《Spring in Action》第四版第一章《将 Spring 付诸实践》读书笔记(一)
Spring的宗旨和关键策略
原文链接地址:http://tantanit.com/springinaction-di-si-ban-di-yi-zhang-jiang-spring-fu-zhu-shi-jian-du-shu-bi-ji-yi/
Spring in Action(Spring实战)的这一章是对Spring进行概述,讲述了Spring的项目宗旨,基本原理和关键策略。并且对Spring框架进行了概览,比较Spring4与之前版本的区别。这一章的读书笔记分为两篇,这一篇是对Spring的项目宗旨,基本原理和关键策略的读书笔记,下一篇对Spring框架进行概览,并比较Spring4与之前版本的区别。
Spring项目的宗旨是简化Java开发,主要使用以下四个关键策略:
- 使用POJO进行轻量化和最小侵入的开发
- 利用依赖注入和面向接口编程,实现松耦合
- 通过面向方面编程以及约定来实现声明式编程
- 通过面向方面编程和模板(template)来消除样板化的重复代码(boilerplate code)
笔者按照POJO、依赖注入、面向方面编程和使用模板四个方面整理了以下笔记。
释放POJO的能量
POJO,全称是plain old Java object,根据维基百科,这个概念是在2000年提出的,用来给简单的对象命名。什么是简单呢,就是不使用任何对象模型(Java object models)、约定(conventions)和框架。理想情况下,一个POJO不能被任何定义限制,它不能被规定要继承特定类,比如:
public class Foo extends javax.servlet.http.HttpServlet {
...
不能被规定要实现特定接口,比如:
public class Bar implements javax.ejb.EntityBean {
...
不能被规定要加上特定标注,比如:
@javax.persistence.Entity public class Baz {
...
而下面这样简单的类才是一个POJO:
public class HelloWorldBean {
public String sayHello() {
return "Hello World";
}
}
然而,由于技术限制,有时候必须使用标注实现某些功能,这时,只要在加标注之前是一个POJO,去掉标注之后仍然是一个POJO,那么这个对象也可以当作是一个POJO。
一个Spring组件(component)可以是任何类型的POJO,Spring尽可能避免其API污染你的程序代码,Spring既不强迫你的代码实现一个Spring定义的接口,也不强迫你的代码继承Spring定义的类。实际上,从你的代码本身看不出是在使用Spring框架。最坏的情况下,就是要在你的代码里一个Spring的标注(anotation),但你的代码仍然是一个POJO。
POJO形式简单,但Spring通过依赖注入将各个POJO组装起来,释放出强大的功能。
依赖注入
Spring做了很多事,但是Spring最重要的是以下两个特性:
- 依赖注入(dependency injection),简称DI
- 面向方面编程(aspect-oriented programming),简称AOP
这两个特性有着共同的编程思想,就是每个模块或类都专注于自己做的事,尽量做到松耦合,高内聚,尽可能可重用。依赖注入是在实例管理上做到这一点,而面向方面编程是在业务逻辑上做到这一点。
依赖注入这个词,听起来吓人,让人想到复杂的编程技术和设计模式。但其实并不复杂,使用依赖注入后,代码会明显变得简单、易读、容易测试。
依赖注入在处理类与类之间的引用上发挥作用。什么是依赖?类A要使用类B,我们就说类A依赖类B,从编程语言的角度,其实就是引用类B的实例。注入的意思就是,在类A外生成类B的实例,类A直接引用该实例,把主被动态一改,就是将类B的实例注入到类A中。如果不使用依赖注入,类A需要自己维护对B的直接引用(必须是具体的类型而不能是抽象类或接口),也就是要自己初始化一个B的实例。这导致了高度耦合,难以测试。
下面是一个没有使用依赖注入的例子:
// 专门拯救少女的骑士
public class DamselRescuingKnight implements Knight {
private RescueDamselQuest quest; // 拯救少女的远征,quest是远征的意思
// 与RescueDamselQuest高度耦合
public DamselRescuingKnight() {
this.quest = new RescueDamselQuest();
}
// 执行远征任务
public void embarkOnQuest() {
quest.embark();
}
}
这个例子中,RescueDamselQuest是DamselRescuingKnight自己创建的实例。这里有两点需要注意,第一点,RescueDamselQuest是DamselRescuingKnight自己创建的,而不是其它类传过来的,这样限制了quest的灵活性。第二点,RescueDamselQuest是一个具体类型(而不是抽象类或接口),将”远征“的目的限制在”拯救少女”,与RescueDamselQuest高度(过度)耦合了。因为骑士远征,可能是为了其它目的,比如屠龙、参加圆桌会议等,而由于过度耦合,embarkOnQuest没有办法执行这些任务了。
耦合是把双刃剑,过度耦合导致难以测试,难以复用,难以理解,修改bug容易引起其它bug。另一方面,没有耦合,类对要使用的类一无所知,就无法使用,几乎什么都做不了。所以,耦合是必要的,但要仔细管理。
而使用依赖注入可以很好解决这个问题。第三方工具统一生成和管理实例,以及实例之间的依赖关系。对象本身不需要创建或者获取它们使用的实例。
下面的BraveKnight与DamselRescuingKnight相比,就更加通用。
public class BraveKnight implements Knight {
private Quest quest;
public BraveKnight(Quest quest) {
this.quest = quest;
}
public void embarkOnQuest() {
quest.embark();
}
}
与DamselRescuingKnight相比,BraveKnight有两个改进的地方。第一,Quest作为参数从其它类传进来,而不是BraveKnight自己创建。第二,quest(出征)的类型为接口,而不是具体的RescueDamselQuest,这样出征的任务就没有被限制。
使用依赖注入进行单元测试
package com.springinaction.knights;
import static org.mockito.Mockito.*;
import org.junit.Test;
public class BraveKnightTest {
@Test
public void knightShouldEmbarkOnQuest() {
Quest mockQuest = mock(Quest.class);
BraveKnight knight = new BraveKnight(mockQuest);
knight.embarkOnQuest();
verify(mockQuest, times(1)).embark();
}
}
借助于mockito和junit,可以很方便地进行单元测试。首先,利用mockito的mock方法,模拟一个Quest对象。再将这个对象的引用注入到BraveKnight对象中。执行embarkOnQuest方法后,验证是否正好执行一次。从这段代码可以看出,对于BraveKnight而言,Quest是从外部生成,再注入到BraveKnight的。
装配
将应用组件关联起来的动作叫做装配(wiring)。可以使用XML的方式进行配置,也可以使用Java代码。(个人觉得Java的方式更加可读和可维护,这里只记录java方式。)
@Configuration
public class KnightConfig {
@Bean
public Knight knight() {
return new BraveKnight(quest());
}
@Bean
public Quest quest() {
return new SlayDragonQuest(System.out);
}
}
这个配置文件为Knight和Quest接口创建了实例,并且将Quest的实例注入到Knight中。也可以说是把Quest装配到Knight中(Quest还可以继续装配到其它bean里)。但是它们是如何加载,又加载到哪里呢?答案是,应用程序的bean是在Spring容器中。将这两个bean注册到应用上下文后,通过应用上下文可以获取到这些bean。
Spring容器
在使用Spring的应用中,所有的对象都存活于Spring容器中。容器创建对象,配置它们,将它们装配在一起,并管理它们从new到finalize的完整生命周期。

Spring容器是Spring框架的核心,Spring容器使用框架来管理应用程序的组件,包括创建组件直接的关联。不存在单一的Spring容器,Spring容器是由可分为两类的一些容器构成。bean工厂(Bean factories,由org.springframework.beans.factory.BeanFactory接口定义)是最简单的容器,为依赖注入提供基础的支持。应用上下文(Application contexts,由org.springframework.context.ApplicationContext接口定义),是一个提供了应用框架层级服务的bean工厂。这些服务包括:从属性文件解析文本,将应用的事件发布到相应的事件监听器等。对于大部分应用来说,bean工厂的级别太低,能做的事太少,所以偏好使用应用上下文。
使用应用上下文
Spring偏好使用应用上下文,以下是主要的上下文:
- AnnotationConfigApplicationContext,从一个或多个Java配置文件中加载Spring应用上下文。
- AnnotationConfigWebApplicationContext,从一个或多个Java配置文件中加载Spring web应用上下文。
- ClassPathXmlApplicationContext,从classpath目录下的一个或多个xml配置文件中加载上下文定义,并且将上下文定义看作classpath的资源。
- FileSystemXmlApplicationContext,从文件系统下的一个或多个xml配置文件中加载上下文定义。
- XmlWebApplicationContext,从web应用程序中的一个或多个xml配置文件中加载上下文定义。
AnnotationConfigWebApplicationContext和ApplicationContext涉及Spring web的内容将在第八章展开,先看FileSystemXmlApplicationContext和ClassPathXmlApplicationContext这两个使用xml加载上下文的例子。这两种方式和从bean工厂加载bean相似。
//使用FileSystemXmlApplicationContext加载applicationContext
ApplicationContext context = new FileSystemXmlApplicationContext("c:/knight.xml");
//使用ClassPathXmlApplicationContext加载applicationContext
ApplicationContext context = new ClassPathXmlApplicationContext("knight.xml");
两种方式的区别在于,FileSystemXmlApplicationContext在文件系统里的特定位置查找xml配置文件,而ClassPathXmlApplicationContext在classpathl里(包括jar里)的任何地方查找xml配置文件。
还可以使用java配置的方式,用AnnotationConfigApplicationContext加载上下文。
//使用AnnotationConfigApplicationContext加载applicationContext
ApplicationContext context = new AnnotationConfigApplicationContext(com.springinaction.knights.config.KnightConfig.class);
获取到context之后,可以使用context的getBean()方法获取bean。
public class KnightMain {
public static void main(String[] args) throws Exception {
ClassPathXmlApplicationContext context =
 new ClassPathXmlApplicationContext(
"META-INF/spring/knight.xml");
Knight knight = context.getBean(Knight.class);
knight.embarkOnQuest();
context.close();
}
}
bean的生命周期
在传统的java应用中,bean的生命周期很简单,用new初始化,不用的时候,垃圾回收机制会自动回收。
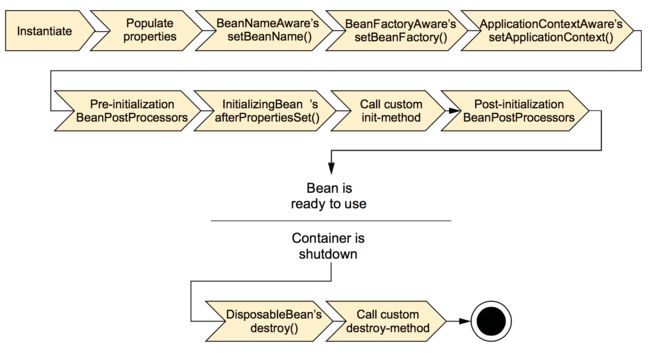
生命周期里的每一步,都可以根据需要进行定制。下面分别解释这些步骤。
- Spring初始化bean。
- Spring将值和bean的引用注入到bean的属性里。
- 如果bean实现了BeanNameAware接口,Spring把bean的ID传给setBeanName()方法。
- 如果bean实现了BeanFactoryAware接口,Spring会调用setBeanFactory方法,将bean factory传入。
- 如果bean实现了ApplicationContextAware接口,Spring会调用setApplicationContext()方法,将bean的引用传给封闭的应用上下文(application context)。
- 如果bean实现了BeanPostProcessor接口,Spring会调用这个接口的postProcessBeforeInitialization()方法。
- 如果bean实现了InitializingBean接口,Spring会调用这个接口的afterPropertiesSet()方法。类似地,如果这个bean使用了初始化方法进行声明,特定的初始化方法也会被调用。
- 如果bean实现了BeanPostProcessor接口,Spring会调用这个接口的postProcessAfterInitialization()方法。
- 此时,bean已经在应用上下文(application context)中,可以被应用使用了。当应用上下文销毁时,bean才会被销毁。
- 如果bean实现了DisposableBean接口,Spring会调用这个接口的destroy方法,同时,如果bean使用了销毁方法进行声明,特定的销毁方法会被调用。
(笔者再说说平时编程时感受到的,依赖注入的一些好处。由于Spring容器将所有的实例统一管理,类A在使用类B时,只需要声明对类B的引用,就可以直接从Spring容器里获取B的实例,不用再重新生成一个B的实例。假定实例范围定义为全局唯一,如果A2也使用类B,也只需要声明对类B的引用,获取同一个实例,依赖注入可以减少重复实例化,避免重复生成实例的开销。依赖注入更大的好处体现在引用具有传递性时,比如类A使用类B,而类B又使用类C。因为从功能上看,类其实是方法的集合,类A可能只使用类B的一个方法,而这个方法并未使用类C。那么实际上在业务和功能上,类A只需要和类B耦合,根本不使用类C。如果没有使用依赖注入,如果类A要使用类B,需要显式地实例化B,而要实例化B,又要先实例化C,特别是在C的构造函数带有参数时,过程令人抓狂。由于各个类之间的引用情况可能非常复杂,引用链可能很长,这个过程会非常痛苦。)
面向方面编程(AOP)
依赖注入实现了组件的松耦合,而面向方面编程可以使用全系统范围的可重用的组件的功能。
面向方面编程将系统的关注点分离。系统由组件构成,各个组件负责自己的功能。但是有时候,组件也要处理一些非核心功能。像日志、事务管理和安全性这样的功能在各个组件中经常出现,而这些组件的核心功能并不是这些功能。
在多个组件里都关注这些非核心功能(的实现),既使得这些功能的代码重复,又使组件的代码被这些代码污染,显得杂乱。

而面向方面编程可以让组件只关心核心功能,实现高内聚,并且确保POJO保持朴素(plain)。

日志、事务和安全等各个方面(aspect)就像一张张毯子,覆盖在各个组件上,毯子只关心自己的业务,不侵入到组件内部,组件也不用关心毯子的存在。
下面的例子是没有使用AOP时,骑士要自己负责在行动前和行动后,提醒歌手唱歌。
public class BraveKnight implements Knight {
private Quest quest;
private Minstrel minstrel;
public BraveKnight(Quest quest, Minstrel minstrel) {
 this.quest = quest;
this.minstrel = minstrel;
}
public void embarkOnQuest() throws QuestException {
minstrel.singBeforeQuest();
quest.embark();
minstrel.singAfterQuest();
}
}
这样会有一些问题,从业务角度,歌手应该要自己观察骑士的行为,自动唱歌,而不应该是骑士提醒。而且骑士根本不需要知道歌手的存在。从代码角度来说,骑士只管行动就好了,处理唱歌不仅让代码显得杂乱,还要注入minstrel对象,这也导致要检查这个对象是否为null。所以需要将Minstrel配置成方面(aspect),并且进行其它配置,让Minstrel观察骑士的行为,并在适当的时间做适当的事。
>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-3.2.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="knight" class="com.springinaction.knights.BraveKnight">
<constructor-arg ref="quest" />
bean>
<bean id="quest" class="com.springinaction.knights.SlayDragonQuest"> <constructor-arg value="#{T(System).out}" />
bean>
<bean id="minstrel" class="com.springinaction.knights.Minstrel">
<constructor-arg value="#{T(System).out}" />
bean>
<aop:config>
<aop:aspect ref="minstrel">
<aop:pointcut id="embark"
expression="execution(* *.embarkOnQuest(..))"/>
 <aop:before pointcut-ref="embark"
method="singBeforeQuest"/>
<aop:after pointcut-ref="embark"
method="singAfterQuest"/>
aop:aspect>
aop:config>
beans>
bean标签定义了各个实例,aop:config标签定义了aop的配置,详细内容会在第四章讲解。
使用模板减少冗余代码
有时候为了相似的功能,一遍又一遍地写相同的代码,这些代码就是样板化的重复代码(boilerplate code)。Java的API中就有很多这样的代码,比如JDBC。
public Employee getEmployeeById(long id) {
Connection conn = null;
PreparedStatement stmt = null;
ResultSet rs = null;
try {
conn = dataSource.getConnection();
stmt = conn.prepareStatement(
"select id, firstname, lastname, salary from " +
"employee where id=?");
stmt.setLong(1, id);
rs = stmt.executeQuery();
Employee employee = null;
if (rs.next()) {
employee = new Employee();
employee.setId(rs.getLong("id"));
employee.setFirstName(rs.getString("firstname"));
employee.setLastName(rs.getString("lastname"));
employee.setSalary(rs.getBigDecimal("salary"));
}
return employee;
} catch (SQLException e) {
} finally {
if(rs != null) {
try {
rs.close();
} catch(SQLException e) {
}
}
if(stmt != null) {
try {
stmt.close();
} catch(SQLException e) {
}
}
if(conn != null) {
try {
conn.close();
} catch(SQLException e) {
}
}
}
return null;
}
查询的代码被埋没在JDBC规定的一堆代码里。首先,创建连接,然后创建statement,再查询以获得,还要处理这些过程产生的异常。在这些都做完了之后,还要进行清理,包括关闭结果集,关闭statement,关闭连接,当然,也还要处理这个过程产生的异常。大部分代码都和查询无关,而是来自JDBC的样板化的重复代码(boilerplate code)。不仅是JDBC,JMS、JNDI以及REST服务的使用方的代码,也经常会有重复代码。Spring通过将这些代码包装到template里,来减少样板化的代码。在JDBC方面,Spring使用JdbcTemplate做到这一点。下面是Spring使用SimpleJdbcTemplate的例子。
public Employee getEmployeeById(long id) {
return jdbcTemplate.queryForObject(
"select id, firstname, lastname, salary " +
"from employee where id=?",
new RowMapper<Employee>() {
public Employee mapRow(ResultSet rs,
int rowNum) throws SQLException {
Employee employee = new Employee();
employee.setId(rs.getLong("id"));
employee.setFirstName(rs.getString("firstname"));
employee.setLastName(rs.getString("lastname"));
employee.setSalary(rs.getBigDecimal("salary"));
return employee;
}
},
id);
}
这段代码将JDBC的那堆样板化的重复代码都交给jdbcTemplate处理,只关注查询任务本身,代码精简,也更加专注。
以上讲解了Spring利用面向POJO开发、依赖注入、面向方面编程和模板,来减少Java开发中代码的复杂性。同时,也展示了如何配置bean以及如何使用XML配置一个方面(aspect)。特别是对依赖注入和面向方面编程有了初步的了解。但是很多内容还是留有疑问,比如装配(wiring)方面的细节,将在第二章和第三章详述,而面向方面编程将在第四章展开。
欢迎搜索“谈谈IT”或扫描下方二维码关注微信公众号,第一时间获取最新文章。
