原文地址
快速排序
原理
快速排序是C.R.A.Hoare提出的一种交换排序。它采用分治的策略,所以也称其为分治排序。
实现快速排序算法的关键在于,先在数组中选一个数作为基数,接着以基数为中心将数组中的数字分为两部分,比基数小的放在数组的左边,比基数大的放到数组的右边。接下来我们可以用递归的思想分别对基数的左右两边进行排序。
整个快速排序可以总结为以下三步:
- 从数组中取出一个数作为基数
- 分区,将数组分为两部分,比基数小的放在数组的左边,比基数大的放到数组的右边。
- 递归使左右区间重复第二步,直至各个区间只有一个数。
样例分析
下面我用博客专家MoreWindows的挖坑填数+分治思想来分析一个实例(使用快速排序将以下数组排序)

首先,取数组中的第一个数字52为第一次分区的基数

初始时,start=0、end=8、base=52(start区间的头、end区间的尾、base基数)
由于将array[0]中的数据赋给了基数base,我们可以理解为在array[0]处挖了一个坑,当然这个坑是可以用其它数据来填充的。
接着我们从end开始 向前找比base小或者等于base的数据,很快我们就找了19,我们就19这个数据填充到array[0]位置,这样array[8]位置就又形成了一个新的坑。不怕,我们接着找符合条件的数据来填充这个新坑。
start=0、end=8、base=52

然后我们再从start开始向后找大于或等于base的数据,找到了88,我们用88来填充array[1],这样array[1]位置也形成了一个新坑。 Don't Worry 我们接着从end开始 向前找符合条件的数据来填充这个坑。
start=1、end=8、base=52

{% note success %} 需要注意的是start和end随着查找的过程是不断变化的。 {% endnote %}
之后一直重复上面的步骤,先从前向后找,再从后向前找。直至所有小于基数的数据都出现在左边,大于基数的数据都出现在右边。

最后将base中的数据填充到数组中即可完成这次分区的过程。

然后递归使左右区间重复分区过程,直至各个区间只有一个数,即可完成整个排序过程。
{% note primary %}
快速排序的核心是以基数为中心,将数组分为两个区间,小于基数的放到基数的左边,大于基数的放到基数的右边。
在第一次分区的时候我们以数组中的第一个数据为基数,在array[0]处挖了一个坑,这时我们只能从区间的后面往前找小于基数的数据来填充array[0]这个坑,如果直接从前往后找符合条件的数据,就会造成大于基数的数据留在了数组的左边。
所以我们只能通过从后往前找小于基数的数据来填充前面的坑,从前往后找大于基数的数据来填充后面的坑。这样可以保证在只遍历一遍数组就能将数组分为两个区间
最后一步我们用基数本身来填充数组的最后一个坑
{% endnote %}
代码实现:
// 分区
public static int partition(int[] array, int start, int end) {
int base = array[start];
while (start < end) {
while (start < end && array[end] >= base)
end --;
array[start] = array[end];
while (start < end && array[start] <= base)
start ++;
array[end] = array[start];
}
array[end] = base;
return start;
}
// 快速排序
public static void quickSort(int[] array,int start, int end) {
if(start < end) {
int index = partition(array, start, end);
quickSort(array, start, index-1);
quickSort(array, index+1, end);
}
}
class QuickSort {
public:
//快速排序
int* quickSort(int* A, int n) {
QSort(A,0,n-1);
return A;
}
//对数组A[low,...,high]
void QSort(int *A,int low,int high) {
if(low=key)
high--;
A[low]=A[high];
while(low 算法分析:
当数据有序时,以第一个关键字为基准分为两个子序列,前一个子序列为空,此时执行效率最差。时间复杂度为O(n^2)
而当数据随机分布时,以第一个关键字为基准分为两个子序列,两个子序列的元素个数接近相等,此时执行效率最好。时间复杂度为O(nlogn)
所以,数据越随机分布时,快速排序性能越好;数据越接近有序,快速排序性能越差。
快速排序在每次“挖坑”的过程中,需要 1 个空间存储基数。而快速排序的大概需要 NlogN次的处理,所以占用空间也是 NlogN 个。
下面我们在来看几种改进的快排算法
快速排序中元素切分的方式
快速排序中最重要的步骤就是将小于等于中轴元素的整数放到中轴元素的左边,将大于中轴元素的数据放到中轴元素的右边,这里我们把该步骤定义为'切分'。以首元素作为中轴元素,下面介绍几种常见的'切分方式'。
两端扫描,一端挖坑,另一端填补
这种方法就是我们上面用到的'挖坑填数',在这再做个简单的总结。
这种方法的基本思想是:使用两个变量i和j,i指向最左边的元素,j指向最右边的元素,我们将首元素作为中轴,将首元素复制到变量pivot中,这时我们可以将首元素i所在的位置看成一个坑,我们从j的位置从右向左扫描,找一个小于等于中轴的元素A[j],来填补A[i]这个坑,填补完成后,拿去填坑的元素所在的位置j又可以看做一个坑,这时我们在以i的位置从前往后找一个大于中轴的元素来填补A[j]这个新的坑,如此往复,直到i和j相遇(i == j,此时i和j指向同一个坑)。最后我们将中轴元素放到这个坑中。最后对左半数组和右半数组重复上述操作。
这种方法的代码实现请参考上面的完整代码。
从两端扫描交换
这种方法的基本思想是:使用两个变量i和j,i指向首元素的元素下一个元素(最左边的首元素为中轴元素),j指向最后一个元素,我们从前往后找,直到找到一个比中轴元素大的,然后从后往前找,直到找到一个比中轴元素小的,然后交换这两个元素,直到这两个变量交错(i > j)(注意不是相遇 i == j,因为相遇的元素还未和中轴元素比较)。最后对左半数组和右半数组重复上述操作。
public static void QuickSort1(int[] A, int L, int R){
if(L < R){//递归的边界条件,当 L == R时数组的元素个数为1个
int pivot = A[L];//最左边的元素作为中轴,L表示left, R表示right
int i = L+1, j = R;
//当i == j时,i和j同时指向的元素还没有与中轴元素判断,
//小于等于中轴元素,i++,大于中轴元素j--,
//当循环结束时,一定有i = j+1, 且i指向的元素大于中轴,j指向的元素小于等于中轴
while(i <= j){
while(i <= j && A[i] <= pivot){
i++;
}
while(i <= j && A[j] > pivot){
j--;
}
//当 i > j 时整个切分过程就应该停止了,不能进行交换操作
//这个可以改成 i < j, 这里 i 永远不会等于j, 因为有上述两个循环的作用
if(i <= j){
Swap(A, i, j);
i++;
j--;
}
}
//当循环结束时,j指向的元素是最后一个(从左边算起)小于等于中轴的元素
Swap(A, L, j);//将中轴元素和j所指的元素互换
QuickSort1(A, L, j-1);//递归左半部分
QuickSort1(A, j+1, R);//递归右半部分
}
}
从一端扫描
和前面两种方法一样,我们选取最左边的元素作为中轴元素,A[1,i]表示小于等于pivot的部分,i指向中轴元素(i < 1),表示小于等于pivot的元素个数为0,j以后的都是未知元素(即不知道比pivot大,还是比中轴元素小),j初始化指向第一个未知元素。

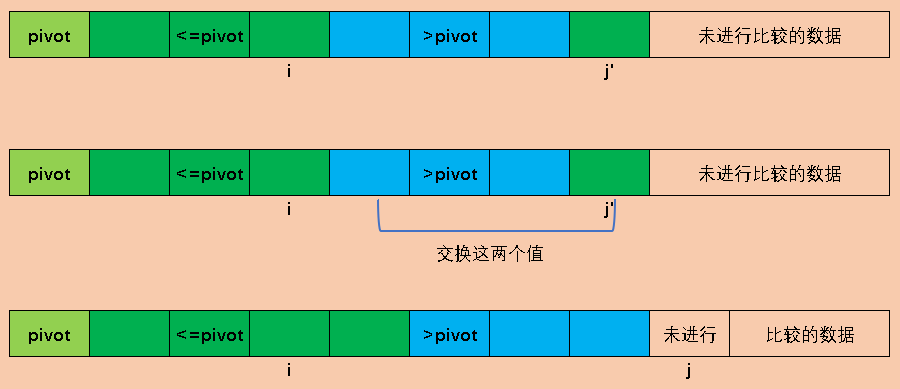
当A[j]大于pivot时,j继续向前,此时大于pivot的部分就增加一个元素
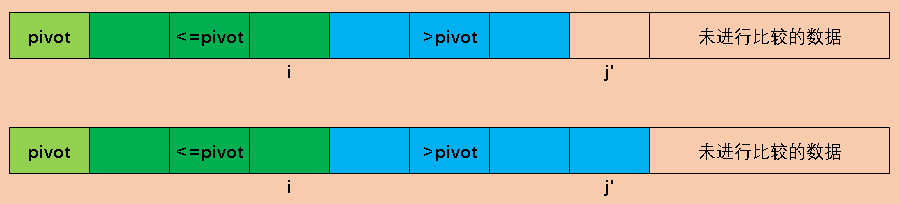
当A[j]小于等于pivot时,我们注意i的位置,i的下一个就是大于pivot的元素,我们将i增加1然后交换A[i]和A[j],交换后小于等于pivot的部分增加1,j增加1,继续扫描下一个。而i的下一个元素仍然大于pivot,又回到了先前的状态。
public static void QuickSort3(int[] A, int L, int R){
if(L < R){
int pivot = A[L];//最左边的元素作为中轴元素
//初始化时小于等于pivot的部分,元素个数为0
//大于pivot的部分,元素个数也为0
int i = L, j = L+1;
while(j <= R){
if(A[j] <= pivot){
i++;
Swap(A, i, j);
j++;//j继续向前,扫描下一个
}else{
j++;//大于pivot的元素增加一个
}
}
//A[i]及A[i]以前的都小于等于pivot
//循环结束后A[i+1]及它以后的都大于pivot
//所以交换A[L]和A[i],这样我们就将中轴元素放到了适当的位置
Swap(A, L, i);
QuickSort3(A, L, i-1);
QuickSort3(A, i+1, R);
}
}
快速排序的改进方法
三向切分的快速排序
三向切分快速排序的基本思想,用i,j,k三个将数组切分成四部分,a[0, i-1]表示小于pivot的部分,a[i, k-1]表示等于pivot的部分,a[j+1]之后的表示大于pivot的部分,而a[k, j]表示未进行比较的元素(即不知道比pivot大,还是比pivot元素小)。我们要注意a[i]始终位于等于pivot部分的第一个元素,a[i]的左边是小于pivot的部分。

我们依旧选取最左边的元素作为中轴元素,初始化时,i = L,k = L+1,j=R(L表示最左边元素的索引,R表示最右边元素的索引)

通过上一段的表述可知,初始化时
这里我们扫描的目的就是为了逐个减少未知元素,并将每个元素按照和pivot的大小关系放到不同的区间上去。
在k的扫描过程中我们可以对a[k]分为三种情况讨论
a[k] < pivot 交换a[i]和a[k],然后i和k都自增1,k继续扫描
a[k] = pivot k自增1,k接着继续扫描
-
a[k] > pivot 这个时候显然a[k]应该放到最右端,大于pivot的部分。但是我们不能直接将a[k]与a[j]交换,因为目前a[j]和pivot的关系未知,所以我们这个时候应该从j的位置自右向左扫描。而a[j]与pivot的关系可以继续分为三种情况讨论
- a[j] > pivot --- j自减1,j接着继续扫描
- a[j] = pivot --- 交换a[k]和a[j],k自增1,j自减1,k继续扫描(注意此时j的扫描就结束了)
- a[j] < pivot --- 此时我们注意到a[j] < pivot, a[k] > pivot, a[i] == pivot,那么我们只需要将a[j]放到a[i]上,a[k]放到a[j]上,而a[i]放到a[k]上。然后i和k自增1,j自减1,k继续扫描(注意此时j的扫描就结束了)
注意,当扫描结束时,i和j的表示了=等于pivot部分的起始位置和结束位置。我们只需要对小于pivot的部分以及大于pivot的部分重复上述操作即可。

public static void QuickSort3Way(int[] A, int L, int R){
if(L >= R){//递归终止条件,少于等于一个元素的数组已有序
return;
}
int i,j,k,pivot;
pivot = A[L]; //首元素作为中轴
i = L;
k = L+1;
j = R;
OUT_LOOP:
while(k <= j){
if(A[k] < pivot){
Swap(A, i, k);
i++;
k++;
}else
if(A[k] == pivot){
k++;
}else{// 遇到A[k]>pivot的情况,j从右向左扫描
while(A[j] > pivot){//A[j]>pivot的情况,j继续向左扫描
j--;
if(j < k){
break OUT_LOOP;
}
}
if(A[j] == pivot){//A[j]==pivot的情况
Swap(A, k, j);
k++;
j--;
}else{//A[j]双轴快速排序
双轴快速排序算法的思路和上面的三向切分快速排序算法的思路基本一致,双轴快速排序算法使用两个轴元素,通常选取最左边的元素作为pivot1和最右边的元素作pivot2。首先要比较这两个轴的大小,如果pivot1 > pivot2,则交换最左边的元素和最右边的元素,已保证pivot1 <= pivot2。双轴快速排序同样使用i,j,k三个变量将数组分成四部分

A[L+1, i]是小于pivot1的部分,A[i+1, k-1]是大于等于pivot1且小于等于pivot2的部分,A[j, R]是大于pivot2的部分,而A[k, j-1]是未知部分。和三向切分的快速排序算法一样,初始化i = L,k = L+1,j=R,k自左向右扫描直到k与j相交为止(k == j)。我们扫描的目的就是逐个减少未知元素,并将每个元素按照和pivot1和pivot2的大小关系放到不同的区间上去。
在k的扫描过程中我们可以对a[k]分为三种情况讨论(注意我们始终保持最左边和最右边的元素,即双轴,不发生交换)
a[k] < pivot1 i先自增,交换a[i]和a[k],k自增1,k接着继续扫描
a[k] >= pivot1 && a[k] <= pivot2 k自增1,k接着继续扫描
-
a[k] > pivot2: 这个时候显然a[k]应该放到最右端大于pivot2的部分。但此时,我们不能直接将a[k]与j的下一个位置a[--j]交换(可以认为A[j]与pivot1和pivot2的大小关系在上一次j自右向左的扫描过程中就已经确定了,这样做主要是j首次扫描时避免pivot2参与其中),因为目前a[--j]和pivot1以及pivot2的关系未知,所以我们这个时候应该从j的下一个位置(--j)自右向左扫描。而a[--j]与pivot1和pivot2的关系可以继续分为三种情况讨论
- a[--j] > pivot2 j接着继续扫描
- a[--j] >= pivot1且a[j] <= pivot2 交换a[k]和a[j],k自增1,k继续扫描(注意此时j的扫描就结束了)
- a[--j] < pivot1 先将i自增1,此时我们注意到a[j] < pivot1, a[k] > pivot2, pivot1 <= a[i] <=pivot2,那么我们只需要将a[j]放到a[i]上,a[k]放到a[j]上,而a[i]放到a[k]上。k自增1,然后k继续扫描(此时j的扫描就结束了)

注意
- pivot1和pivot2在始终不参与k,j扫描过程。
- 扫描结束时,A[i]表示了小于pivot1部分的最后一个元素,A[j]表示了大于pivot2的第一个元素,这时我们只需要交换pivot1(即A[L])和A[i],交换pivot2(即A[R])与A[j],同时我们可以确定A[i]和A[j]所在的位置在后续的排序过程中不会发生变化(这一步非常重要,否则可能引起无限递归导致的栈溢出),最后我们只需要对A[L, i-1],A[i+1, j-1],A[j+1, R]这三个部分继续递归上述操作即可。

public static void QuickSortDualPivot(int[] A, int L, int R){
if(L >= R){
return;
}
if(A[L] > A[R]){
Swap(A, L, R); //保证pivot1 <= pivot2
}
int pivot1 = A[L];
int pivot2 = A[R];
//如果这样初始化 i = L+1, k = L+1, j = R-1,也可以
//但代码中边界条件, i,j先增减,循环截止条件,递归区间的边界都要发生相应的改变
int i = L;
int k = L+1;
int j = R;
OUT_LOOP:
while(k < j){
if(A[k] < pivot1){
i++;//i先增加,首次运行pivot1就不会发生改变
Swap(A, i, k);
k++;
}else
if(A[k] >= pivot1 && A[k] <= pivot2){
k++;
}else{
while(A[--j] > pivot2){//j先增减,首次运行pivot2就不会发生改变
if(j <= k){//当k和j相遇
break OUT_LOOP;
}
}
if(A[j] >= pivot1 && A[j] <= pivot2){
Swap(A, k, j);
k++;
}else{
i++;
Swap(A, j, k);
Swap(A, i, k);
k++;
}
}
}
Swap(A, L, i);//将pivot1交换到适当位置
Swap(A, R, j);//将pivot2交换到适当位置
//一次双轴切分至少确定两个元素的位置,这两个元素将整个数组区间分成三份
QuickSortDualPivot(A, L, i-1);
QuickSortDualPivot(A, i+1, j-1);
QuickSortDualPivot(A, j+1, R);
}
下面代码初始化方式使得边界条件更加容易确定,在下面代码的方式中A[L+1]A[i-1]表示小于pivot1的部分,A[i]A[j]表示两轴之间的部分,A[j]~A[R-1]表示大于pivot2的部分。
当排序数组中不存在pivot1~pivot2中的部分时,一趟交换完成后i恰好比j大1;当排序数组中仅仅存在一个元素x使得pivot1 <=x <=pivot2时,一趟交换完成,i和j恰好相等。
public static void QuickSortDualPivot(int[] A, int L, int R){
if(L >= R){
return;
}
if(A[L] > A[R]){
Swap(A, L, R); //保证pivot1 <= pivot2
}
int pivot1 = A[L];
int pivot2 = A[R];
int i = L+1;
int k = L+1;
int j = R-1;
OUT_LOOP:
while(k <= j){
if(A[k] < pivot1){
Swap(A, i, k);
k++;
i++;
}else
if(A[k] >= pivot1 && A[k] <= pivot2){
k++;
}else{
while(A[j] > pivot2){
j--;
if(j < k){//当k和j错过
break OUT_LOOP;
}
}
if(A[j] >= pivot1 && A[j] <= pivot2){
Swap(A, k, j);
k++;
j--;
}else{//A[j] < pivot1
Swap(A, j, k);//注意k不动
j--;
}
}
}
i--;
j++;
Swap(A, L, i);//将pivot1交换到适当位置
Swap(A, R, j);//将pivot2交换到适当位置
//一次双轴切分至少确定两个元素的位置,这两个元素将整个数组区间分成三份
QuickSortDualPivot(A, L, i-1);
QuickSortDualPivot(A, i+1, j-1);
QuickSortDualPivot(A, j+1, R);
}