手把手搭建一个【卷积神经网络】
前言
本文介绍卷积神经网络的入门案例,通过搭建和训练一个模型,来对10种常见的物体进行识别分类;使用到CIFAR10数据集,它包含10 类,即:“飞机”,“汽车”,“鸟”,“猫”,“鹿”, “狗”,“青蛙”,“马”,“船”,“卡车” ;共 60000 张彩色图片;通过搭建和训练卷积神经网络模型,对图像进行分类,能识别出图像是“汽车”,或“鸟”,还是其它。
思路流程
- 导入 CIFAR10 数据集
- 探索集数据,并进行数据预处理
- 构建模型(搭建神经网络结构、编译模型)
- 训练模型(把数据输入模型、评估准确性、作出预测、验证预测)
- 使用训练好的模型
一、导入 CIFAR10 数据集
使用到CIFAR10数据集,它包含10 类,即:“飞机”,“汽车”,“鸟”,“猫”,“鹿”, “狗”,“青蛙”,“马”,“船”,“卡车” ;共 60000 张彩色图片;
此数据集中 50000 个样例被作为训练集(每张图片对于一个标签),剩余 10000 个样例作为测试集(每张图片也对于一个标签)。类别之间相互独立,不存在重叠的部分。使用以下代码完成数据集导入:
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
二、探索集数据,并进行数据预处理
将测试集的前 30 张图片和类名打印出来
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(30):
plt.subplot(5,6,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
# 由于 CIFAR 的标签是 array, 因此需要额外的索引(index)。
plt.xlabel(class_names[train_labels[i][0]])
plt.show()打印出来的效果是这样的:

数据集预处理
下面进行数据集预处理,将像素的值标准化至0到1的区间内:
# 将像素的值标准化至0到1的区间内。
train_images, test_images = train_images / 255.0, test_images / 255.0为什么是除以255呢?由于图片的像素范围是0~255,我们把它变成0~1的范围,于是每张图像(训练集、测试集)都除以255。
三、构建模型
常见卷积神经网络(CNN),主要由几个 卷积层Conv2D 和 池化层MaxPooling2D 层组成。卷积层与池化层的叠加实现对输入数据的特征提取,最后连接全连接层实现分类。
1)特征提取——卷积层与池化层
CNN 的输入是张量 (Tensor) 形式的 (image_height, image_width, color_channels),包含了图像高度、宽度及颜色信息。通常图像使用 RGB 色彩模式,color_channels 为 (R,G,B) 分别对应 RGB 的三个颜色通道,即:image_height 和 image_width 根据图像的像素高度、宽度决定;color_channels是3,对应RGB的3通道。
CIFAR 数据集中的图片,形状是 (32, 32, 3),我们可以在声明第一层时将形状赋值给参数 input_shape 。
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))查看一下网络模型:tf.keras.utils.plot_model(model)
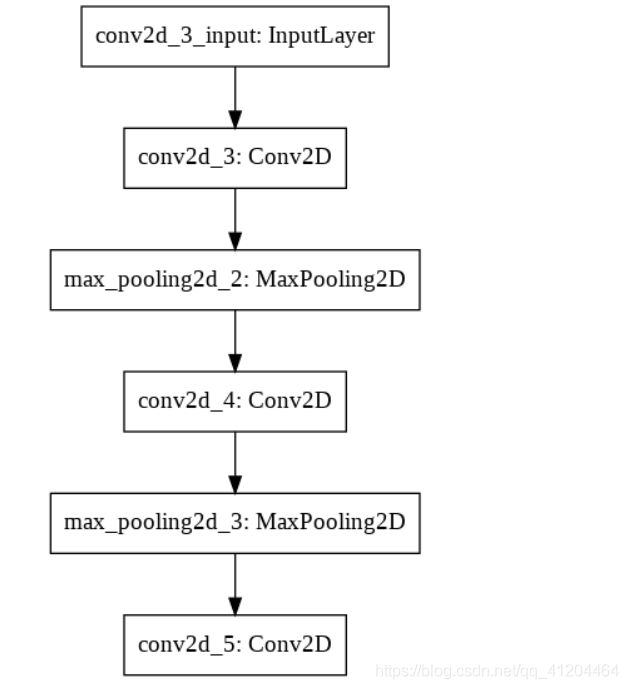
在上面的模型种每个 Conv2D 和 MaxPooling2D 层的输出都是一个三维的张量 (Tensor),其形状描述了 (height, width, channels)。越深的层中,宽度和高度都会收缩。
2)实现分类——全连接层
Dense 层等同于全连接 (Full Connected) 层,通过上面的卷积层和池化层,我们已经提取到图像的特征了,下面通过搭建Dense 层实现分类。
Dense 层的输入为向量(一维),但前面层的输出是3维的张量 (Tensor) 即:(4, 4, 64)。因此您需要将三维张量展开 (Flatten) 到1维,之后再传入一个或多个 Dense 层。
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))CIFAR 数据集有 10 个类,因此您最终的 Dense 层需要 10 个输出及一个 softmax 激活函数。
查看完整的 CNN 结构:tf.keras.utils.plot_model(model)

或者用这样方式看看:model.summary()

可以看出,在被传入两个 Dense 层之前,通过Flatten层处理后,形状为 (4, 4, 64) 的输出被展平成了形状为 (1024) 的向量。
3)编译模型
主要是为模型选择损失函数loss、优化器 optimizer、衡量指标metrics(通常用准确度accuracy 来衡量的)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
四、训练模型
这里我们输入准备好的训练集数据(包括图像、对应的标签),测试集的数据(包括图像、对应的标签),模型一共训练10次
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))下图是训练过程的截图:
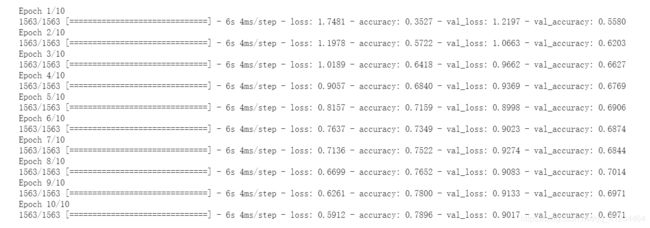
通常loss越小越好,对了解释下什么是loss;简单来说是 模型预测值 和 真实值 的相差的值,反映模型预测的结果和真实值的相差程度;
通常准确度accuracy 越高,模型效果越好。
评估模型
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print("测试集的准确度", test_acc)看看效果:

五、使用模型
通常使用 model.predict( ) 函数进行预测。
完成代码:
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
# 导入 CIFAR10 数据集
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# 将测试集的前 30 张图片和类名打印出来
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(30):
plt.subplot(5,6,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
# 由于 CIFAR 的标签是 array, 因此需要额外的索引(index)。
plt.xlabel(class_names[train_labels[i][0]])
plt.show()
# 下面进行数据集预处理,将像素的值标准化至0到1的区间内:
train_images, test_images = train_images / 255.0, test_images / 255.0
# 构建模型
# 1)特征提取——卷积层与池化层
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
# 2)实现分类——全连接层
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
# 3)编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
# 评估模型
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print("测试集的准确度", test_acc)
参考:一篇文章“简单”认识《卷积神经网络》(更新版)
https://tensorflow.google.cn/tutorials/images/cnn