如何让多层神经网络学习呢?我们已了解了使用梯度下降来更新权重,反向传播算法则是它的一个延伸。以一个两层神经网络为例,可以使用链式法则计算输入层-隐藏层间权重的误差。
要使用梯度下降法更新隐藏层的权重,你需要知道各隐藏层节点的误差对最终输出的影响。每层的输出是由两层间的权重决定的,两层之间产生的误差,按权重缩放后在网络中向前传播。既然我们知道输出误差,便可以用权重来反向传播到隐藏层。
例如,输出层每个输出节点 k 的误差是 δ_ko ,隐藏节点 j 的误差即为输出误差乘以输出层-隐藏层间的权重矩阵(以及梯度)。
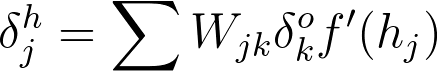
然后,梯度下降与之前相同,只是用新的误差:

其中 w_{ij} 是输入和隐藏层之间的权重, x_i 是输入值。这个形式可以表示任意层数。权重更新步长等于步长乘以层输出误差再乘以该层的输入值。
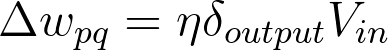
现在,你有了输出误差,\delta_{output},便可以反向传播这些误差了。V_{in} 是该层的输入,比如经过隐藏层激活函数的输出值。
范例
以一个简单的两层神经网络为例,计算其权重的更新过程。假设该神经网络包含两个输入值,一个隐藏节点和一个输出节点,隐藏层和输出层的激活函数都是 sigmoid,如下图所示。(注意:图底部的节点为输入值,图顶部的 y^ 为输出值。输入层不计入层数,所以该结构被称为两层神经网络。)
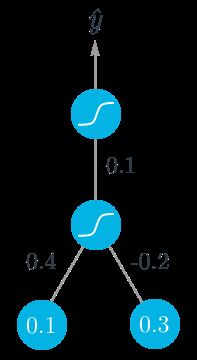
假设我们试着训练一些二进制数据,目标值是 y=1。我们从正向传播开始,首先计算输入到隐藏层节点
h=∑iwixi=0.1×0.4−0.2×0.3=−0.02
以及隐藏层节点的输出
a=f(h)=sigmoid(−0.02)=0.495.
然后将其作为输出节点的输入,该神经网络的输出可表示为
y^=f(W⋅a)=sigmoid(0.1×0.495)=0.512.
基于该神经网络的输出,就可以使用反向传播来更新各层的权重了。sigmoid 函数的导数 f′(W⋅a)=f(W⋅a)(1−f(W⋅a)),输出节点的误差项(error term)可表示为
δo=(y−y^)f′(W⋅a)=(1−0.512)×0.512×(1−0.512)=0.122.
现在我们要通过反向传播来计算隐藏节点的误差项。这里我们把输出节点的误差项与隐藏层到输出层的权重 W相乘。隐藏节点的误差项 δjh=∑kWjkδkof′(hj),因为该案例只有一个隐藏节点,这就比较简单了
δh=Wδof′(h)=0.1×0.122×0.495×(1−0.495)=0.003
有了误差,就可以计算梯度下降步长了。隐藏层-输出层权重更新步长是学习速率乘以输出节点误差再乘以隐藏节点激活值。
ΔW=ηδoa=0.5×0.122×0.495=0.0302
然后,输入-隐藏层权重 wi 是学习速率乘以隐藏节点误差再乘以输入值。
Δwi=ηδhxi=(0.5×0.003×0.1,0.5×0.003×0.3)=(0.00015,0.00045)
从这个例子中你可以看到 sigmoid 做激活函数的一个缺点。sigmoid 函数导数的最大值是 0.25,因此输出层的误差被减少了至少 75%,隐藏层的误差被减少了至少 93.75%!如果你的神经网络有很多层,使用 sigmoid 激活函数会很快把靠近输入层的权重步长降为很小的值,该问题称作梯度消失。后面的课程中你会学到在这方面表现更好,也被广泛用于最新神经网络中的其它激活函数。
用 NumPy 来实现
现在你已经有了大部分用 NumPy 来实现反向传播的知识。
但是之前接触的只是单个节点的误差项。现在在更新权重时,我们需要考虑隐藏层 每个节点 的误差 δj:
Δwij=ηδjxi
首先,会有不同数量的输入和隐藏节点,所以试图把误差与输入当作行向量来乘会报错
hidden_errorinputs---------------------------------------------------------------------------ValueError Traceback (most recent call last)
另外,现在 wij 是一个矩阵,所以右侧对应也应该有跟左侧同样的维度。幸运的是,NumPy 这些都能搞定。如果你用一个列向量数组和一个行向量数组相乘,它会把列向量的第一个元素与行向量的每个元素相乘,组成一个新的二维数组的第一行。列向量的每一个元素依次重复该过程,最后你会得到一个二维数组,形状是 (len(column_vector), len(row_vector))
。
hidden_error*inputs[:,None]array([[ -8.24195994e-04, -2.71771975e-04, 1.29713395e-03], [ -2.87777394e-04, -9.48922722e-05, 4.52909055e-04], [ 6.44605731e-04, 2.12553536e-04, -1.01449168e-03], [ 0.00000000e+00, 0.00000000e+00, -0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, -0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, -0.00000000e+00]])
这正好是我们计算权重更新的步长的方式。跟以前一样,如果你的输入是一个一行的二维数组,你可以用 hidden_error*inputs.T,但是如果inputs是一维数组,就不行了。
反向传播练习
- 接下来你将用代码来实现一次两个权重的反向传播更新。我们提供了正向传播的代码,你来实现反向传播的部分。
- 要做的事
计算网络输出误差
计算输出层误差项
用反向传播计算隐藏层误差项
计算反向传播误差的权重更新步长
backprop.py
solution.py
import numpy as np
def sigmoid(x):
"""
Calculate sigmoid
"""
return 1 / (1 + np.exp(-x))
x = np.array([0.5, 0.1, -0.2])
target = 0.6
learnrate = 0.5
weights_input_hidden = np.array([[0.5, -0.6],
[0.1, -0.2],
[0.1, 0.7]])
weights_hidden_output = np.array([0.1, -0.3])
## Forward pass
hidden_layer_input = np.dot(x, weights_input_hidden)
hidden_layer_output = sigmoid(hidden_layer_input)
output_layer_in = np.dot(hidden_layer_output, weights_hidden_output)
output = sigmoid(output_layer_in)
## Backwards pass
## TODO: Calculate output error
error = target - output
# TODO: Calculate error term for output layer