetLeft , offsetWidth , offsetHeight , scrollTop/Left/Width/Height , clientTop/Left/Width/Height , getComputedStyle() ,或者 IE 的 currentStyle 。
这时,浏览器为了反馈准确的信息,需要立即回流重绘一次,所以可能导致队列提前执行。
事件循环(Event Loop)
在浏览器的实现上,诸如渲染任务、JavaScript 脚本执行、User Interaction(用户交互)、网络处理都跑在同一个线程上,当执行其中一个类型的任务的时候意味着其他任务的阻塞,为了有序的对各个任务按照优先级进行执行浏览器实现了我们称为 Event Loop 调度流程。
简单来说,Event Loop 就是执行代码、收集和处理事件以及执行队列中子任务的一个过程。
宏任务
在一次新的事件循环的过程中,遇到宏任务时,宏任务将被加入任务队列,但需要等到下一次事件循环才会执行。
常见宏任务: setTimeout 、 setInterval 、 requestAnimationFrame
微任务
当前事件循环的任务队列为空时,微任务队列中的任务就会被依次执行。在执行过程中,如果遇到微任务,微任务被加入到当前事件循环的微任务队列中。简单来说,只要有微任务就会继续执行,而不是放到下一个事件循环才执行。
微任务队列属于任务运行环境内的一员,并非处于全局的位置。也就是说,每个任务都会有一个微任务队列。
常见微任务: Promise.then 、 Promise.catch 、 MutationObserver
流程
- 取出一个宏任务执行,如果碰到宏任务,将其放入任务队列,如果碰到微任务,将其放入微任务队列
- 检查微任务队列是否有可执行的微任务,如果有则执行微任务。微任务执行过程中,如果碰到宏任务,将其放入任务队列。如果碰到微任务,继续将其放入当前的微任务队列,直到微任务全部执行。
- 更新渲染阶段,判断是否需要渲染,也就是说不一定每一轮
Event Loop都会对应一次浏览器渲染。 - 对于需要渲染的文档,执行
requestAnimationFrame帧动画回调。 - 对于需要渲染的文档,重新渲染绘制用户界面。
- 判断任务队列和微任务队列是否为空,如果是,则进行
Idle空闲周期的算法,判断是否要执行requestIdleCallback的回调函数。
小结
在当前任务运行环境内,微任务总是先于宏任务执行;
requestAnimationFrame 回调在页面渲染之前调用,适合做动画;
requestIdleCallback 在渲染屏幕之后调用,可以使用它来执行一些不太重要的任务。
同源策略(Same origin policy)
源是由 URL 中协议、主机名(域名)以及端口共同组成的部分。
同源策略是浏览器的行为,为了保护本地数据不被JavaScript代码获取回来的数据污染,它是存在于浏览器最核心也最基本的安全功能。
所谓同源指的是:协议、域名、端口号必须一致,只要有一个不相同,那么就是“跨源”。
最常见的同源策略是因为域名不同,也就是常说的“跨域”。一般分为请求跨域和页面跨域。
请求跨域解决方案
- 跨域资源共享(CORS) 。服务端设置HTTP响应头(Access-Control-Allow-Origin)
- 代理转发 。同源策略只存在于浏览器,使用服务端设置代理转发没有同源策略的限制。
- JSONP 。依赖的是 script 标签跨域引用 js 文件不会受到浏览器同源策略的限制。
- Websocket 。HTML5 规范提出的一个应用层的全双工协议,适用于浏览器与服务器进行实时通信场景。
常用方法是CORS和代理转发。
页面跨域解决方案
- postMessage 。HTML5 的 postMessage 方法可用于两个页面之间通信,而且不论这两个页面是否同源。
- document.domain 。对于主域名相同,子域名不同的情况,可以通过修改 document.domain 的值来进行跨域。
- window.location.hash ,通过 url 带 hash ,通过一个非跨域的中间页面来传递数据。
- window. name ,当 window 的 location 变化,然后重新加载,它的 name 属性可以依然保持不变。通过 iframe 的 src 属性由外域转向本地域,跨域数据即由 iframe 的 window. name 从外域传递到本地域。
CORS请求
对于CORS请求,浏览器将其分成两个类型:简单请求和非简单请求。
简单请求
简单请求符合下面 2 个特征:
请求方法为 GET、POST、HEAD。
-
请求头只能使用以下规定的安全字段:
- Accept(浏览器能够接受的响应内容类型)
- Accept-Language(浏览器能够接受的自然语言列表)
- Content-Type (请求对应的类型,只限于 text/plain、multipart/form-data、application/x-www-form-urlencode)
- Content-Language(浏览器希望采用的自然语言)
- Save-Data
- DPR
- DownLink
- Viewport-Width
- Width
非简单请求
任意一条要求不符合的即为非简单请求。常见是自定义 header ,例如将 token 设置到请求头。
在处理非简单请求时,浏览器会先发出“预检请求”,预检请求为OPTIONS方法,以获知服务器是否允许该实际请求,避免跨域请求对服务器产生预期外的影响。如果预检请求返回200允许通过,才会发真实的请求。
预检请求并非每次都需要发送,可以使用 Access-Control-Max-Age 设置缓存时间进行优化,减少请求发送。
HTTP
HTTP 1.0、HTTP 1.1、HTTP 2.0的区别
HTTP1.0
增加头部设定,头部内容以键值对的形式设置。请求头部通过 Accept 字段来告诉服务端可以接收的文件类型,响应头部再通过 Content-Type 字段来告诉浏览器返回文件的类型。
HTTP1.1
HTTP1.0中每次通信都需要经历建立连接、传输数据和断开连接三个阶段,这会增加大量网络开销。
HTTP1.1增加持久化连接,即连接传输完毕后,TCP连接不会马上关闭,而是其他请求可以复用连接。这个连接保持到浏览器或者服务器要求断开连接为止。
HTTP2.0
HTTP1.1虽然减少连接带来的性能消耗,但是请求最大并发受到限制,同一域下的HTTP连接数根据浏览器不同有所变化,一般是6 ~ 8个。而且一个TCP连接同一时刻只能处理一个请求,当前请求未结束之前,其他请求只能处于阻塞状态。
HTTP2.0中增加“多路复用”的机制,不再受限于浏览器的连接数限制。基于二进制分帧,客户端发送的数据会被分割成带有编号的碎片(二进制帧),然后将这些碎片同时发送给服务端,服务端接收到数据后根据编号再合并成完整的数据。服务端返回数据也同样遵循这个过程。
三次握手
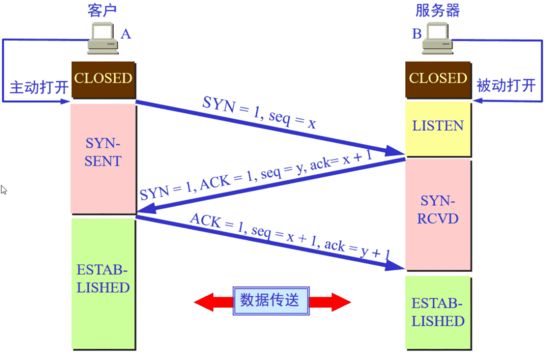
过程
第一次握手:客户端向服务端发起连接请求报文,报文中带有一个连接标识(SYN);
第二次握手:服务端接收到客户端的报文,发现报文中有连接标识,服务端知道是一个连接请求,于是给客户端回复确认报文(带有SYN标识);
第三次握手:客户端收到服务端回复确认报文,得知服务端允许连接,于是客户端回复确认报文给服务端,服务端收到客户端的回复报文后,正式建立TCP连接;
为什么需要三次握手,两次可以吗?
如果是两次握手,在第二次握手出现确认报文丢失,客户端不知道服务端是否准备好了,这种情况下客户端不会给服务端发数据,也会忽略服务端发过来的数据。
如果是三次握手,在第三次握手出现确认报文丢失,服务端在一段时间没有收到客户端的回复报文就会重新第二次握手,客户端收到重复的报文会再次给服务端发送确认报文。
三次握手主要考虑是丢包重连的问题。
四次挥手
[图片上传失败...(image-ffae32-1599296116870)]
过程
第一次挥手:客户端向服务端发出连接释放报文,报文中带有一个连接释放标识(FIN)。此时客户端不能再发送数据,但是可以正常接收数据;
第二次挥手:服务端接收到客户端的报文,知道是一个连接释放请求。服务端给客户端回复确认报文,但要注意这个回复报文未带有FIN标识。此时服务端处于关闭等待状态,这个状态还要持续一段时间,因为服务端可能还有数据没发完;
第三次挥手:服务端将最后的数据发送完毕后,给客户端回复确认报文(带有FIN标识),这个才是通知客户端可以释放连接的报文;
第四次挥手:客户端收到服务端回复确认报文后,于是客户端回复确认报文给服务端。而服务端一旦收到客户端发出的确认报文就会立马释放TCP连接,所以服务端结束TCP连接的时间要比客户端早一些。
为什么握手需要三次,而挥手需要四次
服务端需要确保数据完整性,只能先回复客户端确认报文告诉客户端我收到了报文,进入关闭等待状态。服务端在数据发送完毕后,才回复FIN报文告知客户端数据发送完了,可以断开了,由此多了一次挥手过程。
HTTPS
HTTPS之所以比HTTP安全,是因为对传输内容加密。HTTPS加密使用对称加密和非对称加密。
对称加密:双方共用一把钥匙,可以对内容双向加解密。但是只要有人和服务器通信就能获得密钥,也可以解密其他通信数据。所以相比非对称加密,安全性较低,但是它的效率比非对称加密高。
非对称加密:非对称加密会生成公钥和私钥,一般是服务端持有私钥,公钥向外公开。非对称加密对内容单向加解密,即公钥加密只能私钥解,私钥加密只能公钥解。非对称加密安全性虽然高,但是它的加解密效率很低。
CA证书:由权威机构颁发,用于验证服务端的合法性,其内容包括颁发机构信息、公钥、公司信息、域名等。
对称加密不安全主要是因为密钥容易泄露,那只要保证密钥的安全,就可以得到两全其美的方案,加解密效率高且安全性好。所以HTTPS在传输过程中,对内容使用对称加密,而密钥使用非对称加密。
[图片上传失败...(image-b3dd19-1599296116870)]
过程
- 客户端向服务端发起HTTPS请求
- 服务端返回HTTPS证书
- 客户端验证证书是否合法,不合法会提示告警
- 证书验证合法后,在本地生成随机数
- 用公钥加密随机数并发送到服务端
- 服务端使用私钥对随机数解密
- 服务端使用随机数构造对称加密算法,对内容加密后传输
- 客户端收到加密内容,使用本地存储的随机数构建对称加密算法进行解密
HTTP 缓存
HTTP 缓存包括强缓存和协商缓存,强缓存的优先级高于协商缓存。缓存优点在于使用浏览器缓存,对于某些资源服务端不必重复发送,减小服务端的压力,使用缓存的速度也会更快,从而提高用户体验。
强缓存
强缓存在浏览器加载资源时,先从缓存中查找结果,如果不存在则向服务端发起请求。
Expirss
HTTP/1.0 中可以使用响应头部字段 Expires 来设置缓存时间。
客户端第一次请求时,服务端会在响应头部添加 Expirss 字段,浏览器在下一次发送请求时,会对比时间和Expirss的时间,没有过期使用缓存,过期则发送请求。
Cache-Control
HTTP/1.1 提出了 Cache-Control 响应头部字段。
一般会设置 max-age 的值,表示该资源需要缓存多长时间。Cache-Control 的 max-age 优先级高于 Expires。
协商缓存
协商缓存的更新策略是不再指定缓存的有效时间,而是浏览器直接发送请求到服务端进行确认缓存是否更新,如果请求响应返回的 HTTP 状态为 304,则表示缓存仍然有效。
Last-Modified 和 If-Modified-Since
Last-Modified 和 If-Modified-Since 对比资源最后修改时间来实现缓存。
- 浏览器第一次请求资源,服务端在返回资源的响应头上添加 Last-Modified 字段,值是资源在服务端的最后修改时间;
- 浏览器再次请求资源,在请求头上添加 If-Modified-Since,值是上次服务端返回的最后修改时间;
- 服务端收到请求,根据 If-Modified-Since 的值进行判断。若资源未修改过,则返回 304 状态码,并且不返回内容,浏览器使用缓存;否则返回资源内容,并更新 Last-Modified 的值;
ETag 和 If-None-Match
ETag 和 If-None-Match 对比资源哈希值,哈希值由资源内容计算得出,即依赖资源内容实现缓存。
- 浏览器第一次请求资源,服务端在返回资源的响应头上添加 ETag 字段,值是资源的哈希值
- 浏览器再次请求资源,在请求头上添加 If-None-Match,值是上次服务端返回的资源哈希值;
- 服务端收到请求,根据 If-None-Match 的值进行判断。若资源内容没有变化,则返回 304 状态码,并且不返回内容,浏览器使用缓存;否则返回资源内容,并计算哈希值放到 ETag;
TCP 和 UDP 的区别
TCP
- 面向连接
- 一对一通信
- 面向字节流
- 可靠传输,使用流量控制和拥塞控制
- 报头最小20字节,最大60字节
UDP
- 无连接
- 支持一对一,一对多,多对一和多对多的通信
- 面向报文
- 不可靠传输,不使用流量控制和拥塞控制
- 报头开销小,仅8字节
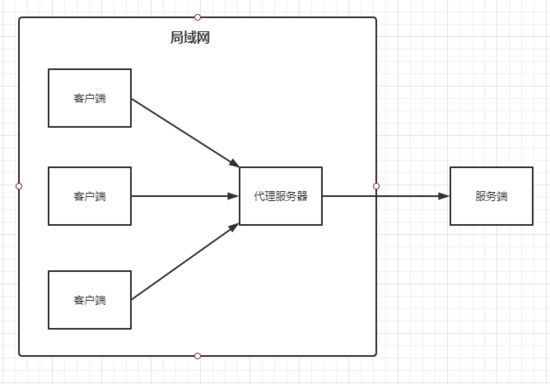
正向代理
- 代理客户;
- 隐藏真实的客户,为客户端收发请求,使真实客户端对服务器不可见;
- 一个局域网内的所有用户可能被一台服务器做了正向代理,由该台服务器负责 HTTP 请求;
- 意味着同服务器做通信的是正向代理服务器;
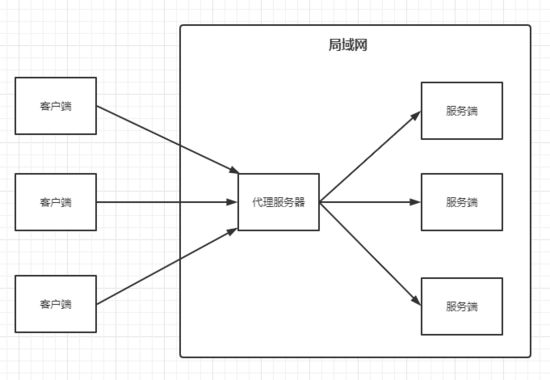
反向代理
- 代理服务器;
- 隐藏了真实的服务器,为服务器收发请求,使真实服务器对客户 端不可见;
- 负载均衡服务器,将用户的请求分发到空闲的服务器上;
- 意味着用户和负载均衡服务器直接通信,即用户解析服务器域名时得到的是负载均衡服务器的 IP ;
前端安全
跨站脚本攻击(XSS)
跨站脚本(Cross Site Scripting,XSS)指攻击者在页面插入恶意代码,当其他用户访问时,浏览会器解析并执行这些代码,达到窃取用户身份、钓鱼、传播恶意代码等行为。一般我们把 XSS 分为 反射型 、 存储型 、 DOM 型 3 种类型。
反射型 XSS
反射型 XSS 也叫“非持久型 XSS”,是指攻击者将恶意代码通过请求提交给服务端,服务端返回的内容,也带上了这段 XSS 代码,最后导致浏览器执行了这段恶意代码。
反射型 XSS 攻击方式需要诱导用户点击链接,攻击者会伪装该链接(例如短链接),当用户点击攻击者的链接后,攻击者便可以获取用户的 cookie 身份信息。
案例:
服务端直接输出参数内容:
_GET["param"];
echo "".$input."";
恶意代码链接:
http://www.a.com/test.php?param=
存储型 XSS
存储型 XSS 也叫“持久型XSS”,会把用户输入的数据存储在服务端,这种XSS具有很强的稳定性。
案例:
比如攻击者在一篇博客下留言,留言包含恶意代码,提交到服务端后被存储到数据库。所有访问该博客的用户,在加载出这条留言时,会在他们的浏览器中执行这段恶意的代码。
DOM 型 XSS
DOM 型 XSS 是一种特殊的反射型 XSS,它也是非持久型 XSS。相比于反射型 XSS,它不需要经过服务端,而是改变页面 DOM 来达到攻击。同样,这种攻击方式也需要诱导用户点击。
案例:
目标页面:
hello
恶意代码链接:
http://www.a.com/test.index?name=
就这样吧,有机会再补上