与传统语言相比,Forth的编译器过于简单。
传统的编译器通常设计成大型的程序,用来将可预见的合法的语法组织转换为机器语言。
然而Forth的编译器仅仅使用一个包含几行的定义实现。高级的语法结构如条件语句和循环语句则由定义的高级words再次定义实现的
抛开对Forth过于简单的看法。你会发现Forth在扩展编译器方面的独特功能。通过定义新的word,Forth非常容易对底层的编译器进行扩展。
这种通过扩展编译器的方式,可以实现具有强大的语言功能
1 区分编译时与运行时
在深入理解Forth的编译器时,我们需要认真区分Forth中的编译时与运行时
通常在Forth编程中,一个word的运行过程(executed)称为运行时(run time)。一个Forth的定义过程(compiled)称为编译时(compile time)。然而Forth中有些特定的word既包含运行时(run-time)也包含编译时(compile-time)行为
Forth中两类特定word具有编译和运行时行为,下面的讨论过程中,我们将这类word看做定义word(defining words)和编译word(compiling words)
一个定义word(defining word)在运行时(executed)用来编译生成一个新的定义。每个定义word(defining word)说明了它所定义一类的word所具有的运行时(run-time)和编译时(compile-time)行为。
其中一个定义word(definiting word)是常量定义wordCONSTANT。
在Forth终端中输入80 CONSTANT MARGIN,就会进入CONSTANT的编译时(compile-time)行为,
CONSTANT的编译时行为将在字典(dictionary)建立一个常量类型的入口,并命名为MARGIN。然后将80存储到该常量的参数字段,
在Forth终端输入MARGIN,就会进入CONSTANT的运行时(run-time)行为,
CONSTANT的运行时行为会将MARGIN对应的常量值存储到数字栈(stack)中。
另一类具有双重行为的word我们称为编译word(compiling word)。编译word通常用来分号定义中,并且在这个过程的定义中实现某些特定功能
其中一种编译word是."。这个编译word在定义的编译(compile-time)过程中将会将一段文本字符串的长度与其内容写入到该定义word的入口。在运行(run-time)过程中将会打印输出这段文本内容。
其他的编译word如IF和LOOP页同时包含不同的运行时和编译时行为。
2 定义word(defining word)的实现
目前为止我们接触到的定义word(defining word)如下
VARIABLE ; 变量定义
2VARIABLE ; 变量定义
CONSTANT ; 常量定义
2CONSTANT ; 常量定义
: ; 过程定义
CREATE ; 内存分配定义
这些定义word都是用来定义具有相似的编译时和运行时行为的类words
这些定义word通常为他们所定义一类word实现了特定的编译时(compile-time)和运行时(run-time)行为
其中CREATE是这类定义word(defining words)中基础的定义word。
在编译时(compile-time),CREATE会从输入流(inpute stream)通过空格截取一个名称(EXAMPLE),然后在字典中创建一个变量区域使用这个名称作为开头。
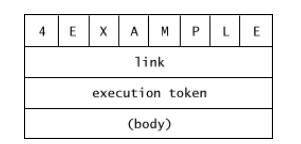
在运行时(run-time),CREATE会将这个名称(EXAMPLE)对应的字典的body的地址存储到数字栈(stack)上。
基于CREATE 可以实现定义wordVARIABLE。
: VARIABLE CREATE 0 , ;
因此输入VARIABLE ORANGES时
VARIABLE会执行CREATE 以ORANGES为名称在字典中创建变量入口。然后将变量的body地址存储到数字栈(stack)
然后0 , 中的,会将0存储到变量的body中。
由于VARIABLE定义的变量由CREATE实现,因此ORANGES具有与CREATE定义的word相同的运行时(run-time)行为,VARIABLE调用时将会将地址存放到数字栈(stack)上。
通常在定义word(deining word)中我们使用DOES>区别word的运行时(run-time)行为
: DEFINING_WORD
CREATE (compile-time operations)
DOES> (run-time operations)
为了证实这点,我们可以将CONSTANT定义word实现为如下结构
: CONSTANT
CREATE , (CREATE 创建一个字典入口,存储数字栈的值到常量参数字段)
DOES> @; (DOES 将word的body地址存储到stack中,然后调用@,获取数字栈上地址的内容)
那么在Forth中输入76 CONSTANT TROMEBONES
将会实现如上定义过程
而DOES>前缀修改模式,其后的内容定义这个模式的操作内容
DOES> 用在创建定义word(defining word)标记编译时行为结束和运行时行为开始。运行时行为常常是Forth中高层的操作。这个body地址将会存储到stack中
3 定义word实现实例
接下来举例说明定义word的实现
在字符串输入中,我们需要将输入内容的长度和输入内存存储到变量中。
我们可以定义相应的word简化这种操作
这里我们定义wordCHARACTERS
如果我们输入20 CHARACTERS ME
那么我们将创建一个名为ME的可以用来存储20个字符的字符串数组
如果我们再次输入ME,我们可以获取这个字符串数组的地址和字符串中字符的长度存储到数字栈(stack)在。
CHARACTER的实现如下
: CHARCTERS
CREATE (定义时创建字典ME入口)
DUP , ALLOT (首先(DUP ,)复制20将其存储到body首个位置,然后(ALLOT)申请20个用来存储字符的内存)
DOES> (运行时获取body地址到stack)
DUP (复制数字栈上的body地址)
CELL+ (移动到字符串长度下一个内存地址,也就是字符串内容首地址到数字栈,)
SWAP (然后交换字符串地址栈与长度地址,)
@ (获取字符串长度到数字栈顶部)
; (运行完后数字栈的内容为 (addr count --))
这里我们扩展编译器实现了一个CHARACTERS定义word。这个定义word将会创建特定的数据结构。不仅仅可以简化我们的输入输出,还可以在需要的时候用来修改字符串的长度,
接下来我们实现一个有用的字符串数组定义wordSTRING
: STRING CREATE ALLOT DOES> + ;
输入30 STRING VALUE
将会创建一个名为VALUE的30个字节长的数组。
当我们输入6 VALUE C@我们可以访问特定位置的内容
我们还可以实现其他的数字数组。比如初始化为0的数字数组,
: ERASED HERE OVER ERASAE ALLOT ;
: 0STRING CREATE ERASAED DOES> + ;
首先定义ERASED
然后在0STRING中调用这个定义word
可以通过修改定义word,实现修改其他由这个word实现的功能。
另外我们可以实现将内存中的字符串存储到硬盘中,只需要重新修改STRING的运行时行为(run-time)。这个新的STRING将会通过计算机硬盘中需要包含记录的长度 然后将去读取到输入缓存中,最后然后这个输入缓存中的地址
可以使用定义 word创建任何类型的数据结构,有时候需要创建多维数组,下面给出创建二维数组的定义
: ARRAY (#row #cols --)
CREATE DUP , * ALLOT
DOES (member : row col -- addr)
ROW OVER@ * + + CELL+ ;
如果输入4 4 ARRAY BOARD 将会创建4x4的数组
为了获取数组的内容 输入2 1 BOARD C@ 将会获取2行1列内容
其中运行时(run-time)行为如下
Operation Contents of stack
... row col pfa
ROT col pfa row
OVER @ col pfa row #cols
* col pfa row-index
++ address
CELL+ corrected address
最后一个例子是一个可视化定义wordShapes
DECIMAL
: star [CHAR] * EMIT ;
: .row CR8 0 DO
DUP 128 AND IF star
ELSE SPACE
THEN
1 LSHIFT
LOOP DROP;
: SHAPE CREATE 8 0 DO C, LOOP
DOES> DUP 7 + DO I C@ .row -1 +LOOP CR;
4 分号编译器的机制
上面的定义word(defining word)通常用来实现特定的数据结构的保存与获取,下面的编译word(compiling word)通常用在分号定义的编译器。
最具有代表性的编译word是实现逻辑控制的word,如IF THEN DO LOOP等。因为这些word对于Forth系统很重要,因此我们一般不会修改这些word。为了理解这些编译word,我们会在运行过程检测这些words的实现机制,然后实现各种编译word(compiling-word)
正如在介绍:时所说的,进入:后搜索各个word的定义地址,然后编译各个word的定义地址到相应的word的入口。
然后在分号编译过程中并不会将编译word的地址存储到定义字典中,而是运行这种编译word
那么分号编译过程中如何区分这两种word? 可以通过检查word定义的优先级precedence bit实现。如果这个优先级位是off。那么这个word的地址将会存储到定义字典中,如果这个优先级位是on,那么可以理解执行这个word。这种立即执行的word称为立即word(immediate)。
也就是说: ;等word是立即word
可以使用关键词IMMEDIATE创建一个立即word。
: name definition ; IMMEDIATE(设置 precedence bit 为on)
那么,这个word将会在定义过程被运行
下面是个例子
: SAY-HELLO ." Hello" ; IMMEDIATE
我们可以简单的运行这个word,正如普通word
SAY-HELLO return-key 输出Hello ok
然而神奇的时,如果我们将这个word存放到另一个定义中,如
: GREET SAY-HELLO ." I Speak forth " ;时
SAY-HELLO的地址将不会存储到GREET的定义中,而是直接输出
Hello ok.
这个可以通过输入GREET的输出I Speak forth得证。
由此可知立即word不会被存储到定义word的字典中
这里需要说说Forth使用者对于这种行为的习惯称呼。
在上述的GREET例子中,我们认为SAY-HEELO有一个编译时行为而没有运行时行为,然而对于单独的SAY-HELLO却包含着运行时行为。
通常我们将GREET称为SAY-HELLO的编译者,立即word,SAY-HEELO对于它的编译者GREET没有运行时行为
另一个立即word的例子是BEGIN
: BEGIN HERE ; IMMEDIATE。由此可知BEGIN在编译时将HERE的地址存储到数字栈stack。然后在随后的UNTIL或者REPEAT的立即word将会得到重复时需要返回的地址,也就是BEGIN存储到数字栈的地址。
BEGIN并不会存储任何内容到对应的word。只是简单的将HERE存储到stack中供REPEAT使用。
然后大多数编译word包含一个运行时行为,对于这类编译word,通常需要将其运行行为入口地址存储到编译word中。
一个具有代表性的例子是DO。
与BEGIN相同的是DO在编译时需要提供HERE供LOOP或者+LOOP使用来返回到重复运行的地址。
不过与BEGIN不同的是DO也包含一个运行时行为,会将limit和index存储到return stack中
DO的运行时行为使用Forth在低级word定义,
: DO POSTONE 2>R HERE ; IMMEDIATE
其中的POSTONE会查找接下来的定义中的word(2>R)。然后将其存储到编译定义中。因此在运行时2>R将会被运行。也就是用来存储limit和index到return stack中。
可以将POSTONE看做IMMEDIATE的临时取消动作,
另一个例子是;。在编译过程中,分号的操作内容如下
; POSTPONE EXIT REVEAL POSTONE [ ; IMMEDIATE
首先将EXIT的地址存储到;中,作为运行时的行为,
然后使用REVEAL将当前编译的;暴漏出来可以被用于其后的定义中
REVEAL会将正在被编译生成的word可以在编译过程中搜索到。
POSTPONE会将立即word强制编译到word中而不是运行它
其运行机制是解析其后的输入字符流中的word,判断是否是立即word然后执行不同的行为。如果这个word不是立即word。将会将这个word的地址编译存储到定义字典中,如果这个word是立即word,那么会强制将立即word的地址编译到当前定义字典中。然而在退出的定义中,一个立即word会被运行。
下面是IMMEDIATE和POSTPONE的机制
IMMEDIATE 标注定义的word为立即word
POSTPONE 在编译word中,直接编译接下来的word地址到定义中,
5 更多的编译控制words
还有两个需要了解的编译控制word。[ ]可以用在分号定义中停止编译和重新开启编译。在它们之间包含的word将会被看做立即word运行
: SAY-HELLO ." Hello " ;
: GREET [ SAY-HELLO ] ." I speak forth " ; (输出 Hello ok)
GREET 输出(I speak Forth ok)
SAY-HELLO并不是一个立即word,但是[]可以修改其编译控制,当做立即word运行
这种机制的代表例子是word LITERAL
数字在分号定义中会被看做字面量(literal),比如数字4
: FOUR-MORE 4 + ;会将数字4看做字面量
字面量在过程定义(:)中需要两个cells保存,如下
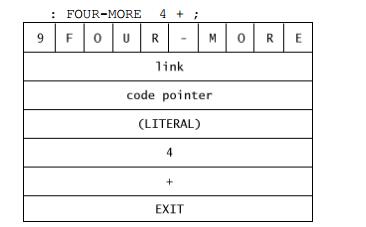
首先保存LITERAL的word将会在运行将数字4存储到数字栈stack中
可以将这种行为成为字面量运行时代码。或者简单看做字面量行为
因此过程定义: 首先会将字面量行为word存储,然后存储数字本身
LITERAL会将字面量代码和数字本身存储到定义中
: FOUR-MORE [ 4 ] LITERAL + ;
首先会将数字4当做立即word运行,存储到数字栈(stack)。然后保存运行时代码与数字4到定义中.会得到与上面相同的FOUR-MORE的定义
另一个LITERAL的使用如下
VARIABLE LIMITS 4 CELLS ALLOT
可以创建一个LIMIT
: LIMIT (index -- addr) CELLS LIMITIS + ;
HERE 5 CELLS ALLOT BASAE !
首先我们将HERE的地址存储到BASE中。然后定义如下的LIMIT
: LIMIT (index -- addr) CELLS [BASE @] LITERAL +;
可以将这个地址作为字面量存储到LIMIT中,然后恢复BASE
DECIMAL
目前我们已经清楚了LITERAL。我们给出一个关于[,]更好的例子
假设在过程定义:中,我们需要打印数组 我们上面定义的BOARD的row 2 column 3。为了获取这个字节的地址,我们可以使用下面的句子
BOARD 2 8 (#cols) * 3 + CELL+ +
为了将这种语句特例化
可以改写为BOARD [2 8 ( #cols) * 3 + CELL+] LITERAL +
下面是一个例子可以用在应用中,这些定义可以让我们一探word的内部实现机制
`: DUMP-THIS [HERE] LITERAL 32 DUMP . " DUMP-THIS"
运行DUMP-THIS时,将会打印存储到DUMP-THIS中的地址。
而LITERAL的定义如下
: LITERAL POSTPONE (LITERAL) , ; IMMEDIATE
首先编译运行时代码地址到运行过程,然后编译字面值
6 最终的解释
接下来会给出文本解释和分号编译的概括性解释
Forth系统中的INTERPRET的定义如下
: INTERPRET (--)
BEGIN
BL FIND
IF EXECUTE ?STACK ABORT" Stack empty"
ELSE NUMBER
THEN
AGAIN;
在一个循环中,试着在输入字符流中根据BL切分word,
在字典中查找word,如果定义了就运行这个word,然后检查是否栈移除。如果查找word失败,然后将其看做数字,存储到数字栈stack中
当这个word解析完后重新返回解析下个word
解释器就是一个如此简单而强力的结构,编译器:的定义如下
: ]
BEGIN
BL FIND DUP
IF -1 = IF EXECUTE ?STACK ABORT" Stack empty"
ELSE ,
THEN
ELSE DROP (NUMBER) POSTPONE LITERAL
THEN
这里将编译器定义为]。而:调用]
在一个循环中,试着在输入字符流中根据BL切分word,
然后在字典中查找,如果这个word定义而且是立即word就立即运行,
如果不是立即word,则将FIND查找到的地址保存到定义中
如果使用数字的则将数字看做字面量存储
然后重复这个循环。
与解释器相比,编译器]可以看做一个具有运行或者编译的word的解释器扩展。这正是编译器可以简单扩展的原因
因此有两种方式可以用来扩展Forth的编译器,总结如下
1 通过创建新的定义word(defining words),来扩展数据编译器
2 通过创建新的编译word(compiling words),来扩展过程编译器