Python-matplotlib 学术散点图 EE 统计及绘制

公众号后台回复“图书“,了解更多号主新书内容
作者:宁海涛
来源:DataCharm
01. 引言
之前的绘制图文Python-matplotlib 学术散点图完善Python-matplotlib 学术型散点图绘制 教程中,对学术散点图已经进行了较为完善的绘制教程,但这几天的通过准备 论文图表再现计划 以及后台小伙伴的留言,发现在绘制的相关性散点图中,各个范围的 Expected Error (EE)的统计个数没有在图表中进行展示 ,即下图中左下角的信息没有绘制。
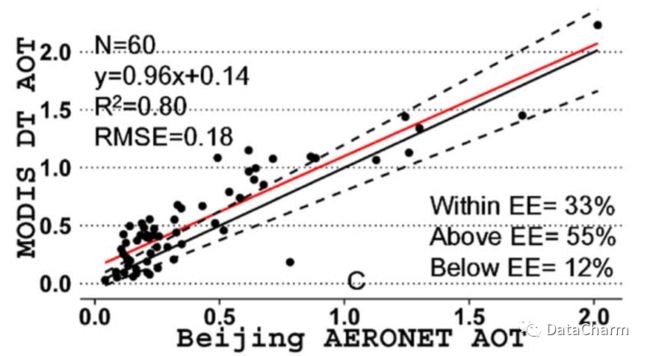
要完成上述的信息添加,只要涉及的知识点为 数据统计 的简单数据处理过程。下面就此问题进行详细的讲解。
02. 数据处理
要完成数据统计操作,首先要先进行三条拟合线的制作,具体如下:
#导入数据拟合函数
from scipy.stats import linregress
x2 = np.linspace(-10,10)
#制作最佳拟合线数据
y2=x2
#制作上拟合线数据
up_y2 = 1.15*x2 + 0.05
#制作下拟合线数据
down_y2 = 0.85*x2 - 0.05
#进行拟合
line_01 = linregress(x2,y2)
line_top = linregress(x2,up_y2)
line_bopptom = linregress(x2,down_y2)
其中,up_y2和down_y2 具体设置可以参考之前的推文Python-matplotlib 学术散点图完善 ,linregress () 拟合的结果如下:
![]()
slope 为斜率,intercept 为截距,rvalue 为相关系数 ,pvalue 为p值,stderr 为标准误差。
而原始的数据集如下(部分):
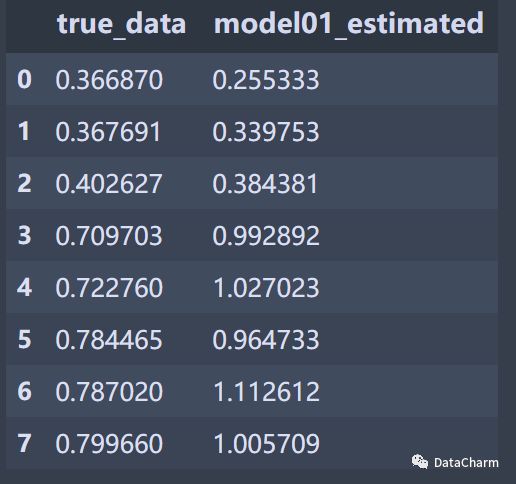
接下来我们根据相同的x值构建对应拟合线的三个y值,具体代码如下:
data_select = data_select.copy()
data_select['true_y'] = data_select.true_data.values
data_select['top_y'] = data_select['true_data'].apply(lambda x : line_top[0]*x + line_top[1])
data_select['bottom_y'] = data_select['true_data'].apply(lambda x : line_bopptom[0]*x + line_bopptom[1])
data_select.head()
这里涉及到pandas 处理数据常用 的 apply()函数,该方法对一般的数据处理步骤中经常使用,希望大家能够掌握。构建后的数据如下:

而判断 各个 Expected Error 的依据就是根据所构建的 top_y 、bottom_y和 model01_estimated 。将三者进行对比分析即可。
统计个数
所需数据构建好后,就可根据pandas 的数据选择操作进行筛选,最后统计个数即可,具体代码如下:
#构建 选择条件
top_condi = (data_select['model01_estimated'] > data_select['top_y'])
bottom_condi = (data_select['model01_estimated'] < data_select['bottom_y'])
bottom_top = ((data_select['model01_estimated'] < data_select['top_y']) & \
(data_select['model01_estimated'] > data_select['bottom_y']))
all_data = len(data_select)
top_counts = len(data_select[top_condi])
bottom_counts = len(data_select[bottom_condi])
bottom_top_counts = len(data_select[bottom_top])
进而求出不同 Expected Error 内的数据个数,本实例结果如下:
all_data = 4348
top_counts = 1681
bottom_counts = 404
bottom_top_counts = 2263
03. 数据可视化
数据可视化的绘制相对就比较简单的,大都和之前的推文也都一样,唯一不同的就是添加新内容部分,具体代码如下:
label_font = {'size':'22','weight':'medium','color':'black'}
ax.text(.7,.25,s='Within EE = ' + '{:.0%}'.format(bottom_top_counts/all_data),transform = ax.transAxes,
ha='left', va='center',fontdict=text_font)
ax.text(.7,.18,s='Above EE = ' + '{:.0%}'.format(top_counts/all_data),transform = ax.transAxes,
ha='left', va='center',fontdict=text_font)
ax.text(.7,.11,s='Below EE = ' + '{:.0%}'.format(bottom_counts/all_data),transform = ax.transAxes,
ha='left', va='center',fontdict=text_font)
完整代码如下:
import pandas as pd
import numpy as np
from scipy import optimize
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error,r2_score
from matplotlib.pyplot import MultipleLocator
#统一修改字体
plt.rcParams['font.family'] = ['Arial']
N = len(test_data['true_data'])
x = test_data['true_data'].values.ravel() #真实值
y = test_data['model01_estimated'].values.ravel()#预测值
C=round(r2_score(x,y),4)
rmse = round(np.sqrt(mean_squared_error(x,y)),3)
#绘制拟合线
x2 = np.linspace(-10,10)
y2=x2
def f_1(x, A, B):
return A*x + B
A1, B1 = optimize.curve_fit(f_1, x, y)[0]
y3 = A1*x + B1
#开始绘图
fig, ax = plt.subplots(figsize=(7,5),dpi=200)
ax.scatter(x, y,edgecolor=None, c='k', s=12,marker='s')
ax.plot(x2,y2,color='k',linewidth=1.5,linestyle='-',zorder=2)
ax.plot(x,y3,color='r',linewidth=2,linestyle='-',zorder=2)
#添加上线和下线
ax.plot(x2,up_y2,color='k',lw=1.,ls='--',zorder=2,alpha=.8)
ax.plot(x2,down_y2,color='k',lw=1.,ls='--',zorder=2,alpha=.8)
fontdict1 = {"size":17,"color":"k",}
ax.set_xlabel("True Values", fontdict=fontdict1)
ax.set_ylabel("Estimated Values ", fontdict=fontdict1)
ax.grid(which='major',axis='y',ls='--',c='k',alpha=.7)
ax.set_axisbelow(True)
ax.set_xlim((0, 2.0))
ax.set_ylim((0, 2.0))
ax.set_xticks(np.arange(0, 2.2, step=0.2))
ax.set_yticks(np.arange(0, 2.2, step=0.2))
#设置刻度间隔
# x_major_locator=MultipleLocator(.5)
# #把x轴的刻度间隔设置为.5,并存在变量里
# y_major_locator=MultipleLocator(.5)
# ax.xaxis.set_major_locator(x_major_locator)
# #把x轴的主刻度设置为.5的倍数
# ax.yaxis.set_major_locator(y_major_locator)
for spine in ['top','left','right']:
ax.spines[spine].set_visible(None)
ax.spines['bottom'].set_color('k')
ax.tick_params(bottom=True,direction='out',labelsize=14,width=1.5,length=4,
left=False)
#ax.tick_params()
#添加题目
titlefontdict = {"size":20,"color":"k",}
ax.set_title('Scatter plot of True data and Model Estimated',titlefontdict,pad=20)
#ax.set_title()
fontdict = {"size":16,"color":"k",'weight':'bold'}
ax.text(0.1,1.8,r'$R^2=$'+str(round(C,3)),fontdict=fontdict)
ax.text(0.1,1.6,"RMSE="+str(rmse),fontdict=fontdict)
ax.text(0.1,1.4,r'$y=$'+str(round(A1,3))+'$x$'+" + "+str(round(B1,3)),fontdict=fontdict)
ax.text(0.1,1.2,r'$N=$'+ str(N),fontdict=fontdict)
#添加上下线的统计个数
text_font = {'size':'15','weight':'medium','color':'black'}
label_font = {'size':'22','weight':'medium','color':'black'}
ax.text(.9,.9,"(a)",transform = ax.transAxes,fontdict=text_font,zorder=4)
ax.text(.7,.25,s='Within EE = ' + '{:.0%}'.format(bottom_top_counts/all_data),transform = ax.transAxes,
ha='left', va='center',fontdict=text_font)
ax.text(.7,.18,s='Above EE = ' + '{:.0%}'.format(top_counts/all_data),transform = ax.transAxes,
ha='left', va='center',fontdict=text_font)
ax.text(.7,.11,s='Below EE = ' + '{:.0%}'.format(bottom_counts/all_data),transform = ax.transAxes,
ha='left', va='center',fontdict=text_font)
ax.text(.8,.056,'\nVisualization by DataCharm',transform = ax.transAxes,
ha='center', va='center',fontsize = 10,color='black')
# plt.savefig(r'E:\Data_resourses\DataCharm 公众号\Python\学术图表绘制\scatter_EE.png',
# width=7,height=4,dpi=900,bbox_inches='tight')
plt.show()
结果如下:
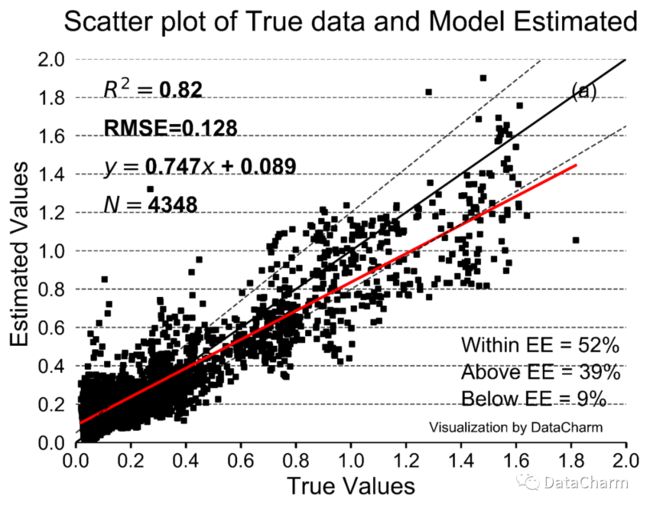
04. 总结
本期的推文主要就是介绍 如何统计 Expected Error 个数及将结果展示在绘图中,涉及的知识点点都是比较基础的 数据条件筛选及统计个数。pandas 库在数据处理及统计分析这一块应用起来是比较简单的,但也要多练习,毕竟数据处理小技巧比较多也易忘。还有,也别说一个知识点发了多篇推文啊 ,毕竟个人能力有限,自己也在不断学习,且不同的需求也是在交流中完善,希望大家后台多提意见或进群讨论,让我知道你们的需求,推文内容也会相应进行涉及。当然,我的 论文图表再现 计划的素材数据也在准备中
,毕竟个人能力有限,自己也在不断学习,且不同的需求也是在交流中完善,希望大家后台多提意见或进群讨论,让我知道你们的需求,推文内容也会相应进行涉及。当然,我的 论文图表再现 计划的素材数据也在准备中 。
。
◆ ◆ ◆ ◆ ◆
麟哥新书已经在京东上架了,我写了本书:《拿下Offer-数据分析师求职面试指南》,目前京东正在举行100-40活动,大家可以用相当于原价5折的预购价格购买,还是非常划算的:
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
猜你喜欢
● 麟哥拼了!!!亲自出镜推荐自己新书《数据分析师求职面试指南》● 厉害了!麟哥新书登顶京东销量排行榜!● 笑死人不偿命的知乎沙雕问题排行榜
● 用Python扒出B站那些“惊为天人”的阿婆主!● 你相信逛B站也能学编程吗点击阅读原文,即可参与京东100-50购书活动