机器学习 数据预处理之特征编码(归纳整理版)
特征编码
由于机器学习算法都是在矩阵上执行线性代数计算,所以参加计算的特征必须是数值型的,对于非数值型的特征需要进行编码处理。对于离散型数据的编码,我们通常会使用两种方式来实现,分别是标签编码和独热编码
标签编码
将类别型特征从字符串转换为数字
特点:
- 解决了分类编码的问题,可以自由定义量化数字
- 数值本身没有任何含义,仅是标识或者排序的作用
- 可解释性比较差
适用范围:
- 对于定序类型的数据,使用标签编码更好,虽然定序类型也属于分类,但是其有排序逻辑
- 对数值大小不敏感的模型(如树模型),建议使用标签编码
方式一:map 或 replace
import pandas as pd
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.feature_extraction import DictVectorizer
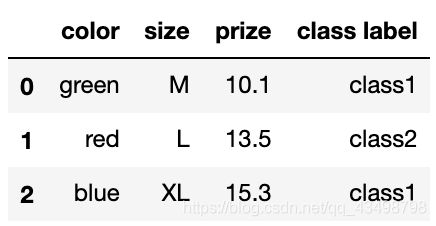
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
df
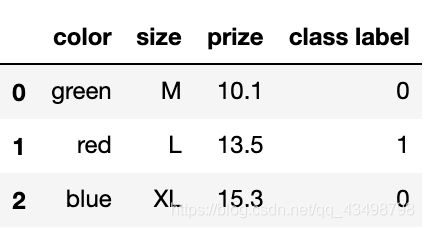
class_mapping = {
label:idx for idx,label in enumerate(set(df['class label']))}
df['class label'] = df['class label'].map(class_mapping)
df
size_mapping = {
'XL': 3,
'L': 2,
'M': 1}
df['size'] = df['size'].map(size_mapping)
df

color_mapping = {
'green': 1,
'red': 2,
'blue': 3}
df['color'] = df['color'].map(color_mapping)
df

反向变换
inv_color_mapping = {
v: k for k, v in color_mapping.items()}
inv_size_mapping = {
v: k for k, v in size_mapping.items()}
inv_class_mapping = {
v: k for k, v in class_mapping.items()}
df['color'] = df['color'].map(inv_color_mapping)
df['size'] = df['size'].map(inv_size_mapping)
df['class label'] = df['class label'].map(inv_class_mapping)
df
方式二:sklearn LabelEncoder
将离散型的数据转换成 0 0 0 到 n − 1 n − 1 n−1 之间的数
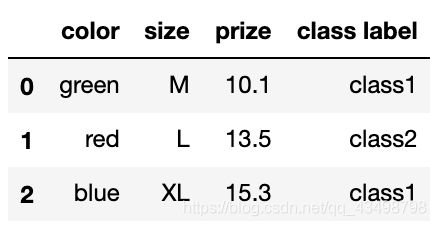
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
df
# 将类别标签转化为数值
class_le = LabelEncoder()
df['class label'] = class_le.fit_transform(df['class label'])
df

# 反向变换可以用函数 inverse_transform
df['class label'] = class_le.inverse_transform(df['class label'])
df
独热编码
采用 N N N 位状态寄存器来对 N N N 个可能的取值进行编码,每个状态都由独立的寄存器来表示,并且在任意时刻只有其中一位有效
特点:
- 解决了分类器不好处理分类变量的问题,同时也可以扩展特征
- 编码后的属性是稀疏的,存在大量的零元分量
- 当类别非常多时,特征空间会非常大,容易导致维度灾难的问题
适用范围:
- 适用于定类类型的数据,该类型数据是纯分类,不进行排序,互相之间也没有逻辑关系
- 对数值大小敏感的模型,必须使用独热编码
方式一:sklearn DictVectorizer
将 {特征名称:特征值} 字典组成的列表转化为数组或稀疏矩阵,当特征值为字符串时,就会对特征进行独热编码
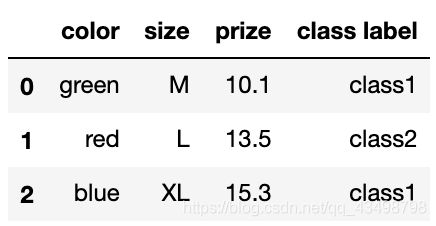
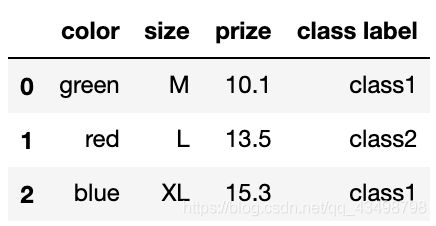
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
df

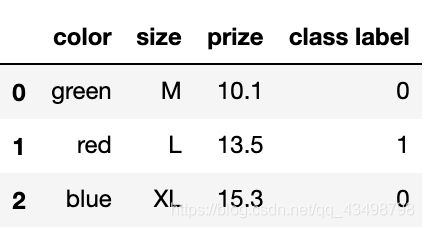
# 将类别标签转化为数值
class_le = LabelEncoder()
df['class label'] = class_le.fit_transform(df['class label'])
df
# 获取特征
feature = df.iloc[:,:-1]
feature

# 由 {特征名称:特征值} 字典组成的列表
feature.transpose().to_dict().values()
dict_values([{‘color’: ‘green’, ‘size’: ‘M’, ‘prize’: 10.1}, {‘color’: ‘red’, ‘size’: ‘L’, ‘prize’: 13.5}, {‘color’: ‘blue’, ‘size’: ‘XL’, ‘prize’: 15.3}])
dvec = DictVectorizer(sparse=False)
X = dvec.fit_transform(feature.transpose().to_dict().values())
X

可以调用 get_feature_names 来返回新的列的名字,其中0和1就代表是不是这个属性
X = pd.DataFrame(X, columns=dvec.get_feature_names())
X.join(df['class label'])

方式二:sklearn OneHotEncoder
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
df

# 将类别标签转化为数值
class_le = LabelEncoder()
df['class label'] = class_le.fit_transform(df['class label'])
df

ohe = OneHotEncoder(sparse=False) # Will return sparse matrix if set True else will return an array.
X = ohe.fit_transform(df[['color','size']].values)
X

X = pd.DataFrame(X, columns=ohe.get_feature_names())
X.join(df[['prize','class label']])

方式三:pandas get_dummies
Pandas库中同样有类似的操作,使用 get_dummies 也可以得到相应的特征
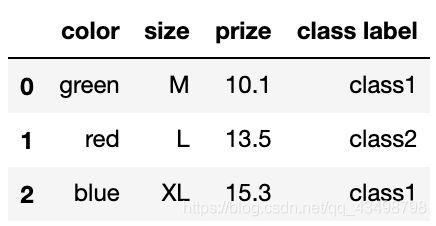
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
df
# 将类别标签转化为数值
class_le = LabelEncoder()
df['class label'] = class_le.fit_transform(df['class label'])
df

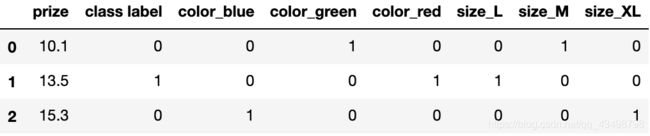
# 对整个DF使用 get_dummies 将会得到新的列
pd.get_dummies(df)
本文到此结束,后续将会不断更新,如果发现上述有误,请各位大佬及时指正!