机器学习算法评价指标 recall(召回率)、precision(精度)、F-measure(F值)、ROC曲线、RP曲线
机器学习中算法评价指标总结 recall(召回率)、precision(精度)、F-measure、ROC曲线、RP曲线
在机器学习、数据挖掘、推荐系统完成建模之后,需要对模型的效果做评价。
业内目前常常采用的评价指标有精度(Precision)、召回率(Recall)、F值(F-Measure)等,下图是不同机器学习算法的评价指标
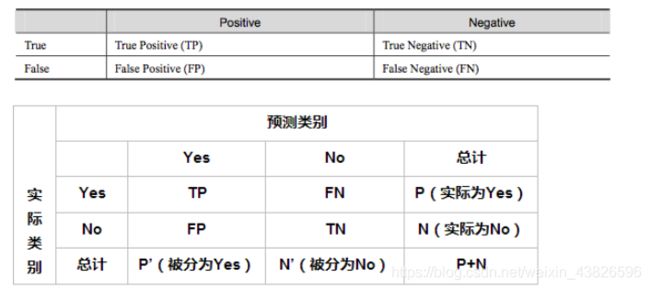
首先要了解混淆矩阵
True Positive(真正,TP):将正类预测为正类数
True Negative(真负,TN):将负类预测为负类数
False Positive(假正,FP):将负类预测为正类数误报 (Type I error)
False Negative(假负,FN):将正类预测为负类数→漏报 (Type II error)
1、准确率(Accuracy)
准确率(accuracy)计算公式为
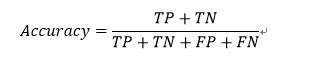
注:准确率是我们最常见的评价指标,而且很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。但是在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc也有 99% 以上,没有意义。 因此,单纯靠准确率来评价一个算法模型是远远不够科学全面的。
2、错误率 (error rate=1-Accuracy)
被分错的样本处以总样本数目
error rate = (FP+FN)/(TP+TN+FP+FN),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate。
3、灵敏度(sensitive)
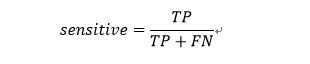 ,
,
表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。
4、特效度(sensitive)
specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力。
5、精确率、精度(Precision)
精确率(precision)定义为:

表示被分为正例的示例中实际为正例的比例。
6、召回率(recall)
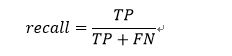
召回率又被称为查全率,用来说明分类器中判定为真的正例占总正例的比率。召回率是覆盖面的度量,可以看到召回率与灵敏度是一样的。
7、综合评价指标(F-Measure)
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。 一般来说准确率和召回率呈负相关,一个高,一个就低,如果两个都低,一定是有问题的
F-Measure是Precision和Recall加权调和平均:
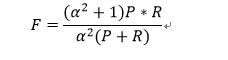
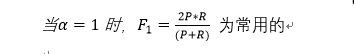
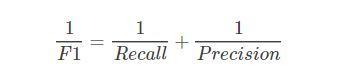
可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
比如,在进行前景检测与背景去除时,设置的算法评价指标

比如,信息检索、分类、识别、翻译等领域两个最基本指标是召回率(Recall Rate)和准确率(Precision Rate),召回率也叫查全率,准确率也叫查准率,概念公式:
召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数
8、ROC 曲线
ROC关注两个指标
True Positive Rate ( TPR ) = TP / [ TP + FN] ,TPR代表能将正例分对的概率(真正率)
False Positive Rate( FPR ) = FP / [ FP + TN] ,FPR代表将负例错分为正例的概率(假正率)
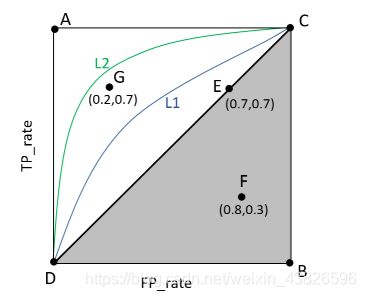
于是,指标AUC(Area Under roc Curve)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的Performance。
(1)曲线与FP_rate轴围成的面积(记作AUC)越大,说明性能越好,即图上L2曲线对应的性能优于曲线L1对应的性能。即:曲线越靠近A点(左上方)性能越好,曲线越靠近B点(右下方)曲线性能越差。
(2)A点是最完美的performance点,B处是性能最差点。
(3)位于C-D线上的点说明算法性能和random猜测是一样的–如C、D、E点。位于C-D之上(即曲线位于白色的三角形内)说明算法性能优于随机猜测–如G点,位于C-D之下(即曲线位于灰色的三角形内)说明算法性能差于随机猜测–如F点。
(4)虽然ROC曲线相比较于Precision和Recall等衡量指标更加合理,但是其在高不平衡数据条件下的的表现仍然过于理想,不能够很好的展示实际情况。
9、PR曲线
准确率和召回率是互相影响的,有时会相互矛盾,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。一般情况,用不同的阀值,统计出一组不同阀值下的精确率和召回率,如下图:
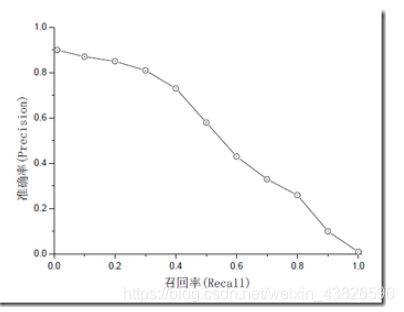
如果是做搜索,那就是保证召回的情况下提升准确率;
如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。
所以,在两者都要求高的情况下,可以用F1来衡量。
另外一个指标AP和mAP(mean Average Precision)

mAP是为解决P,R,F-measure的单点值局限性的。为了得到 一个能够反映全局性能的指标,可以看考察下图,其中两条曲线(方块点与圆点)分布对应了两个检索系统的准确率-召回率曲线
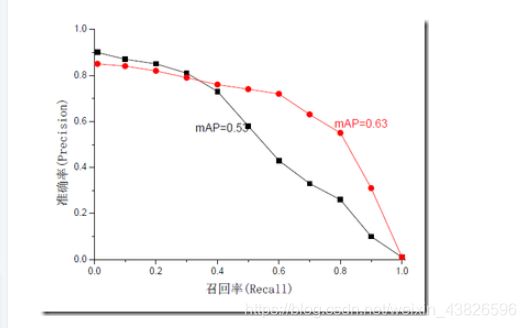
可以看出,虽然两个系统的性能曲线有所交叠但是以圆点标示的系统的性能在绝大多数情况下要远好于用方块标示的系统。
从中我们可以 发现一点,如果一个系统的性能较好,其曲线应当尽可能的向上突出。
更加具体的,曲线与坐标轴之间的面积应当越大。
最理想的系统, 其包含的面积应当是1,而所有系统的包含的面积都应当大于0。这就是用以评价信息检索系统的最常用性能指标,平均准确率mAP其规范的定义如下:(其中P,R分别为准确率与召回率)
注:P/R和ROC是两个不同的评价指标和计算方式,一般情况下,检索用前者,分类、识别等用后者
10、其他评价指标
计算速度:分类器训练和预测需要的时间;
鲁棒性:处理缺失值和异常值的能力;
可扩展性:处理大数据集的能力;
可解释性:分类器的预测标准的可理解性,像决策树产生的规则就是很容易理解的,而神经网络的一堆参数就不好理解,我们只好把它看成一个黑盒子。
这2篇文章写的很不错,有博主提示,周志华老师西瓜书第二章,写的很好。后悔没有早一点看到,有西瓜书的可以直接去看西瓜书。
参考:https://blog.csdn.net/xwd18280820053/article/details/70674256
https://www.cnblogs.com/Zhi-Z/p/8728168.html