【X先生】深度解析Python相关的10个岗位详细信息,一文读懂你到底该学些什么必要技能?(一)...
一、前言
写这篇文章的原因是X先生大三了,嗯,虽然学了点东西,肚子里有点货,但始终不知道外面的公司到底需要什么样的人才,我到底该继续学什么,问了几个大佬后,大佬们推荐我在拉勾网上看看。
于是再次爬取了拉勾网相关招聘信息,从Python爬虫/数据分析/后端/数据挖掘/全栈开发/运维开发/高级开发工程师/大数据/机器学习/架构师这个10个岗位,爬取了拉钩网上相应的职位信息和任职要求,数据分析可视化,终于知道了Python小白的我到底该学些什么了[文末正解],同时爬取了这10个职位的平均薪资和学历、工作经验要求,粗略的比较了一下各个职位,至于拉勾网上其他信息在之前的一篇爬虫实战中已经讲过了就不啰嗦了。
由于内容比较多,我就分两期推送给大家,希望对大家求职学习有所帮助。第一期中将给大家分析解剖Python爬虫/数据分析/后端/数据挖掘/全栈开发这五个职位。
二、和我一起动动手,动动脑
1.先获取薪资和学历、工作经验要求
(1)在
由于拉勾网数据加载是动态加载的,需要我们分析,分析方法如下:
我们发现网页内容是通过post请求得到的,返回数据是json格式,那我们直接拿到json数据即可。
我们只需要薪资和学历、工作经验还有单个招聘信息的,返回json数据字典中对应的英文为:positionId,salary, education, workYear。(positionId为单个招聘信息详情页面编号)
(2)操作代码
1)文件存储
def file_do(list_info):
# 获取文件大小
file_size = os.path.getsize(r'G:\lagou_anv.csv')
if file_size == 0:
# 表头
name = ['ID','薪资', '学历要求', '工作经验']
# 建立DataFrame对象
file_test = pd.DataFrame(columns=name, data=list_info)
# 数据写入
file_test.to_csv(r'G:\lagou_anv.csv', encoding='gbk', index=False)
else:
with open(r'G:\lagou_anv.csv', 'a+', newline='') as file_test:
# 追加到文件后面
writer = csv.writer(file_test)
# 写入文件
writer.writerows(list_info)
2)基本数据获取
# 1. post 请求 url
req_url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
# 2.请求头 headers
headers = {
'Accept': 'application/json,text/javascript,*/*;q=0.01',
'Connection': 'keep-alive',
'Cookie': '你的Cookie值,必须加上去',
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=',
'User-Agent': str(UserAgent().random),
}
def get_info(headers):
# 3.for 循环请求(一共30页)
for i in range(1, 31):
# 翻页
data = {
'first': 'true',
'kd': 'Python爬虫',
'pn': i
}
# 3.1 requests 发送请求
req_result = requests.post(req_url, data=data, headers=headers)
req_result.encoding = 'utf-8'
print("第%d页:"%i+str(req_result.status_code))
# 3.2 获取数据
req_info = req_result.json()
# 定位到我们所需数据位置
req_info = req_info['content']['positionResult']['result']
print(len(req_info))
list_info = []
# 3.3 取出具体数据
for j in range(0, len(req_info)):
salary = req_info[j]['salary']
education = req_info[j]['education']
workYear = req_info[j]['workYear']
positionId = req_info[j]['positionId']
list_one = [positionId,salary, education, workYear]
list_info.append(list_one)
print(list_info)
# 存储文件
file_do(list_info)
time.sleep(1.5)
(3)运行结果
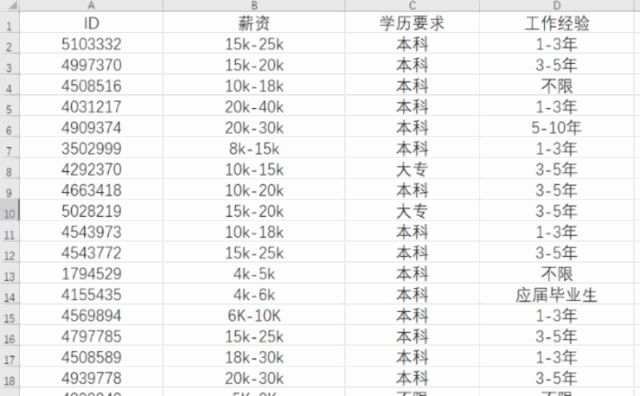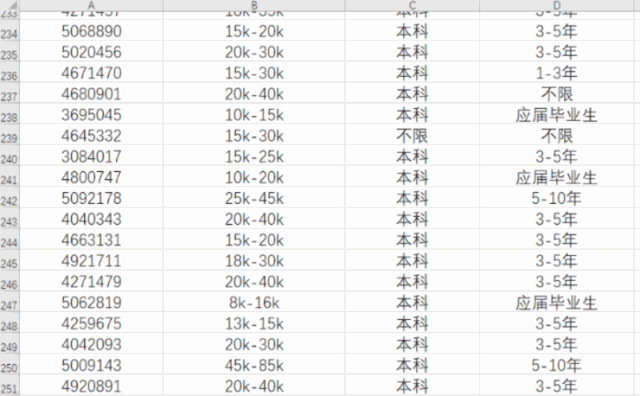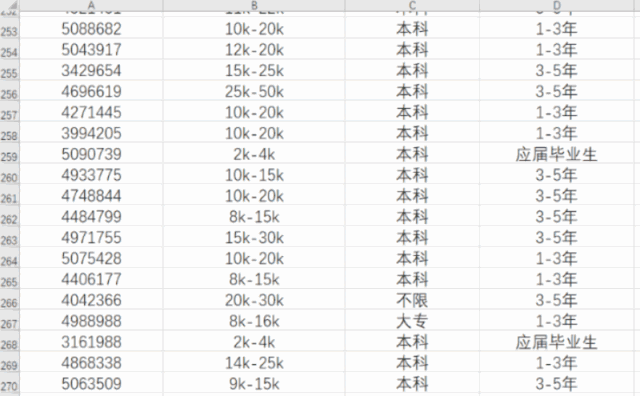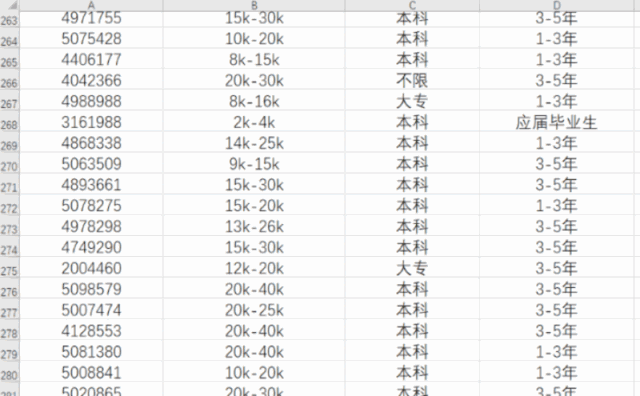
2.根据获取到的`positionId`来访问招聘信息详细页面
(1)根据`positionId`还原访问链接
position_url = []
def read_csv():
# 读取文件内容
with open(r'G:\lagou_anv.csv', 'r', newline='') as file_test:
# 读文件
reader = csv.reader(file_test)
i = 0
for row in reader:
if i != 0 :
# 根据positionID补全链接
url_single = "https://www.lagou.com/jobs/%s.html"%row[0]
position_url.append(url_single)
i = i + 1
print('一共有:'+str(i-1)+'个')
print(position_url)
(2)访问招聘信息详情页面,获取职位描述(岗位职责和岗位要求)并清理数据
def get_info():
for position_url in position_urls:
work_duty = ''
work_requirement = ''
response00 = get_response(position_url,headers = headers)
time.sleep(1)
content = response00.xpath('//*[@id="job_detail"]/dd[2]/div/p/text()')
# 数据清理
j = 0
for i in range(len(content)):
content[i] = content[i].replace('\xa0',' ')
if content[i][0].isdigit():
if j == 0:
content[i] = content[i][2:].replace('、',' ')
content[i] = re.sub('[;;.0-9。]','', content[i])
work_duty = work_duty+content[i]+ '/'
j = j + 1
elif content[i][0] == '1' and not content[i][1].isdigit():
break
else:
content[i] = content[i][2:].replace('、', ' ')
content[i] = re.sub('[、;;.0-9。]','',content[i])
work_duty = work_duty + content[i]+ '/'
m = i
# 岗位职责
write_file(work_duty)
print(work_duty)
# 数据清理
j = 0
for i in range(m,len(content)):
content[i] = content[i].replace('\xa0',' ')
if content[i][0].isdigit():
if j == 0:
content[i] = content[i][2:].replace('、', ' ')
content[i] = re.sub('[、;;.0-9。]', '', content[i])
work_requirement = work_requirement + content[i] + '/'
j = j + 1
elif content[i][0] == '1' and not content[i][1].isdigit():
# 控制范围
break
else:
content[i] = content[i][2:].replace('、', ' ')
content[i] = re.sub('[、;;.0-9。]', '', content[i])
work_requirement = work_requirement + content[i] + '/'
# 岗位要求
write_file2(work_requirement)
print(work_requirement)
print("-----------------------------")
(3)运行结果

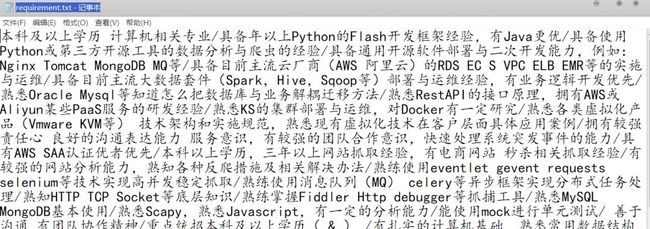
require
三、可视化分析第一期5个Python相关的岗位学历要求、薪资、工作经验要求、必要技能
(1)Python爬虫岗位
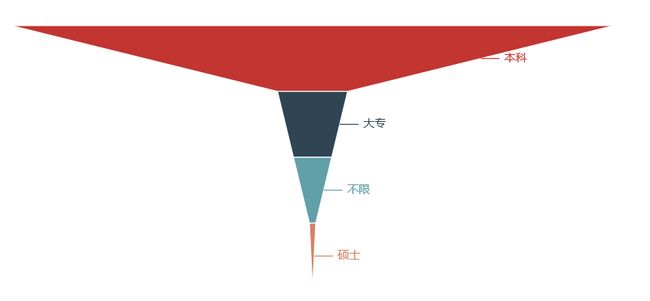
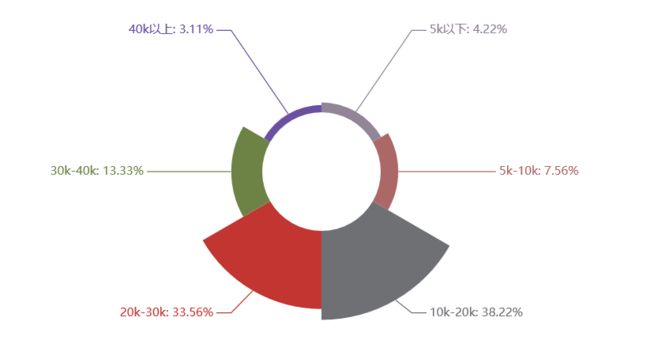
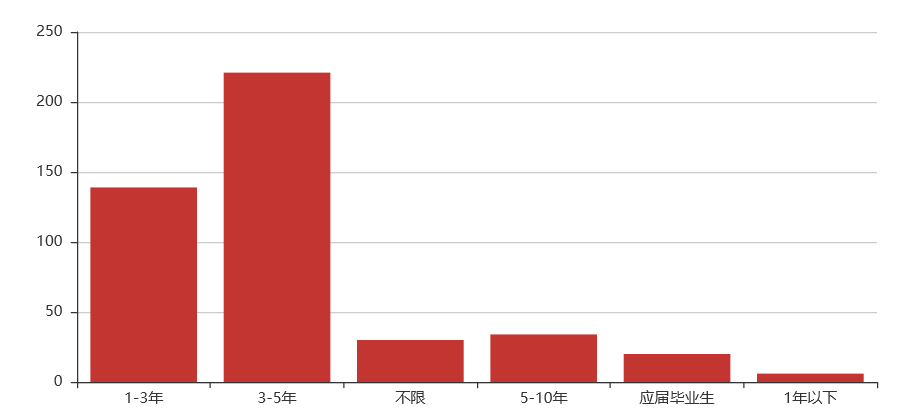

关键词解析:
(2)Python数据分析岗位
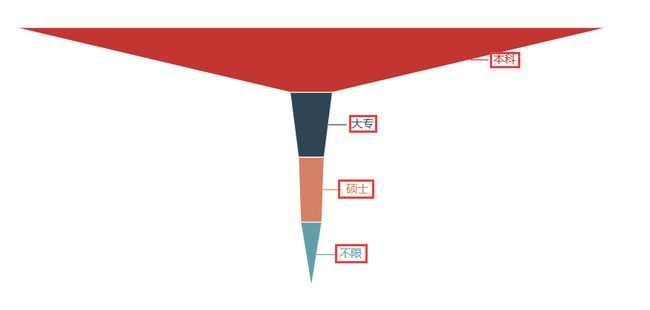
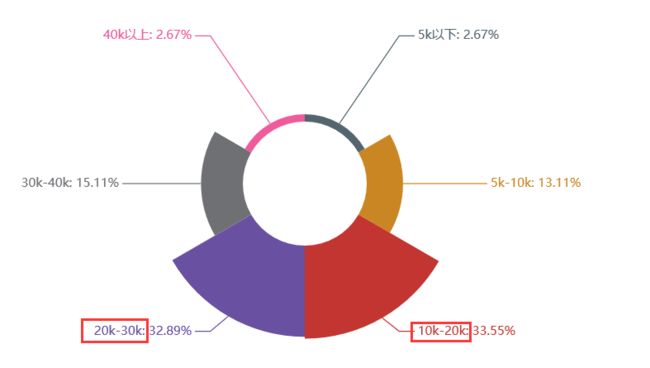
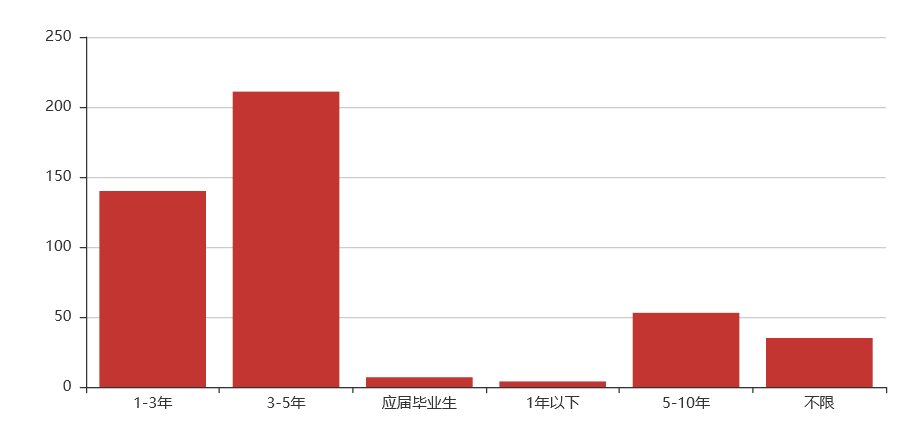

关键词解析:
学历:本科(硕士比例有所增高)
(3)Python后端岗位
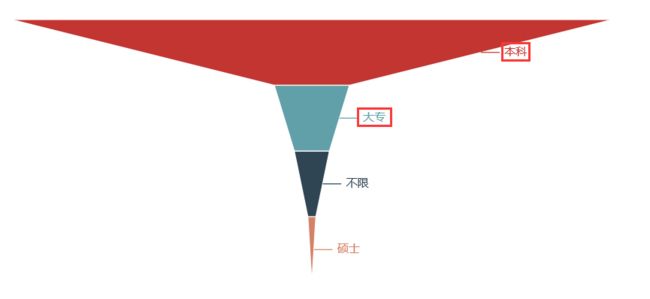
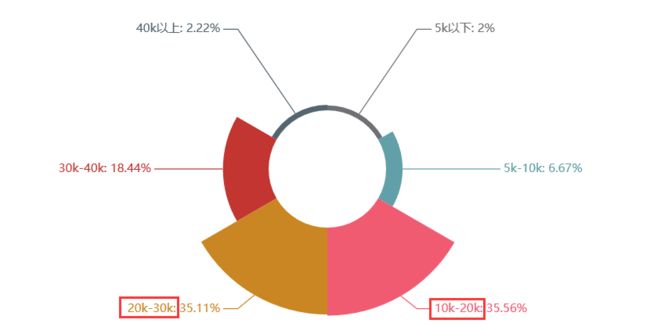
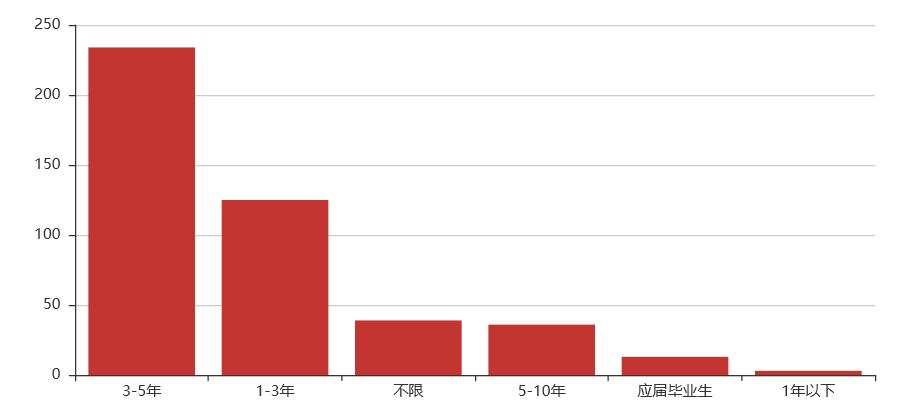

关键词解析:
学历:本科
(4)Python数据挖掘岗位
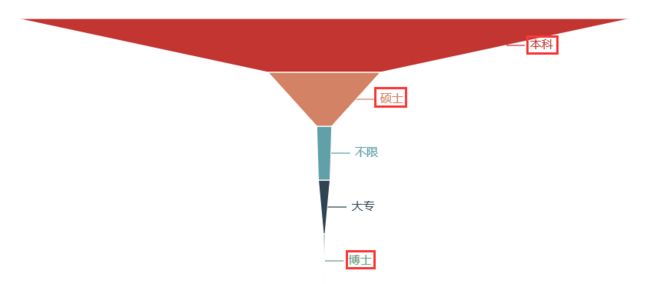

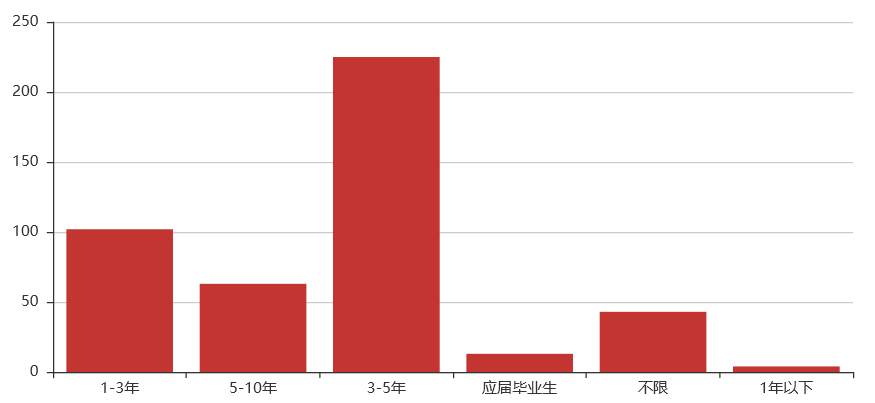

关键词解析:
学历:本科(硕士)
(5)Python全栈开发岗位

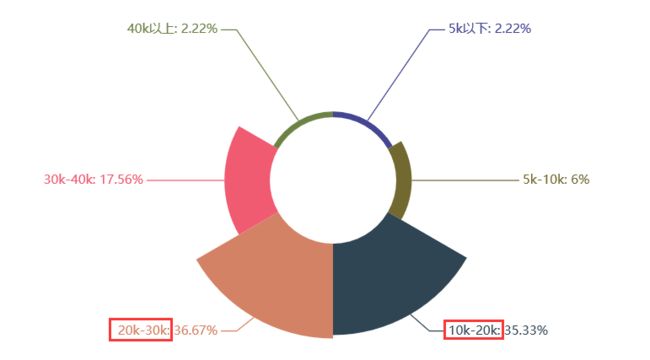
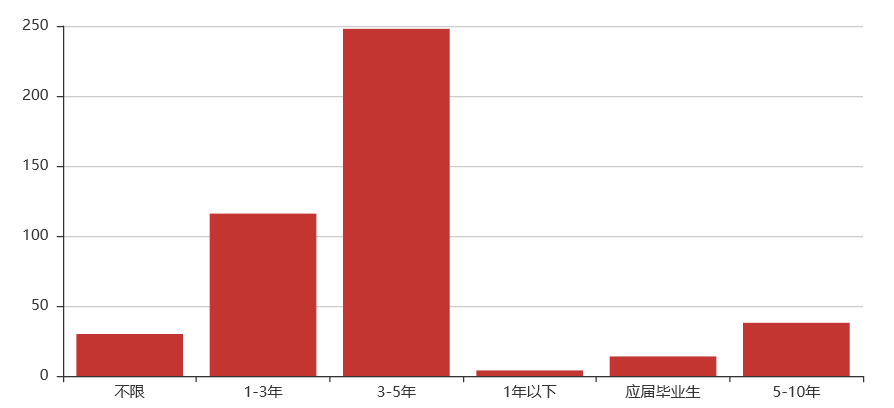

关键词解析:
四、总结
从上文可以看出,Python相关的各个岗位薪资还是不错的,基本上所有岗位10k以上的占90%,20k以上的也基本都能占60%左右,而且学历上普遍来看,本科学历占70%以上,唯一的是需要工作经验,一般得有个3-5年工作经验,也就是如果24岁本科毕业,27岁就有很大机会拿到月薪20k以上,有没有心动嘿,没有学错Python,人生苦短,我选Python.
通过上面的分析不知道对大家有没有帮助,其实看各个岗位的必须技能还是建议大家去拉钩网上看具体的,很明显的,这些词云图显示的并不完全正确,不过还是可以参考的哈,特别是对于薪资这块,绝对准确的。
后面的学习安排,我也会好好制定一下,不再无方向的前进三步后退两步,有针对性的学习,有针对性的分享学习笔记。
嘿嘿,日常福利时间到了,本推文下留言,说出你对生活最真实的感受,明天晚上20:00,我将选出最走心的留言,赠送一本《图形数据可视化:技术、工具与案例》([美] 科里·拉纳姆).。

第二期赠书幸运读者名单
留言区:123(77个赞)和小插曲(127个赞)
转发集赞区:美丽说(198个赞)和永福(263个赞)
极简Python学习群区:souththth(手气最佳)和TEMG(手气最差)
恭喜以上幸运读者,也谢谢大家的积极参与,以后我会为大家争取更多福利,后期赠书活动将从点赞、留言、转发本公号推文最多的读者里面优先选择。
往期精彩
进学习交流群
扫码加X先生微信进学习交流群