轻量级网络:MobileNet系列V1、V2、V3
- 前言
- MobileNetV1
- MobileNetV2
- MobileNetV3
前言
在公司实习正好接触的是移动端的相关业务,于是对于轻量级网络也有了一定的了解,就先来总结一下MobileNet系列。
MobileNetV1
论文:https://arxiv.org/abs/1704.04861?context=cs
TensorFlow实现:https://github.com/Linchunhui/Classification-Set-with-Tensorflow/blob/master/net/MobileNetV1.py
MobileNet主要用于移动端计算模型,是将传统的卷积操作改为两层的卷积操作,在保证准确率的条件下,计算时间减少为原来的1/9,计算参数减少为原来的1/7.
MobileNet模型的核心就是将原本标准的卷积操作因式分解成一个depthwise convolution和一个1*1的pointwise convolution操作。简单讲就是将原来一个卷积层分成两个卷积层,其中前面一个卷积层的每个filter都只跟input的每个channel进行卷积,然后后面一个卷积层则负责combining,即将上一层卷积的结果进行合并。
- depthwise convolution:
比如输入的图片是Dk x Dk x M(Dk是图片大小,M是输入的渠道数),那么有M个Dw x Dw的卷积核,分别去跟M个渠道进行卷积,输出Df x Df x M结果
- pointwise convolution:
对Df x Df x M进行卷积合并,有1 x 1 x N的卷积,进行合并常规的卷积,输出Df x Df x N的结果。
上面经过这两个卷积操作,从一个Dk x Dk x M=>Df x Df x N,相当于用Dw x Dw x N的卷积核进行常规卷积的结果,但计算量从原来的DF x DF x DK x DK x M x N减少为DFxDFxDKxDKxM+DFxDFxMxN。

这张图基本就是MobileNetV1的核心了,主要就是通过Depthwise Conv替代传统Conv来大大减少了模型的参数,又通过1x1逐点卷积来结合通道间的信息,来减少准确率损失。
整体网络结构及参数如下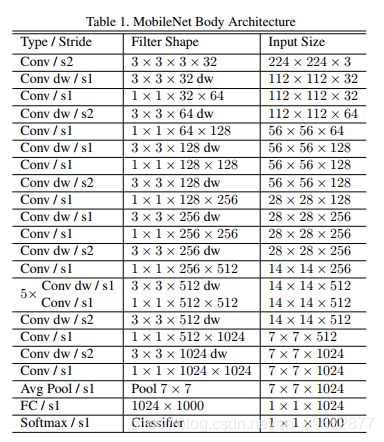
MobileNetV1还引入了两个超参数来进一步平衡模型大小以及准确率:
- Width Multiplier(α \alphaα): Thinner Models
所有层的 通道数(channel) 乘以 α 参数(四舍五入),模型大小近似下降到原来的 α2倍,计算量下降到原来的 α2 倍;
α∈(0,1] \alpha \in (0, 1]α∈(0,1] with typical settings of 1, 0.75, 0.5 and 0.25,降低模型的宽度
- Resolution Multiplier(ρ \rhoρ): Reduced Representation
输入层的 分辨率(resolution) 乘以 ρ 参数 (四舍五入),等价于所有层的分辨率乘 ρ ,模型大小不变,计算量下降到原来的 ρ2倍
ρ∈(0,1] 降低输入图像的分辨率
MobileNetV2
论文:https://arxiv.org/abs/1801.04381
Tensorflow实现:https://github.com/Linchunhui/Classification-Set-with-Tensorflow/blob/master/net/MobileNetV2.py
两点改变:
-
Inverted residuals(倒置残差) : 通常的residuals block是通过11的卷积核将渠道减小,再经过33卷积,最后再通过1*1的卷积核从而将渠道数扩大回去,从而减少计算量.而Inverted residuals刚好相反,通过先扩大渠道数再进行卷积,最后再缩小回原来的渠道数.基本思想就是,通过将渠道数扩大,从而在中间层学到更多的特征,最后再总结筛选出优秀的特征出来.
-
Linear bottlenecks : 为了避免Relu函数对特征的损失,在最后经过11的卷积缩小渠道数后,放弃采用Relu激活函数,采用线性激活函数,在进行Eltwise sum操作.基本思想便是:在经历了11的卷积,降低渠道数,这个已经使某些信息丢失,而外,当特征渠道数变小,大部分的值都会趋向小于0,最后经过Relu激活函数,将再导致丢失一些特征信息.
MobileNetV2的核心结构如下

相较于主要的改进点就是吸取了ResNet的残差结构,另外在Dw Conv之前增加了1x1卷积来夸张的通道数,主要目的也是因为Dw Conv卷积维度小,而Relu有个特点就是会造成神经元“”die“”,这样一旦神经元“die”,那么这部分信息就完全丢失了,因此先扩张几倍,并且使用线性激活,这样避免了信息丢失,从而提高准确率。
MobileNetV3
论文:https://arxiv.org/abs/1905.02244
Tensorflow实现:https://github.com/Linchunhui/Classification-Set-with-Tensorflow/blob/master/net/MobileNetV3.py
- 高效的网络构建模块
前面已经说过,MobileNetV3 是神经架构搜索得到的模型,其内部使用的模块继承自:
MobileNetV1 模型引入的深度可分离卷积(depthwise separable convolutions);
MobileNetV2 模型引入的具有线性瓶颈的倒残差结构(the inverted residual with linear bottleneck);
MnasNet 模型引入的基于squeeze and excitation结构的轻量级注意力模型。
这些被证明行之有效的用于移动端网络设计的模块是搭建MobileNetV3的积木。
- 互补搜索
架构搜索这一块并不了解,就权当翻译了。
在网络结构搜索中,作者结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt,前者用于在计算和参数量受限的前提下搜索网络的各个模块,所以称之为模块级的搜索(Block-wise Search) ,后者用于对各个模块确定之后网络层的微调。
这两项技术分别来自论文:
M. Tan, B. Chen, R. Pang, V. Vasudevan, and Q. V. Le. Mnasnet: Platform-aware neural architecture search for mobile. CoRR, abs/1807.11626, 2018.
T. Yang, A. G. Howard, B. Chen, X. Zhang, A. Go, M. Sandler, V. Sze, and H. Adam. Netadapt: Platform-aware neural network adaptation for mobile applications. In ECCV, 2018
- 网络结构改进
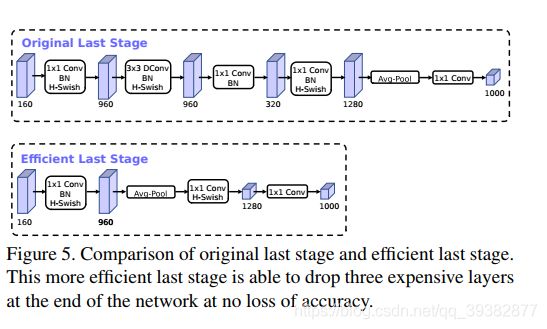
MobileNetV2模型中反转残差结构和变量利用了1*1卷积来构建最后层,以便于拓展到高维的特征空间,虽然对于提取丰富特征进行预测十分重要,但却引入了二外的计算开销与延时。为了在保留高维特征的前提下减小延时,将平均池化前的层移除并用1x1卷积来计算特征图。特征生成层被移除后,先前用于瓶颈映射的层也不再需要了,这将为减少10ms的开销,在提速15%的同时减小了30m的操作数。 - h-swish激活函数
- 作者发现swish激活函数能够有效提高网络的精度。然而,swish的计算量太大了。作者提出h-swish(hard version of swish)如下所示
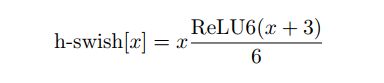
这种非线性在保持精度的情况下带了了很多优势,首先ReLU6在众多软硬件框架中都可以实现,其次量化时避免了数值精度的损失,运行快。这一非线性改变将模型的延时增加了15%。但它带来的网络效应对于精度和延时具有正向促进,剩下的开销可以通过融合非线性与先前层来消除。 - MobileNetV3网络结构
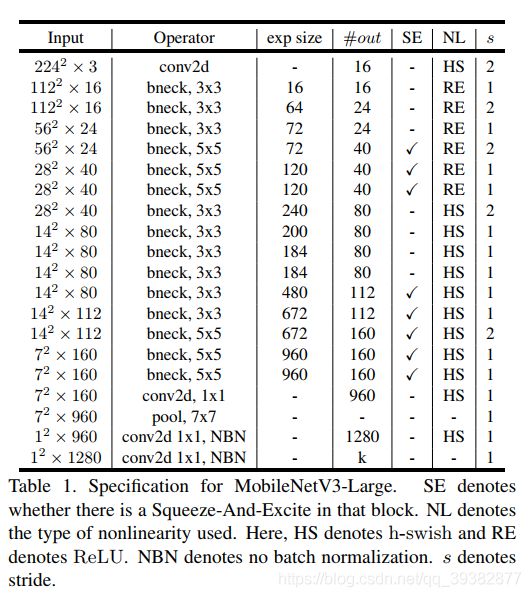
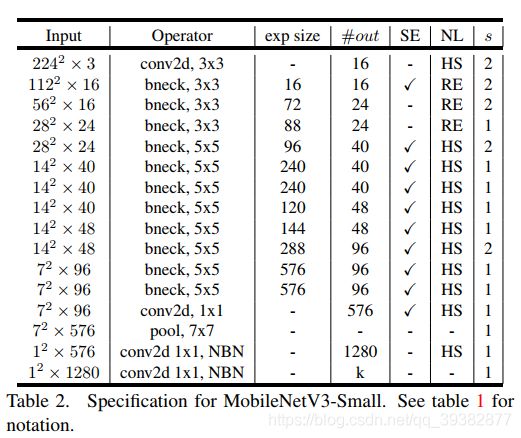
作者提出了MobileNetV3-Large和MobileNetV3-Small两种不同大小的网络结构。如下图所示