爬虫概述
文章目录
- 爬虫相关知识
-
- 1.1 爬虫概述
- 1.2 爬虫语言
- 1.3 爬虫分类
- 协议
-
- 2.1 OSI七层模型
- 2.2 HTTP协议与HTTPS协议
- 2.3 服务器常见端口
爬虫相关知识
1.1 爬虫概述
- 爬虫, 又称网页蜘蛛或网络机器人
- 爬虫是 模拟人操作客户端(浏览器, APP) 向服务器发起网络请求 抓取数据的自动化程序或脚本
1.模拟: 用爬虫程序伪装出人的行为, 避免被服务识别为爬虫程序
2.客户端: 浏览器, APP都可以实现人与服务器之间的交互行为, 应用客户端从服务器获取数据
3.自动化: 数据量较小时可以人工获取数据, 但往往在公司中爬取的数据量在百万条, 千万条级别的, 所以要程序自动化获取数据.
1.2 爬虫语言
爬虫语言: PHP, C/C++, Java, Python, GO
爬虫语言对比:
- PHP: 并发能力差, 对多进程和多线程支持不好, 数据量较大时爬虫效率较低
- C/C++: 语言效率高, 但学习成本高, 对程序员的技术能力要求较高, 所以目前还停留在研究层面, 市场需求量很小
- Java: Python爬虫的主要竞争对手, 由于Java语言的特点, 代码臃肿, 代码量大, 维护成本重构成本高, 开发效率低. 但目前市场上岗位需求比较旺盛.
- Python: 语法简单, 学习成本较低, 对新手比较友好. Python语言良好的生态, 大量库和框架的支持是的Python爬虫目前处于爬虫圈的主导地位
1.3 爬虫分类
- 通用爬虫
- 聚焦爬虫
- 增量式爬虫
- 深度爬虫
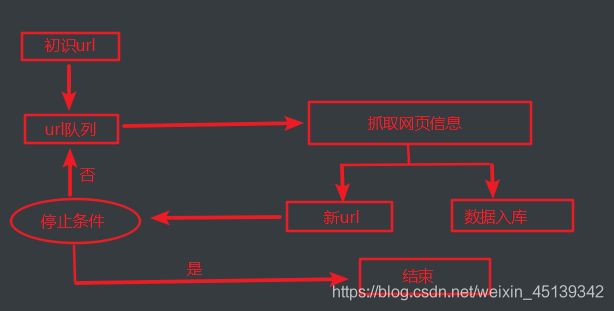
1.通用爬虫:搜索引擎
# 实例: 百度, 搜狗, Google的搜索引擎
# 功能: 访问网页 -> 抓取数据 -> 数据处理 -> 提供检索服务
# 工作流:
1.给定一个起始URL, 存于爬取队列中
2.爬虫程序从队列中取出url, 爬取数据
3.解析爬取数据, 获取网页内的所有url, 放入爬取队列
4.重复第二个步骤
# 使搜索引擎获取网站链接:
1.主动将url提交给搜索引擎('需要爬取的网址')
2.在其他热门网站设置友情链接
3.百度和DNS服务商合作, 收录新网站
# 网站排名(SEO):
1.根据PageRank值进行排名(流量, 点击率)
2.百度竞价排名, 钱多就靠前排
# 缺点:
1.抓取的内容多数无用
2.无法精确获取数据
# 协议: robots协议 --> 约定哪些内容允许哪些爬虫抓取
1.无需遵守, 该协议适用于通用爬虫, 而我们写的是聚焦爬虫
2.查看方法: 网站url/robots.txt, 如https://www.baidu.com/robots.txt
2.聚焦爬虫
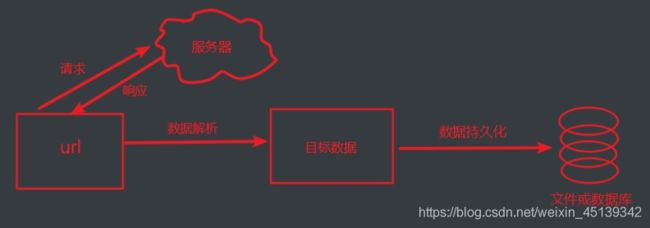
# 概念:
聚焦爬虫指针对某一领域根据特定要求实现的爬虫程序, 抓取需要的数据(垂直领域爬取)
# 设计思路:
(1).确定爬取的url, 模拟浏览器请服务器发送请求
(2).获取响应数据并进行数据解析
(3).将目标数据持久化到本地
协议
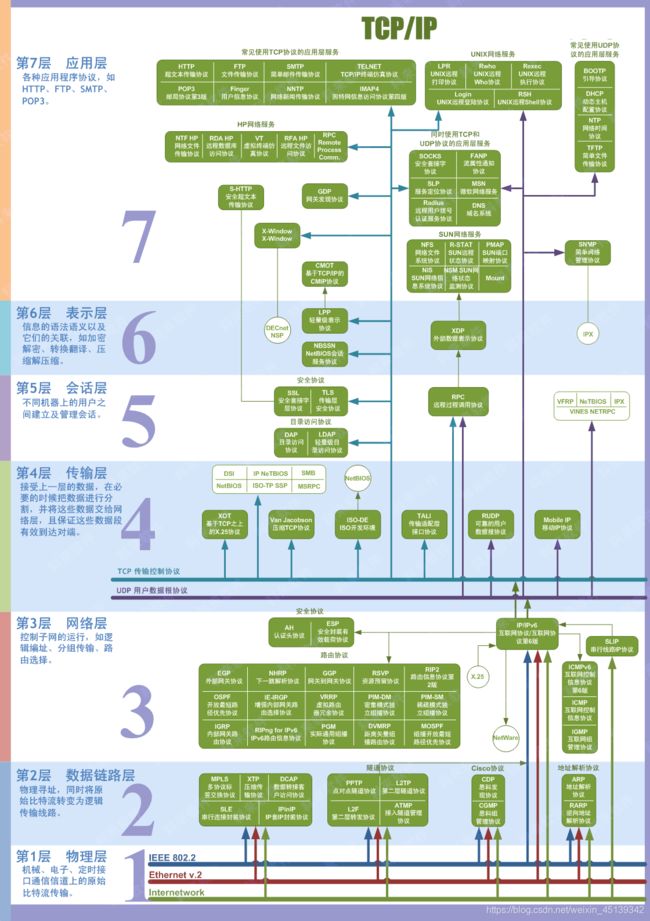
2.1 OSI七层模型
OSI 七层模型通过七个层次化的结构模型使不同的系统不同的网络之间实现可靠的通讯
因此其最主要的功能就是帮助不同类型的主机实现数据传输
2.2 HTTP协议与HTTPS协议
# HTTP协议: 明文传输, 端口80
1、Http协议, 全称为Hyper Text Transfer Protocol, 即超文本传输协议.
2、HTTP协议是用于从网络传输超文本数据到本地浏览器的传送协议, 它能保证高效而准确地传送超文本文档.
目前广泛使用的是HTTP 1.1版本
# HTTPS协议: 加密传输, 端口443
1、HTTPS全称是Hyper Text Transfer Protocol over Secure Socket Layer, 是以安全为目标的HTTP通道. HTTPS协议实质是HTTP的安全版, 即HTTP下加入SSL安全套接层, 简称HTTPS.
2、 HTTPS的安全体现在SSL的加密行为, 即通过HTTPS协议传输的数据都是经过SSL加密的
3、HTTPS的作用:
1.建立一个信息安全的通道来保证数据传输的安全
2.确认网站的真实性, 凡是使用了HTTPS的网站, 都可以通过点击浏览器地址栏的锁头标志来查看网站认证之后的真实信息, 也可以通过CA机构颁发的安全签章来查询
# HTTP与HTTPS协议的区别:
1)、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2)、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3)、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4)、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
# TCP与UDP
1.TCP协议:是一种面向连接的, 可靠的, 基于字节流的传输层通信协议
1).有序性: 数据包编号, 判断数据包的正确次序
2).正确性: 使用checksum函数检查数据包是否损坏, 发送接收时都会计算校验和
3).可靠性: 发送端有超时重发, 并由确认机制识别错误和数据的丢失
4).可控性: 滑动窗口协议与拥塞控制算法控制数据包的发送速度
2.UDP协议: 用户数据报协议, 面向无连接的传输层协议, 传输不可靠.
1).无连接, 数据可能丢失或损坏
2).报文小, 传输速度快
3).吞吐量大的网络传输, 可以在一定程度上承受数据丢失
2.3 服务器常见端口
- ftp: File Transfer Protocol的缩写, 即文件传输协议. 端口:21
- ssh: Secure Shell的缩写, 用于远程登录会话. 端口:22
- MySQL: 关系型数据库, 端口:3306
- MongoDB: 非关系型数据库, 端口:27017
- Redis: 非关系型数据库, 端口:6379
- http: 80
- https:443