在上一篇文章中,我们讲了逻辑回归模型,这里,我们讲逻辑回归的代价函数(也翻译作成本函数)。

吴恩达让我转达大家:这一篇有很多公式,做好准备,睁大眼睛!代价函数很重要!
为什么需要代价函数:
为了训练逻辑回归模型的参数 w和参数b我们,需要一个代价函数,通过训练代价函数来得到参数w和参数b 。先看一下逻辑回归的输出函数:
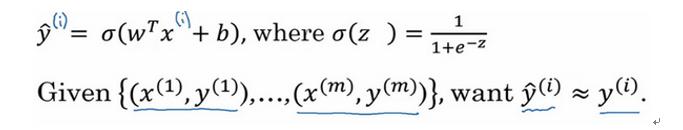
为了让模型通过学习调整参数,你需要给予一个m样本的训练集,这会让你在训练集上找到参数w和参数b,来得到你的输出。
对训练集的预测值,我们将它写成y^,我们更希望它会接近于训练集中的y值,为了对上面的公式更详细的介绍,我们需要说明上面的定义是对一个训练样本来说的,这种形式也使用于每个训练样本,我们使用这些带有圆括号的上标来区分索引和样本,训练样本 所对应的预测值是 y(i),是用训练样本的 (w^T) (x^(i))+b 然后通过sigmoid函数来得到,也可以把z定义为
,我们将使用这个符号(i) 注解,上标(i) 指明数据表示x或者y 或者z或者其他数据的第i个训练样本,这就是上标(i) 的含义。
损失函数:
损失函数又叫做误差函数,用来衡量算法的运行情况(后续的网络判定与评估性能就是要找到一个合适的loss,Loss function:
我们通过这个 L 称为的损失函数,来衡量预测输出值和实际值有多接近。
一般我们用预测值和实际值的平方差或者它们平方差的一半,但是通常在逻辑回归中我们不这么做,因为当我们在学习逻辑回归参数的时候,会发现我们的优化目标不是凸优化,只能找到多个局部最优值,梯度下降法很可能找不到全局最优值,虽然平方差是一个不错的损失函数,但是我们在逻辑回归模型中会定义另外一个损失函数。
我们在逻辑回归中用到的损失函数是:
为什么要用这个函数作为逻辑损失函数?
当我们使用平方误差作为损失函数的时候,你会想要让这个误差尽可能地小,对于这个逻辑回归损失函数,我们也想让它尽可能地小,为了更好地理解这个损失函数怎么起作用,我们举两个例子(y^代表预测值):
当y = 1时损失函数L = -log(y^),如果想要损失函数L尽可能得小,那么y^就要尽可能大,因为sigmoid函数取值 [0,1],所以 y^会无限接近于1。
当y = 0 时损失函数L = -log(1 - y^) ,如果想要损失函数L尽可能得小,那么y^ 就要尽可能小,因为sigmoid函数取值 ,所以y^会无限接近于0。
在这门课中有很多的函数效果和现在这个类似,就是如果y等于1,我们就尽可能让y^变大,如果y等于0,我们就尽可能让y^变小。损失函数是在单个训练样本中定义的,它衡量的是算法在单个训练样本中表现如何,为了衡量算法在全部训练样本上的表现如何,我们需要定义一个算法的代价函数(代价函数用J表达),算法的代价函数是对m个样本的损失函数求和然后除以 m(因为要均值化) :
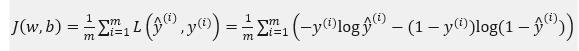
损失函数只适用于像这样的单个训练样本,而代价函数是参数的总代价,所以
在训练逻辑回归模型时候,我们需要找到合适的w和b ,来让代价函数 J 的总代价降到最低。
根据我们对逻辑回归算法的推导及对单个样本的损失函数的推导和针对算法所选用参数的总代价函数的推导,结果表明逻辑回归可以看做是一个非常小的神经网络,在下一篇文章中,我们会看到神经网络会做什么。