学习和使用一段时间的spark, 对spark的总结一下,希望对大家有用,不介绍怎么使用, 只从设计上谈谈。
spark解决了什么问题?
说spark前一定要说一下, 就不得不提Google的三驾马车:Google FS、MapReduce、BigTable。其中对应开源实现如下:
Google FS -> hdfs、
MapReduce -> hadoop mapreduce
BigTable -> hbase
spark就是处理 mapreduce慢的问题。
在spark没出现前, hadoop是 v1 版本 有两个问题,
- 一个就是 hadoop的namenode单点以及内存问题(数据的node是放在内存中), v2也都解决了。
- hadoop的机器资源管理和计算管理都是 mapreduce进程管理,就是执行任务和资源都是mapduce一个在管理, v2独立出 yarn才解决这个问题的
- mapreduce慢的问题, 还是不能解决。 一开始定位就是在廉价的机器上运行。 定位不同。
说下mapreduce核心:
-
移动数据不如移动计算。 比如数据在一个节点上, 那就把计算放在这个节点上, 这样就没有网络磁盘IO了, 当然需要考虑机器的负载繁忙等。 -
合久必分,分久必合。 数据量很大, 处理不了,就拆分,分发到多台机器上,开始运算,运算结果再进行合并,最后输出。
这就是 map(分) reduce(合) 中间还有shuffle(洗牌)。 map和reduce都是并行的。
hadoop mapreduce是基于 文件的,相当于以数据为中心。 大量的磁盘网络IO。 一个mapreduce只能计算一个结果,不能迭代计算。 必须是前一个mapreduce的输出文件作为下一个输出。
spark就是解决mapreduce的慢的, spark是内存计算, 将数据加载到内存中计算, 所有速度快。 spark也有map reduce概念。
进行迭代计算。 数据在内存中, 上一步的计算结果,可以在下一步进行使用。
另外一个原因:
spark开发更容易,hadoop的mapreduce很麻烦,每次都要有 map,reuduce, driver三个类。
spark介绍
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,是一种开源的类Hadoop MapReduce的通用并行框架,拥有Hadoop MapReduce所具有的优点。
Spark不同于MapReduce的是,Spark的Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 主要有三个特点
首先,高级 API 剥离了对集群本身的关注,Spark 应用开发者可以专注于应用所要做的计算本身。
其次,Spark 很快,支持交互式计算和复杂算法。
最后,Spark 是一个通用引擎,可用它来完成各种各样的运算,包括 SQL 查询、文本处理、机器学习等,而在 Spark 出现之前,我们一般需要学习各种各样的引擎来分别处理这些需求。
总结一下:从各种方向上(比如开发速度和运行速度等)来看,Spark都优于Hadoop MapReduce;同时,Spark还提供大数据生态的一站式解决方案
spark架构
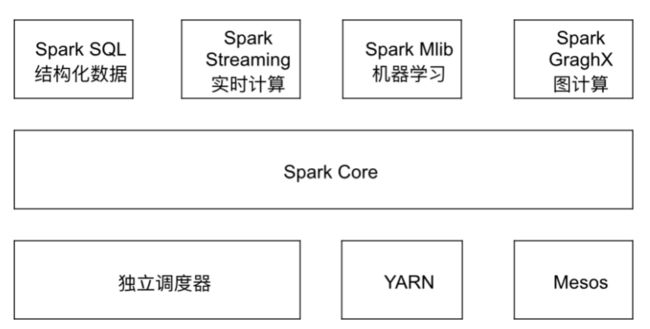
spark core是基础,上面都是转成 core来执行的。
spark是分布式,分成master和 work.
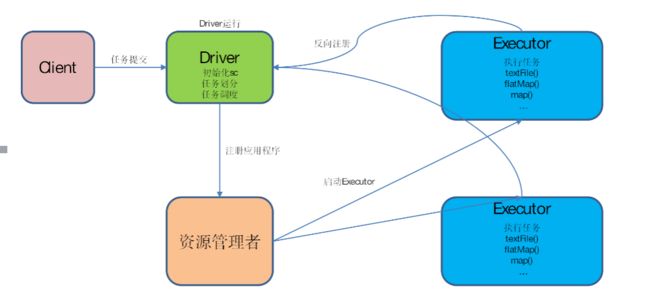
部署方式有很多种, 不同方式,对节点称呼不同
- spark的自身集群管理 master worker, 发布的是driver
- YARN 集群配合 hdfs使用的, 这个使用最多, spark没有存储。 所有用yarn和hdfs最密切。
- mesos
- k8s
spark核心
spark core的数据类型计算三种 RDD,Broadcast Variables,Accumulators
RDD:弹性分布式数据集
Broadcast Variables: 广播变量 将变量广播到所有执行的节点 只读
Accumulators: 累加器, 执行节点可以将累加结果回传到 driver, 执行节点,只写。
核心是 RDD,包括SQL的数据类型 DataFrame和DataSet以及 stream的 DStream也是对RDD包装的。
RDD特点
1)一组分区(Partition),即数据集的基本组成单位;
2)一个计算每个分区的函数;
3)RDD之间的依赖关系;
4)一个Partitioner,即RDD的分片函数;
5)一个列表,存储存取每个Partition的优先位置(preferred location)。
spark的功能都是在上面RDD数据结构特点上扩展完成的。
1. 分区
spark是分布式的, 分区就天然支持了, 可以提高并行度。 比如统计一个文件的word数量, 那不同分区,不同task进行处理,
最后将各个分区的结果合并就可以了。 分区可以改变。
2. 数据是只读
RDD加的数据都是只读的。 只读保证了任务失败重跑幂等性。 每一步执行都是产生新的RDD,不会修改原RDD。
3. 函数
函数就是操作,这就是spark中的算子,RDD的操作算子包括两类,一类叫做transformations,它是用来将RDD进行转化,构建RDD的血缘关系;另一类叫做actions,它是用来触发RDD的计算,得到RDD的相关计算结果或者将RDD保存的文件系统中。
就是所说的 惰性计算,没有触发计算,都是记录计算步骤,触发了步骤,才开始执行。
4. 依赖
RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生所必需的信息,RDDs之间维护着这种血缘关系,也称之为依赖。
这是spark数据失败重跑的依据。 DAG: 有向无环图。 spark的迭代计算。 函数式编程链式,在RDD中会保存一个依赖, 在上一个执行完。 每一步就一个点, 这样构成一个图。
5. 缓存
如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该RDD的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。
6. checkpoint
虽然RDD的血缘关系天然地可以实现容错,当RDD的某个分区数据失败或丢失,可以通过血缘关系重建。但是对于长时间迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从checkpoint处拿到数据。就是将数据持久化, 切断DAG图。
编程模型
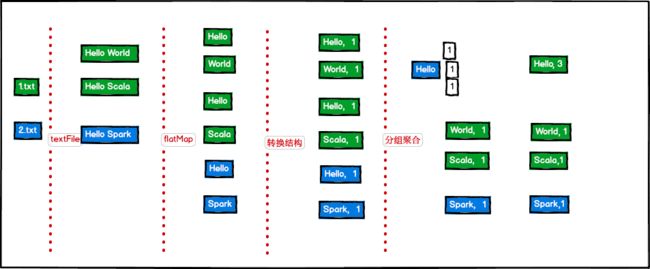
给个示例:
package org.jackson.exp
import org.apache.spark.{SparkConf, SparkContext}
object Wd {
def main(args: Array[String]): Unit = {
// 设置 conf
val conf = new SparkConf().setMaster("local[*]").setAppName("WC")
// 创建SparkContext,该对象是提交spark App的入口
val sc = new SparkContext(conf)
sc.textFile("/Users/zego/IdeaProjects/sparkOne/input").
flatMap(_.split(" ")). // 将一行进行按 " "拆分
map((_, 1)). // 转换数据类型 tuple
reduceByKey(_ + _). // 基于key进行 value 相加
coalesce(1). // 修改分区数
saveAsTextFile("/Users/zego/IdeaProjects/sparkOne/output")
sc.stop()
}
}
不同分区,不同task