写在前面的话,我这个人虚荣心强
1.scrapy 的安装
1.scrapy 依赖的包太多,所以我建议使用anaconda安装,一路下一步安装即可

2.安装scrapy 只需 在conda 命令行里面输入 conda install Scrapy 即可。
2.配置scrapy 环境变量 c:\ProgramData\Anaconda3\Scripts,把这个路径配置到window环境变量里面。(不配这个,下一步没法执行哦!)
3.scrapy 常用命令
1.fetch: 它使用Scrapy downloader 提取的 URL。
2.runspider: 它用于而无需创建一个项目运行自行包含蜘蛛(spider)。
3.settings: 它规定了项目的设定值。
4.shell: 这是一个给定URL的一个交互式模块。
5.startproject: 它创建了一个新的 Scrapy 项目。
6.version: 它显示Scrapy版本。
7.view: 它使用Scrapy downloader 提取 URL并显示在浏览器中的内容。
一些项目相关的命令,如下:
8.crawl: 它是用来使用蜘蛛抓取数据;
9.check: 它检查项目并由 crawl 命令返回;
10.list: 它显示本项目中可用蜘蛛(spider)的列表;
11.edit: 可以通过编辑器编辑蜘蛛;
12.parse:它通过蜘蛛分析给定的URL;
13.bench: 它是用来快速运行基准测试(基准讲述每分钟可被Scrapy抓取的页面数量)。
4.创建scarpy项目 ,在cmd中输入scrapy startprojectfirst_scrapy,然后会在当前目录如下结构的项目
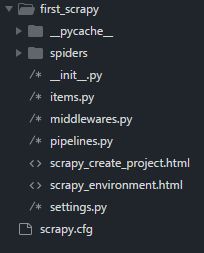
5.Spider类 :Spider是负责定义如何遵循通过网站的链接并提取网页中的信息的类。它是所有其他的蜘蛛(spider)都必须继承的类。它具有以下类:
class scrapy.spiders.Spider
下面的表显示了 scrapy.Spider 类的字段:
1 name
这是 spider 的名字
2 allowed_domains
它是允许 spider 抓取域名称的列表
3 start_urls
这是供以后蜘蛛将开始抓取的URL列表的根
4 custom_settings
这些设置在蜘蛛运行时会从项目范围内覆盖配置
5 crawler
它是链接到 spider 实例绑定的 Crawler 对象的属性
6 settings
这些是运行一个 spider 的设置
7 logger
它是用来发送日志消息的 python 记录器
8 from_crawler(crawler,*args,**kwargs)
它是由 spider 创建的一个类方法。参数是:
crawler: 抓取工具到 spider 实例将被绑定;
args(list): 这些参数传递给方法: _init_();
kwargs(dict): 这些关键字参数传递给方法: _init_().
9 start_requests()
如果不指定特定的URL,蜘蛛会打开抓取,Scrapy调用start_requests()方法
10 make_requests_from_url(url)
它是用于将URL网址转换为请求方法
11 parse(response)
这个方法处理响应并返回废弃数据
12 log(message[,level,component])
这个方法会通过蜘蛛发送日志记录信息
13 closed(reason)
这种方法在当蜘蛛关闭时调用
6 item类 Scrapy进程可通过使用蜘蛛提取来自网页中的数据。Scrapy使用Item类生成输出对象用于收刮数据。Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便。Item提供了类字典的API,并且可以很方便的声明字段,很多Scrapy组件可以利用Item的其他信息。
定义Item
定义Item非常简单,只需要继承scrapy.Item类,并将所有字段都定义为scrapy.Field类型即可
[python]view plaincopy
import scrapy
classProduct(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
Item Fields (项目字段)
项目字段用于显示每个字段的元数据。字段对象上的值没有限制,可访问元数据的键不包含的元数据的任何引用列表。字段对象用于指定所有字段元数据,您可以根据项目您的要求指定任何其他字段键。字段对象可以通过使用 Item.fields 属性进行访问。Field对象可用来对每个字段指定元数据。例如上面last_updated的序列化函数指定为str,可任意指定元数据,不过每种元数据对于不同的组件意义不一样。
7 .Scrapy项目加载器类(Item Loader)
项目加载器提供了一个方便的方式来填补从网站上刮取的项目。
声明项目加载器
fromscrapy.loaderimportItemLoader
frommyproject.itemsimportProduct
defparse(self, response):
l = ItemLoader(item=Product(), response=response)
l.add_xpath('name','//div[@class="product_name"]')
l.add_xpath('name','//div[@class="product_title"]')
l.add_xpath('price','//p[@id="price"]')
l.add_css('stock','p#stock]')
l.add_value('last_updated','today')# you can also use literal values
returnl.load_item()
8.定于数目机构items
项目是用于收集从网站刮取下数据的容器。 在启动蜘蛛时必须要定义项目。 要定义项目,在目录 first_scrapy自定义目录下找到编辑items.py文件。items.py 看起来如下所示:
import scrapy
class First_scrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
MyItem 类包含一个数字,scrapy已为我们建成预先定义的对象继承项目。举例来说,如果想从网站中提取名称,URL和说明, 需要定义字段这三个属性。
因此,让我们再补充一点,来收集这些项目:
from scrapy.item import Item, Field
class First_scrapyItem(scrapy.Item):
name = scrapy.Field()
url = scrapy.Field()
desc = scrapy.Field()
9.第一个爬虫
Spider定义从提取数据的初始URL,如何遵循分页链接以及如何提取和分析在items.py定义字段的类。Scrapy提供了不同类型的蜘蛛,每个都给出了一个具体的目的。
在 first_scrapy/spiders 目录下创建了一个叫作 “first_spider.py” 文件,在这里可以告诉scrapy。要如何查找确切数据,这里必须要定义一些属性:
name: 它定义了蜘蛛的唯一名称;
allowed_domains: 它包含了蜘蛛抓取的基本URL;
start-urls: 蜘蛛开始爬行的URL列表;
parse(): 这是提取并解析刮下数据的方法;
下面的代码演示了蜘蛛代码的样子:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class firstSpider(scrapy.Spider):
name = "first"
allowed_domains = ["yiibai.com"]
start_urls = [
"http://www.yiibai.com/scrapy/scrapy_create_project.html",
"http://www.yiibai.com/scrapy/scrapy_environment.html"
]
def parse(self, response):
filename = response.url.split("/")[-1]
print 'Curent URL => ', filename
with open(filename, 'wb') as f:
f.write(response.body)