Flink-SQL管理工具flink-streaming-platform-web部署
目录
1. 概述
2. 软件版本
2.1 软件版本列表
2.2 添加第3放依赖jar包的方法
3. 启动
3.1 启动flink
3.2 启动flink-streaming-platform-web
4. 配置flink-streaming-platform-web
4.1 登录页面
4.2 系统配置
4.3 任务配置
5. 观察运行结果
5.1 观察任务提交结果
5.2 观察数据变化
5.3 在flink的ui上观察任务
6. 参考资料
1. 概述
这里部署flink-streaming-platform-web,并跑通kafka->flink sql -> mysql的一个样例,实时从kafka中读取json字符串,经过ETL操作,将数据汇总后写入mysql sink
-- ETL
INSERT INTO flink_web_sample.sync_test_2
SELECT day_time,SUM(amnount) AS total_gmv
FROM flink_test_3
GROUP BY day_time;
2. 软件版本
2.1 软件版本列表
- flink-streaming-platform-web.tar.gz
flink-streaming-platform-web(20210202).tar.gz (下载地址)
- flink
flink-1.12.0-bin-scala_2.11.tgz (下载地址 )
- kafka
这里使用Kafka Connect Datagen来生成模拟数据,具体操作请参考这里
json配置文件内容如下
//json文件名为 flink_web.source.datagen.json,注意这里的文件名和配置内容中的name参数的值,是保持一致的
{
"name": "flink_web.source.datagen",
"config": {
"connector.class": "com.github.xushiyan.kafka.connect.datagen.performance.DatagenConnector",
"tasks.max": "1",
"topic.name": "flink2",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": false,
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter.schemas.enable": false,
"poll.size": 10,
"poll.interval.ms": 5000,
"message.template": "{\"day_time\":\"2013\",\"id\":\"1\",\"amnount\":\"10\"}",
"random.fields": "day_time:2013|2014|2015, id:1|2|3|4|5|6|7|8|9|10, amnount:10|90|100",
"event.timestamp.field": "event_ts"
}
}
- 依赖的jar包
操作mysql需要的jar包(flink jdbc connector下载地址 )
flink-connector-jdbc_2.11-1.12.0.jar
mysql-connector-java-8.0.19.jar(根据使用的mysql版本来选择,各版本下载地址 )
操作kafka需要的jar包(flink kafka connector下载地址 )
这里只需要下载这一个jar包即可:flink-sql-connector-kafka_2.11-1.12.0.jar
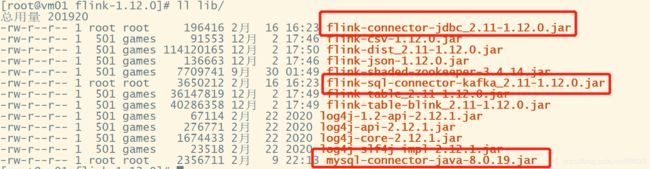
将上述3个jar包,拷贝到flink的lib目录下,如下图所示:
2.2 添加第3放依赖jar包的方法
第一种方法:下载连接器Jar包后后直接放到 flink/lib/目录下就可以使用了,其缺点是:
1、该方案存在jar冲突可能,特别是连接器多了以后
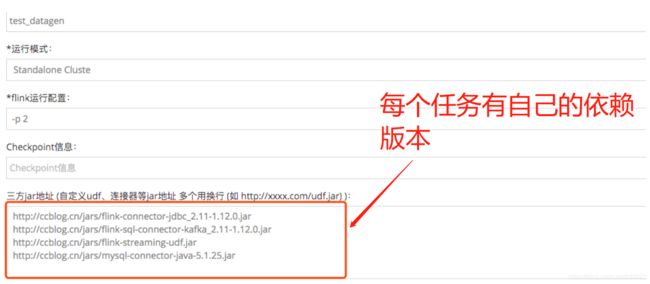
2、在非yarn模式下每次新增jar需要重启flink集群服务器第二种方法:配置每一个flink任务时,放到http的服务下填写到三方地址,例如设置内部的http repo下载源
公司内部建议放到内网的某个http服务
http://ccblog.cn/jars/flink-connector-jdbc_2.11-1.12.0.jar
http://ccblog.cn/jars/flink-sql-connector-kafka_2.11-1.12.0.jar
http://ccblog.cn/jars/flink-streaming-udf.jar
http://ccblog.cn/jars/mysql-connector-java-5.1.25.jar如下图所示:
3. 启动
3.1 启动flink
cd /work/flink/flink-1.12.0/bin
./start-cluster.sh
3.2 启动flink-streaming-platform-web
cd /work/flink/flink-streaming-platform-web/bin
sh deploy.sh start
//停止命令
sh deploy.sh stop
4. 配置flink-streaming-platform-web
4.1 登录页面
启动后,访问web页面
打开页面查看 http://127.0.0.1:9084/admin/index?message=nologin
登录号:admin 密码 123456。
4.2 系统配置
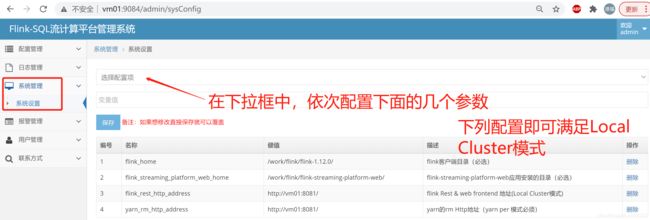
如下图,在下拉框中选择参数,在变量值文本框中填入对应的键值,点击保存即可。配置好的参数会出现在下面的列表中
4.3 任务配置
- 新增配置
在配置管理下,新增一个配置,即新建一个flink sql任务,并提交保存。

- 建表语句
需要先在mysql中创建flink_web.sync_test_2表,否则直接提交flink sql任务不会自动创建目标表。这里表sync_test_2 固定创建在flink_web库下。建表语句和flink sql代码如下
-- mysql中创建目标表
use flink_web;
CREATE TABLE `sync_test_2` (
`day_time` varchar(64) NOT NULL,
`total_gmv` bigint(11) DEFAULT NULL,
PRIMARY KEY (`day_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- =================================================
-- 配置flink sql任务时的sql逻辑
--flink sql
-- sink mysql table
CREATE TABLE sync_test_2 (
day_time string,
total_gmv bigint,
PRIMARY KEY (day_time) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://127.0.0.1:3306/flink_web_sample',
'table-name' = 'sync_test_2',
'username' = 'root',
'password' = 'adf_#Hasdfas380',
'scan.auto-commit' = 'false',
'sink.buffer-flush.max-rows' = '1'
);
-- kafka source
create table flink_test_3 (
id BIGINT,
day_time VARCHAR,
amnount BIGINT,
proctime AS PROCTIME ()
)
with (
'connector'='kafka',
'topic'='flink2',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers'='localhost:9092',
'format'='json'
);
-- ETL
INSERT INTO flink_web_sample.sync_test_2
SELECT day_time,SUM(amnount) AS total_gmv
FROM flink_test_3
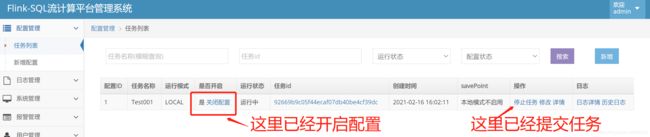
GROUP BY day_time;依次点击 开启配置 -> 提交任务
5. 观察运行结果
5.1 观察任务提交结果
点解日志详情,观察已提交任务的运行状况,如下图则表示任务提交成功,并且任务正在成功运行。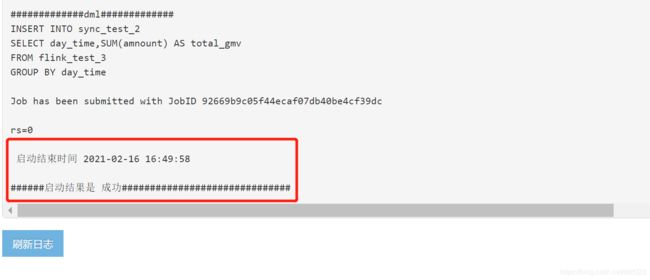
如果提交失败,请排查flink的log/下日志文件,和flink-streaming-platform-web的日志文件

5.2 观察数据变化
- 自动生成kafka实时数据
往kafka中不断写入实时数据,观察mysql中目标表中的结果。写入数据可以使用kafka-connect-datagen自动写入,json文件flink_web.source.datagen.json内容模板是:
{
"name": "flink_web.source.datagen",
"config": {
"connector.class": "com.github.xushiyan.kafka.connect.datagen.performance.DatagenConnector",
"tasks.max": "1",
"topic.name": "flink2",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": false,
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter.schemas.enable": false,
"poll.size": 10,
"poll.interval.ms": 5000,
"message.template": "{\"day_time\":\"2013\",\"id\":\"1\",\"amnount\":\"10\"}",
"random.fields": "day_time:2013|2014|2015, id:1|2|3|4|5|6|7|8|9|10, amnount:10|90|100",
"event.timestamp.field": "event_ts"
}
}执行数据生成命令:
curl -X POST http://localhost:8083/connectors \
-H 'Content-Type:application/json' \
-H 'Accept:application/json' \
-d @flink_web.source.datagen.json观察mysql结果:
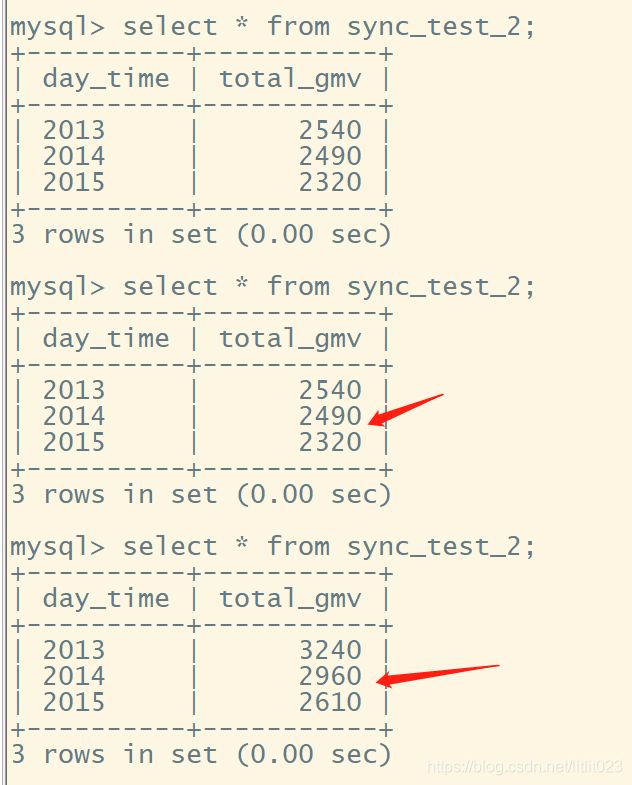
- 手动生成kafka实时数据
上述生成kafka数据时自动生成的,为了便于观察结果表中的汇总结果,我们可以手动往kafka中写入一条数据 {"day_time": "2013","id": 1,"amnount":10}
观察写入之前的结果表:

向kafka写入一条数据,首先进入到kafka的容器中,如下命令所示:
docker exec -it 27d6de189715 bash
cd /usr/bin
./kafka-console-producer --broker-list localhost:9092 --topic flink2进入到生产消息命令行之后,输入一条记录,如下图所示:

再次观察mysql中的汇总结果

5.3 在flink的ui上观察任务
访问flink的UI地址 http://vm01:8081/#/overview
观察正在运行的任务
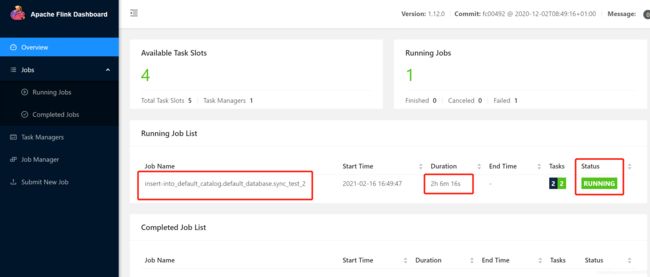
查看任务详情

6. 参考资料
https://blog.csdn.net/xinxin6193/article/details/112347736
https://github.com/paeonia-fragrans/flink-streaming-platform-web
https://github.com/zhp8341/flink-streaming-platform-web#%E4%B8%89%E5%8A%9F%E8%83%BD%E4%BB%8B%E7%BB%8D
https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/table/connectors/jdbc.html