记录一下个人对于公众号算法爱好者和程序员小灰的阅读摘要,目录如下,
1. B-树
2. B+树
3. 跳跃表
4. 动态规划
5. 找缺失数
6. 判断2的乘方
7. bitmap算法
8. bloomFilter
9. 决策树算法
10. A*寻路算法/启发式搜索
11. Base64算法
12. 对称加密 vs 非对称加密 vs hash
13. MD5算法
14. SHA算法
15. AES算法
16. 红黑树
17. HashMap
18. cocurrentHashmap
19. 单例
20. volatile关键字
21. Netty
22. 微服务架构
23. ThreadPoolExecutor
B-树(B-tree)
- B-树就是B树,中间的横线并不是减号,B减树的叫法是错误的
- 二叉查找树的时间复杂度是O(logN),但是数据库索引是存储在磁盘上的,当数据量比较大的时候,索引的大小可能就有几个G。利用索引查询的时候,一般不能将其全部加载到内存,而是逐一加载每一个磁盘页,这里的磁盘页对应着索引树的节点!

决定磁盘IO次数的是索引树的高度(最下面的叶子节点高度是1,根节点的深度是1),为了减少磁盘IO的次数,就需要把原来瘦高的树结构变得矮胖


每一个节点最多包含k个孩子,k称为B-树的阶,k的大小取决于磁盘页的大小。特征:
- root节点至少两个子节点
- 中间节点都包含k/2-1k-1个元素和k/2k个子节点
- 每个叶子节点都包含k/2-1~k-1个元素
- 所有叶子节点都位于同一层
- 节点中元素升序排列
- 3阶,k/2=2?
查询5的比较,
- 二叉查找树:9->5(2次)
- B-树:9->(2,6)->(3,5)(5次)
B-树在查询过程中的比较次数其实不比二叉查找树少(如查询5),但是由于加载的该页节点数量多,都在内存中,内存多次比较耗时远小于从二叉查找树的磁盘加载节点到内存中的耗时
B+树(B+tree)
B+树是基于B-树的一种变体,有着更高的查询性能

特征:
- 每一个父节点的元素都出现于子节点中,是子节点的最大(或最小)元素
- 卫星数据,指的是索引元素所指向的数据记录
- B-树中,每个节点都带有卫星数据
- B+树中,只有叶子节点带有卫星数据,其余中间节点仅仅是索引,没有任何数据关联
- B+树中间节点没有卫星数据,所以同样大小的磁盘页可以容纳更多的节点元素。意味着数据量相同的情况下,B+树比B-树更矮胖,因此查询时IO次数更少
- B+树的查询必须最终查找到叶子节点,而B-树只要找到匹配元素即可,无论匹配元素处于根节点还是中间节点还是叶子节点
- 所有叶子节点形成有序链表,便于范围查询,查询性能稳定
跳跃表(skiplist)
需求:搭建一个拍卖,拍卖商品几十万件对应数据库商品表的几十万条记录。
方案:全量查询排序的处理?一般情况是先拿query去数据库index找到对应的doc,如果在master的时候将不同slave的docs merge起来再sort,最后又mater返回sorted result给client。
拍卖行商品列表是线性的,最容易表达线性结构的自然是数组和链表,但是它们在插入新商品的时候,存在性能问题,
- 数组:
- 查位,查找新商品的插入位置,可以用二分查找法length/2, O(1)的随机查询性能,O(logN)
- 插入,原数组中大于新商品的都要右移,给新元素腾出空位,O(N)
- 总复杂度O(N)+O(logN)
- 链表:
- 查位,无法使用二分查找,因为length不知道,只能新商品与原链表中的节点逐一比较大小来确定位置,O(N)
- 插入,链表插入是O(1)
- 总体复杂度O(N)
跳跃表是一种基于有序链表的扩展,简称跳表。
跳跃表插入节点的流程:
- 新节点与各层索引节点逐一比较,确定原链表的插入位置,O(logN)
- 把新节点插入到原链表O(1)
- 利用抛硬币的随机方式,决定新节点是否提升为上一级索引O(logN)
- 总体时间复杂度O(logN),空间复杂度O(N)



跳跃表利用了空间换时间策略。
应用场景:
- redis当中的sorted-set/lucene index就是使用了跳跃表这种有序链表(memory,跳跃表简化了集合插入复杂度)
- 而在关系型数据库中却是使用B+树这种数据结构来维护有序的记录集合(disk,B+树减少了磁盘IO次数)
动态规划(dynamic programming)
问题:需要爬上第十台阶。一步只能走1个台阶或2个台阶,那么还差一步就到第十个台阶,那么会出现多少种情况?
F(10) = F(9) + F(8) (第一种是从9级到10级,第二种是从8级到10级)
F(N) = F(N-1) + F(N-2) (N >2),状态转移方程,最优子结构,
F(2) = 2,边界
F(1) = 1,边界
解法:
- 使用递归方式,但是递归方式N越大,重复计算部分就越多,O(2^N)
- 备忘录算法replay,记录每次F(N)的结果,先找Map里的,没有再递归计算,O(N), O(N)
- 因为F(N)只需要保留F(N-1)和F(N-2),只需要2个状态,而备忘录算法是保留全部状态,所以既不需要递归,也不需要备忘录算法,直接递推最简便,O(N), O(1)
找缺失数
题目:给出一个包含 0 .. N 中 N 个数的序列,找出0 .. N 中没有出现在序列中的那个数。
解法:异或(01=1,11=0,00=0,0N=N)
result = 0....NArray[0]....^Array[N-1]
判断2的乘方
特征:
- 如果一个整数是2的乘方,那么它转换成2进制的时候,只有最高位是1(8 -> 1000)
- 如果二进制结果减去1,那么就是全1的情况( 8-1=7 -> 111)
- 那么N ^ (N-1) -> 0 (N是2的乘方数)
- 一般情况,N^N-1能够消除最右边的1 (76=111110=110)
bitmap算法
背景:通过用户标签,实现多样的用户群体统计。比如统计用户的男女比例,统计喜欢旅游的用户数量等。
设计:mysql表结构

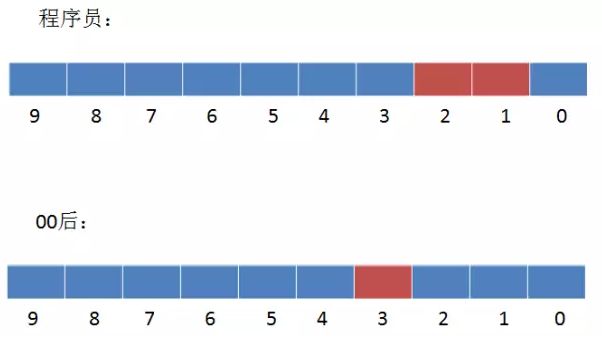
要想统计所有90后的程序员该怎么做呢?
Select count(distinct Name) as 用户数 from table where age = '90后' and Occupation = '程序员';
要想统计所有使用苹果手机或者00后的用户总合该怎么做?
Select count(distinct Name) as 用户数 from table where Phone = '苹果' or age = '00后';
问题:
随着标签越来越多,表结构的列数量就越来越多,同时sql语句的where拼接也越来越臃肿。
BITMAP: 每个标签一个bitmap数组,数组长度表示为用户数,bitmap数组的数量表示为有多少类标签
- 建立用户名与用户id的映射(bitmap遍历不能用string,只能是bitmap数组的第几位)

- 让每一类标签存储包含此标签的所有用户ID(也可以是全部用户,只是第几位用户的数组posi为0而已),每一类标签都是一个独立的bitmap

- 最后实现
- 例子
- 如何查找使用苹果手机的程序员用户?

- 如何查找所有男性或者00后的用户?

优势:
- 非常节约存储空间
- 高性能的位运算操作(&, |,^)
劣势:
- 不支持非运算(!)。全量异或可以解决这个问题
开源方案:
java bitSet
google EWAHCompressedBitmap
bitmap进阶
RLE游程编码
布隆算法bloomFilter
一种以bitMap集合为基础的去重算法。
如果说爬虫,因为爬取得是网页URL,String类型,与数字类型不一样,因为不同string,hashCode可能相同,所有不能直接使用单个bitmap就来判断2个url是否相同。
映射流程:(bloomFilter只需要一个bitMap,但是一个key多次要映射)
- 创建一个空的bitmap集合
- 把第一个URL按照三种hash算法,分别生成三个不同的hash值
- 分别判断key1的三个hash值对应的bitmap位置是否为1,只要全部都为1的情况,才认为key1已经存在了
误判几率:
- 虽然bloomFilter极力降低了hash冲突的几率,但是仍存在一定的误判率
- 可以在单key hash次数与hash长度,冲突率之间做取舍
- 因为bloomFilter只用了一个bitmap,如果单个key的每次hash都对应一个bitmap,那么这样的方式就会占用翻倍的空间,反而不如用hashset好
- 如果想完全杜绝误判,可以增加一个白名单机制
决策树算法
树是一种很重要的数据结构,可以为我们缩小问题规模,实现高效的查找。
背景:猜人名游戏。游戏中,出题者写下一个明星的名字,其他人需要猜出这个人是谁。当然,如果游戏规则仅此而已的话,几乎是无法猜出来的,因为问题的规模太大了。为了降低游戏的难度,答题者可以向出题者问问题,而出题者必须准确回答是或者否,答题者依据回答提出下一个问题,如果能够在指定次数内确定谜底,即为胜出,
- 是男的吗?Y
- 是亚洲人吗?Y
- 是中国人吗?N
- 是印度人吗?Y
- ……

算法思想:
- 每次选择其中一个特征对样本集合进行分类
- 对分类后的所有子集递归进行步骤1
最重要的是第一步,即需要想出一个重要的策略,即选择什么样的特征可以实现最好的分类效果。使用纯净度来评价分类效果,熵来量化纯净度。
熵表示一个系统的混乱程度,熵越大,说明数据集纯净度越低;当数据集都是同一个类别的时候,此时熵是0。目标就是使得熵最低。

一共6组样本,每一组样本包含4个特征,分别是年龄段,学历,收入,婚姻状况,最后一列数所属分类,代表该组/用户是否购买了该产品。使用这些样本去训练一颗决策树如下:

使用上述决策树来判断一个新晋用户(需要将该用户的4个特征都拿到)是否会购买该产品。
A*寻路算法/启发式搜索
前提:
OpenList,可达格子
CloseList,已达到格子
F=G+H,G起点走到当前格的成本;H当前格到目标格的距离,不考虑障碍物。

起点(1,2),终点(5,2)。过程,
- 计算当期点的可达点
- Fmin是(2,2),所以将其加入移出openList,加入closeList
- 看当前格子(2,2)的上下左右,是否在openlist当中,如果不在,加入openList,并计算F
Base64算法
文本协议(http)
二进制协议(pb, thrift)
字节码byte是8bit,base64可以将原来ASCII字符打印成6bit字符。8,6最小公倍数24。意味着可以用4个base64字符(TWFu)来表达3个传统的8bit字符(Man)。

base64索引表(0-A,46-u,19-T,20-U)
对称加密 vs 非对称加密 vs hash
对称加密,一方通过密钥将信息加密后,把密文传给另一方,另一方通过这个相同的密钥将密文解密,转换成可以理解的明文,这类算法在加密和解密时使用相同的密钥,这组密钥成为在两个或多个成员间的共同秘密,
指加密和解密使用相同密钥的加密算法
明文 <-> 密钥 <-> 密文
常见的对称加密算法有DES、3DES、Blowfish、IDEA、RC4、RC5、RC6和AES
非对称加密,首先要有一对key,一个被称为private key私钥,一个成为public key公钥,然后可以把你的public key分发给想给你传密文的用户,然后这些用户使用该public key加密过的密文,只有使用你的private key才能解密。也就是说,只要你自己保存好你的private key,就能确保,别人想给你发的密文不被破解,所以你不用担心盟友的密钥被盗,
指加密和解密使用不同密钥的加密算法,也称为公私钥加密
常见的非对称加密算法有:RSA、ECC(移动设备用)、Diffie-Hellman、El Gamal、DSA(数字签名用)
SSH的加密原理中,使用到了RSA非对称加密算法
hash算法,Hash算法特别的地方在于它是一种单向算法,用户可以通过Hash算法对目标信息生成一段特定长度的唯一的Hash值,却不能通过这个Hash值重新获得目标信息。因此Hash算法常用在不可还原的密码存储、信息完整性校验等。
常见的Hash算法有MD2、MD4、MD5、HAVAL、SHA
消息安全传输
用户甲乙之间先建立安全通信信道,再开始传输具体消息,
- 甲生成pk1(public key,公钥)和sk1(secret key,私钥)
- 甲在Internet中传输pk1给乙(黑客可以截取到pk)
- 乙接收到pk1后,乙生成非对称加密(pk2, sk2)
- 乙用pk1对pk2加密,并传给甲(pk1加密的只有sk1能加密)(黑客可以截取pk1加密过的pk2)
- 甲收到pk1加密过的pk2后,用sk1解密,得到pk2
- 甲用pk2对对称密钥keyX加密,然后传给乙(可截取)
- 乙用sk2解密得到keyX
- 后续甲乙双方就基于keyX来通信(先非对称加密,再对称加密)

MD5算法, message digest algorithm
就是信息摘要的一种实现,它可以从任意长度的明文字符串生成128位的哈希值。
生成:

传输:
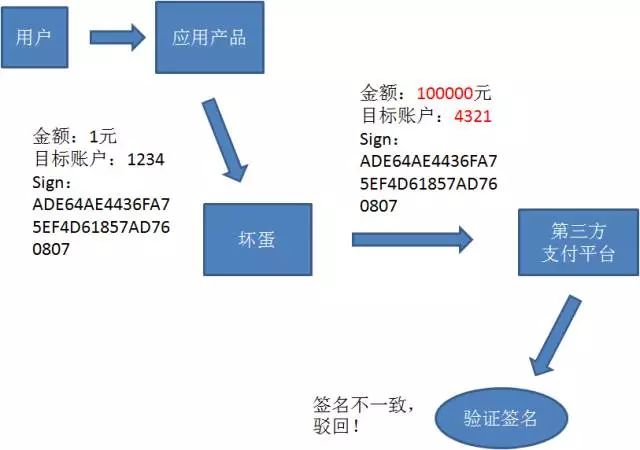
传输内容是(拼接明文+MD5(拼接明文))
MD5破解
一般不需要原文一致,而是MD5值一致即可。
设MD5的哈希函数是H(X),那么:
H(A) = M
H(B) = M
任意一个B即为破解结果。
B有可能等于A,也可能不等于A。即殊途同归,
- 暴力枚举法:复杂度,假设只考虑大小写和数字,每一位有62种可能,那么8位密码的排列组合就是62^8(时间换空间)
- 字典法:628种可能性,每一对映射占xx=(128+8chars)位。那么需要628 * xx bit
- 彩虹表:函数族Rk(k=1,2,3,4,..)将hash密文空间映射回明文的字符空间
彩虹表例子,
- qshud(明文) -> e978c6b019ac22a3fd05b14d36621852(32位MD5密文),最简单的转化处理就是直接截取第一个字符e;
- e -> e1671797c52e15f763380b45e841ec32,截取前两位;
- e1 -> cd3dc8b6cffb41e4163dcbd857ca87da,截取前三位
- cd3 -> XXX,假设截取到前k位(k=8)
- XXX -> 5626cf5e6f1093c2840a16512f62c3b5
- 5626cf5e
- 最后存储字符串qshud和5626cf5e
- 下一步就是查表过程(从中间链的倒数开始遍历)
SHA算法
哈希摘要算法
和MD5算法类似,SHA(secure hash algorithm)也是一种生成信息摘要的算法。
SHA-1,SHA-2,SHA-256,第一位数字大版本号,第二位数字是子版本号。
SHA-1摘要长度160bit;而MD5的摘要长度是128bit,但MD5生成摘要的性能比SHA-1好。
SHA-256:可以生成长度256bit的信息摘要。
AES算法,advanced encryption standard
对称加密算法
- 摘要算法是不可逆的,它的主要作用是对信息一致性和完整性的校验
- 对称加密算法是可逆的,它的主要作用是保证私密信息不被泄露
AES128, AES192, AES256,指的是AES算法对不同长度密钥的使用。特点,
- 明文分组,AES并不是将整个明文全部加密成一整段密文,而是将明文拆成一个个独立的明文块,每一个明文块长度128bit,逐一加密后的密文块最后拼接在一起,成为AES加密结果
- 填充方式,如果最后一块明文块不够,需要将其填充为128/192/256bit
- Nopadding,不做任何填充,但是要求明文必须是16字节的整数倍
- PKCS5Padding(默认)
- ISO10126Padding
- 工作模式,表现在把明文块加密成密文块的处理过程中
- CBC模式
- ECB模式(默认)
- CTR模式
- CFB模式
- OFB模式


其中,
- kgen.init(128, new...),第一个参数决定了分组长度是128bit
- Cipher.getInstance("AES/CBC/NoPadding"),决定了填充方式是NoPadding,工作模式是CBC
AES加密不是一次就将明文变成密文的,而是先后经过很多轮加密,1+N+1轮,
- 初始轮 Initial round,1次
- 普通轮 rounds,N次
- 最终轮 final round,1次
AES的分组长度对应的轮数如下,
- AES128,10轮,N=8
- AES192,12轮
- AES256,14轮
不同截断的round有不同的处理步骤,
初始轮,
- 加轮密钥 addRoundKey
普通轮,
- 字节代替 subBytes,就是把明文块的每一个字节都替代成另外一个字节
- 行移位 shiftRows,每行左移X个字节
- 列混淆 mixColumns,明文块矩阵与修补矩阵相乘
- 加轮密钥,这是唯一用到密钥的一步,明文块与密钥异或
最终轮,
- 字节代替
- 行移位
- 加轮密钥
解密过程与加密过程相反:最终轮 -> 普通轮 -> 初始轮
工作模式,ECB明文块之间没有联系,完全并行;CBC模式,某一个明文块需要上一个明文块作“加盐”处理,内部IV变量为初始盐


红黑树
根节点的树深度(树高度)=1
二叉查找树(binary search tree)特征,
- 左子树上所有结点的值均小于或等于它的根结点的值
- 右子树上所有结点的值均大于或等于它的根结点的值
- 左、右子树也分别为二叉排序树


红黑树(red black tree)是BST的自平衡优化,改善了BST的树高落差,除了符合BST的基本特性外,它还要符合以下特征,
- 节点是红色或者黑色
- 根节点一定是黑色
- 每个叶子节点都是黑色的空节点
- 每个红色节点的两个子节点都是黑色的(即每个叶子到根的所有路径上不能有两个连续的红色节点)
- 对于任一节点而言,其到叶节点的每一条路径都包含相同数目的黑结点
由于有了上面的3+5点规则,才保证了红黑树的自平衡。红黑树从根节点到叶子节点的最长路径不会超过最短路径的2倍。当插入或者删除节点的时候,红黑树的规则很有可能被打破。这时候就需要作出一些调整,来继续维持3+5规则,这些调整主要包括变色和旋转,
- 变色,红黑互换
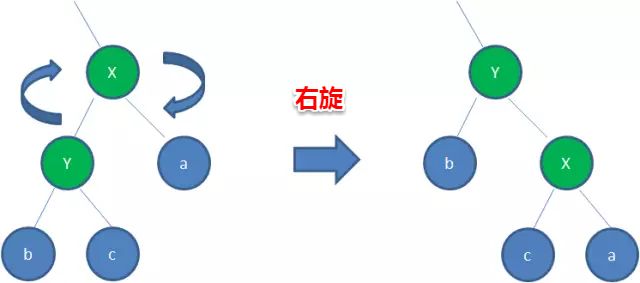
- 左旋,要符合BST的规则,就很容易理解b这个节点该放在哪个位置,因为Y要上来,但是x < b < y,所以b要在x的右节点,x又要在y的左节点。
- 右旋,y < c < x



HashMap
HashMap是一个用于存储Key-Value pair 键值对的集合,每一个键值对pairs也叫Entry。这个Entry分散存储在一个数组当中,这个数组就是HashMap的主干。

index = Hash("apple") = 2

如果下一个index = Hash("banana") = 2,那么就发生碰撞,可以用链表来解决,链表头节点始终是最晚进入的Entry。

put(k, v), 存储某个(key, value)时,调用Entry(k, v)的hashcode计算hash从而得到index,然后将Entry放入其中。
get(key), 查找某个key的value,步骤如下,
- key hash得到index,array(index)来O(1)定位到链表
- 线性查找链表,比较Entry(key, value),keyInLink.equals(search_key)?,如果equal返回该Entry(search_key, value)的value,否则为null。碰撞链表查找性能O(N),若为树就O(logN)
- 在Java 8中,如果一个bucket中碰撞冲突的元素超过某个限制(默认是8),则使用红黑树来替换链表,从而提高速度
为什么hashMap的默认初始长度是16,并且每次自动扩展或是手动初始化时,长度必须是2的幂?
选择2的幂,是为了服务于从key映射到index的hash算法。要求一个尽量均匀的hash函数,减少key的index碰撞。
index = HashCode(Key) & (hashMap_Length - 1)

看到hashMap_Length为2的幂,那么其低位全为1,就可以都将hashCode对应的低位信息都保留,从而增加index distinct count。这是后碰撞机率就完全依赖于HashCode自身的分布均匀性了。

cocurrentHashmap
在jdk8之前,concurrentHashmap使用了分段锁segment来实现并发。
concurrentHashmap当中每个segment各自持有一把锁,在保证线程安全的同时降低了锁的粒度,让并发操作效果更高。
读写过程,
Get方法,
- 为输入的key做hash运算,得到hash值
- 通过hash值,定位到对应的segment对象
- 再次通过hash值,定位到segment当中数组的具体位置
Put方法,
- 为输入的key做hash运算,得到hash值
- 通过hash值,定位到对应的segment对象
- 获取可重入锁
- 再次通过hash值,定位到segment当中数组的具体位置
- 插入或覆盖hashEntry对象
- 释放锁
在读写时都需要二次定位。首先定位到segment,之后定位到segment内的具体数组下标。
返回concurrentHashmap的总元素数量的size()函数,大体逻辑,
- 遍历所有segment
- 把segment的元素数量累加起来,S1
- 把segment的修改次数累加起来,S2
- 判断所有segment的总修改次数是否大于上一次的总修改次数
- 如果大于,说明统计过程中有修改,重新统计,尝试次数+1
- 如果没有修改,统计结束
- 如果尝试次数超过阈值(=2),则对每一个segment加锁,再重新统计
- 再次判断所有segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等
- 释放锁,统计结束
这里引入尝试次数,这种思想和乐观锁悲观锁的思想如出一辙。为了尽量不要锁住所有segment,首次乐观地假设求size过程中不会有修改。当尝试了一定次数之后,才无奈转为悲观锁,锁住所有segment来保证强一致性。
在jdk8之后,废弃了segment改变,改为由CAS原理来实现,直接使用一个大数组,在发生碰撞的时候,产生链表,如果链表长度超过了阈值(=8),则将链表转换为红黑树(寻址时间复杂度有O(N)降到O(logN)了,原作者认为引入红黑树之后,即使hash冲突比较严重,寻址效率也足够高)。
单例
- 双重锁检测
public class Singleton {
private volatile static Singleton instance = null; //单例对象
private Singleton() { //构造函数,私有
}
public static Singleton getInstance() {
if (instance == null) { //双重检测机制
synchronized (Singleton.class) { //同步锁,要类级别的,不能是对象锁
if (instance == null) { //双重检测机制
instance = new Singleton();
}
}
}
return instance;
}
}
- 静态内部类
public class Singleton {
private Singleton() {
}
public static Singleton getInstance() {
return LazyHolder.instance;
}
private static class LazyHolder {
private static final Singleton instance = new Singleton();
}
}
- 枚举
public enum Singleton {
INSTANCE;
}
- scala object
object Singleton {
private val instance = “I am singleton"
def getInstance() = {
instance
}
}
volatile关键字
volatile如字面意思,不稳定的,变化无常的,所以需要被时刻关注着。
其大概作用,
- 保证一个变量在线程之间的可见性,表现为即时更新变量值到主内存。基于CPU的内存屏障指令是可见性的保证,happen-before原则
- 阻止编译时和运行时的指令重排。编译时依靠内存屏障来阻止JVM编译器对指令的重排;运行时依靠CPU屏障指令来阻止重排
- 64位long/double安全读取,因为 Java 中读取 long 类型变量不是原子的


- threadlocal,一个关于创建线程局部变量的类
- Atomic原子类
- ConcurrentHashMap,锁,jdk7基于segment,jdk8基于CAS
Netty
远程过程调用,
- http协议(简单明了,但是很多头信息)
- socket(偏底层,要注意高并发)
-
阻塞IO,blocking io,一个线程对应一个socket
 BIO
BIO -
非阻塞IO,non-blocking io,多路复用的思路,一个线程/选择器selector去处理多个socket
 NIO
NIO
-
Netty本身是一个基于java NIO的网络框架,封装了java NIO的复杂底层细节,提供简单易用的抽象概念来编程。
Netty是一个半成品,不能开箱即用,必须在其基础之上做点定制,利用它开发出自己的应用程序,然后才能运行(类似spring那样)。grpc,dubbo这些rpc框架的底层用的就是Netty
微服务架构
单体架构优点,
- 便于管理,所有代码都在一个项目当中
但是当其产品规模越来越大时,缺点就更为突出,
- 项目过于臃肿,当大大小小的功能模块都集中在同一项目的时候,整个项目必然会变得臃肿,让开发者难以维护
- 资源无法隔离,整个单体系统的各个功能模块都依赖于同样的数据库、内存、IO等资源,一旦某个功能模块对资源使用不当,整个系统的其他功能都会被拖垮
- 无法灵活扩展,当系统的访问量越来越大的时候,单体系统固然可以进行水平扩展(多个实例),部署在多台机器上组成集群。但是这种扩展并非灵活的扩展。比如我们现在的性能瓶颈是支付模块,希望只针对支付模块做水平扩展,这一点在单体系统是做不到的(因为部署是整个项目的部署,而整个项目不仅仅包含支付模块)


微服务架构是为了解决上述臃肿单项目问题,将单项目拆开成多个独立的服务,然后各自调用,特点如下,
- 可灵活扩展,比如根据每个服务的吞吐量不同,支付服务需要部署20台机器,用户服务需要部署30台机器,而商品服务只需要部署10台机器。这种灵活部署只有微服务架构才能实现

- 资源的有效隔离,每一个微服务拥有独立的数据源,假如微服务A想要读写微服务B的数据库,只能调用微服务B对外暴露的接口来完成。这样有效避免了服务之间争用数据库和缓存资源所带来的问题

- 团队组织架构的调整


- 拆分出很多业务模块,增加了开发和测试复杂度
- 难以保证不同服务之间的数据一致性,所引入的分布式事务和异步补偿机制可以缓解一致性问题,但也增加了设计和开发难度
总而言之,微服务架构的核心思想是,一个应用是由多个小的、相互独立的、微服务组成,这些服务运行在自己的进程中,开发和发布都没有依赖。不同服务通过一些轻量级交互机制来通信,例如 RPC、HTTP 等,服务可独立扩展伸缩,每个服务定义了明确的边界,不同的服务甚至可以采用不同的编程语言来实现,由独立的团队来维护。
SOA vs 微服务
- SOA,粗粒度,系统之间的服务调用。合,把很多系统串联在一起
- 微服务,细粒度,按业务拆分成不同的服务。拆,把很多功能模块拆分出来提供服务
ThreadPoolExecutor

//构造函数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
| parameter | CHN | meaning |
|---|---|---|
| corePoolSize | 核心线程数 | 核心线程是lazy constructor,会一直存在于线程池中(即使这个线程一直空闲),有任务要执行时,如果核心线程没有被占用,会优先用核心线程执行任务。数量一般情况下设置为CPU核数的2倍 |
| maximumPoolSize | 最大线程数 = 核心线程数 + 非核心线程数 | 核心线程都被占用了,但上游任务持续压过来,若等待队列满了,则需要再创建线程来处理 |
| keepAliveTime | 非核心线程闲置超时时长 | 当一个线程空闲了,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到corePoolSize的大小 |
| TimeUnit | keepAliveTime的单位 | MILLISECONDS, MINUTES, HOURS等 |
| BlockingQueue | 线程池中的任务队列 | * SynchronousQueue直接提交 * LinkedBlockingQueue无界队列 * ArrayBlockingQueue有界队列 * DelayQueue延时队列 |
| ThreadFactory | 创建线程的工厂 | 可以用线程工厂给每个创建出来的线程设置名字。一般情况下无须设置该参数,默认pool-poolNumber-thread-threadNumber |
| RejectedExecutionHandler | 饱和策略 | * AbortPolicy不处理且抛异常 * CallerRunsPolicy由调用者(调用线程池的主线程)执行 * DiscardOldestPolicy抛弃等待队列中最老的 * DiscardPolicy抛弃当前任务 |
工作规则
- 如果curPoolSize < corePoolSize,则创建新线程执行任务
- 如果curPoolSize > corePoolSize,且等待队列未满,则进入等待队列
- 如果curPoolSize > corePoolSize,且等待队列已满,且小于maximumPoolSize,则创建新线程执行任务
- 如果curPoolSize > corePoolSize,且等待队列已满,且大于maximumPoolSize,则调用饱和策略来处理该任务
- 线程池里的每个线程执行完任务后不会立刻退出,而是会去检查下等待队列里是否还有线程任务需要执行,如果在keepAliveTime里等不到新的任务了,那么线程就会退出,直至baseline = corePoolSize条
线程池具体实现
- FixedThreadPool
//可重用固定线程数的线程池,超出的线程会在队列中等待
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
//其corePoolSize == maximumPoolSize,即不设置非核心线程
//keepAliveTime为0L表示多余的线程会立刻终止
- CachedThreadPool
//无穷大的线程池
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
//corePoolSize是0,maximumPoolSize是Int的最大值,也就是说CachedThreadPool没有核心线程,全部都是非核心线程,并且没有上限
//keepAliveTime是60秒,就是说空闲线程等待新任务60秒,超时则销毁
- SingleThreadExecutor
//单个线程工作的线程池
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
//按入队顺序逐一进行任务
- ScheduledThreadPool
//定时或者周期性运行任务的线程池
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE,
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
new DelayedWorkQueue());
}
//等待队列DelayedWorkQueue是无界的,所以maximumPoolSize参数无效