这篇文章主要是对介绍AFM的原理以及跑AFM的源代码。
《Attentional Factorization Machines:Learning the Weight of Feature Interactions via Attention Networks∗》
AFM原文:Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks | IJCAI
源码已经被大牛整理了:Recommend-System-tf2.0/AFM at master · jc-LeeHub/Recommend-System-tf2.0 · GitHub
个人整理的源码:AFM-default · andyham/MachineLearning - 码云 - 开源中国 (gitee.com)
一、介绍&背景
1.1 摘要
《Attentional Factorization Machines:Learning the Weight of Feature Interactions via Attention Networks∗》这篇文章主要是说如何通过Attention学习特征之间的相互作用的权重。
比较白话地说,主要写了FM与Attention的结合,以及FM结合Attention后的效果。主要目的就是通过Attention来学习FM中的交互特征的重要性(权重)。
1.2 FM缺点以及AMF改进点
文章中提到,FM模型中,对于不同的特征会有相同的权重,这样不仅无法区分重点和非重要的特征,还会为模型增加不必要的噪声。
为了解决上面的问题,AMF的提出就是为了区分特征交互的重要性(weight),通过Attention学习特征交互的重要性(weight)。
1.3 FM
FM的细节这里就不说了,FM公式如下:

这里提一下,Wi是一个特征权重,wij是两个特征交互的权重。AFM就是在wij特征交互权重这里下功夫的。
这里详细根据公式可以看出FM有以下的不足:
(1)在估计第i个特征所设计的所有特征交互时,共享一个潜在向量Vi。
(2)所有估计的特征交互Wij的权重都为1。
(3)所有特征都会计算在内,但显然会存在不重要(无意义)的特征。
二、 AFM
下图为AFM的神经网络结构图。
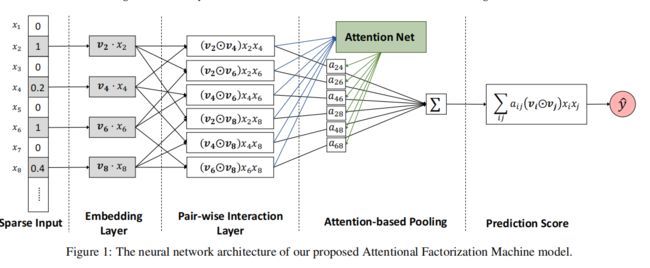
下面主要从成对交互层和基于Attention的池化层开始介绍AFM
2.1 可配对的交互层(Pair-wise Interaction Layer)
FM中交互公式如下:

通过定义成对交互层,我们可以在神经网络结构下表达FM。
为了说明这一点,使用一个sum pooling,然后用一个全连接层将其投射到预测分数中。公式如下:

上面公式中,P^T是预测层的权重,b为误差。
其实就是基于(2)公式首先进行求和,再与预测权重求积,最后在公式后面增加了b,即误差。
若P^T=1,b=0,就可以恢复回FM模型的公式了。
2.2 Attention池化层(Attention-based Pooling Layer)
基于FM的缺点,建议通过对交互向量进行加权和,对特征向量采用注意力机制(Attention):
其中aij是特征交互作用wij的注意力评分,体现了wij再预测中的重要性。
为了解决泛化性问题,用多层感知机(MLP)来确定Attention分数,即Attention network。
Attention network的输入是两个特征的交互向量,这可在embedding空间中体现交互信息:

其中T为隐藏层大小(attention factor),W为模型参数,计算aij时会做标准化处理。
基于Attention的池化层的输出是一个k维向量,它可通过区分重要性来压缩embedding空间中所有特征交互的作用。
整体AFM模型:
2.3 计算损失值
求loss公式如下:
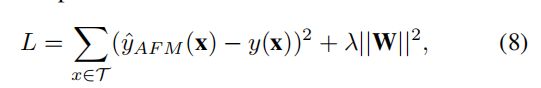
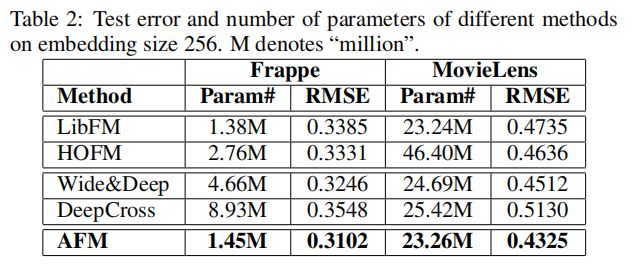
2.4 效果
在两个数据集Frappe以及Movielens上都有比较好的提升。
三、python实现
3.1 module准备
tensorflow==2.0.0
keras==2.4.3
numpy==1.16.0
pandas==1.0.3
scikit-learn==0.19.1
3.2 查看AFM下的数据结构
> tree
.
├── __init__.py
├── __pycache__
│ ├── layer.cpython-36.pyc
│ ├── model.cpython-36.pyc
│ └── utils.cpython-36.pyc
├── layer.py
├── model.py
├── tensorboard
│ └── events.out.tfevents.1621411918.PS2020GBYFOJBO.16880.5.v2
├── train.py
└── utils.py
2 directories, 9 files
主要是layer.py、model.py、train.py和utils.py这四个代码。可以大牛源码那里下载,也可以直接下载我整理的。
3.3 执行train.py文件
数据是在前面源码链接中的Data里面的train.txt。这里是数据是Criteo数据集,前十三列是数值特征(I1-I13),后面的是类别特征(C14-C39)。
把train.py中的file改了一下,如下:
file = r'../Data/train.txt'
修改后的train.py如下:
'''
# Time : 2020/12/9 17:28
# Author : junchaoli
# File : train.py
'''
from model import AFM
from utils import create_criteo_dataset
import tensorflow as tf
from tensorflow.keras import optimizers, losses, metrics
from sklearn.metrics import accuracy_score
if __name__ == '__main__':
file = r'../Data/train.txt'
test_size = 0.2
feature_columns, (X_train, y_train), (X_test, y_test) = \
create_criteo_dataset(file, test_size=test_size)
model = AFM(feature_columns, 'att')
optimizer = optimizers.SGD(0.01)
# dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
# dataset = dataset.batch(32).prefetch(tf.data.experimental.AUTOTUNE)
#
# model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
# model.fit(dataset, epochs=100)
# pre = model.predict(X_test)
summary = tf.summary.create_file_writer('tensorboard')
for i in range(100):
with tf.GradientTape() as tape:
pre = model(X_train)
loss = tf.reduce_mean(losses.binary_crossentropy(y_train, pre))
print(loss.numpy())
# with summary.as_default():
# tf.summary.scalar('loss', loss, i)
grad = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grad, model.variables))
pre = model(X_test)
pre = [1 if x>0.5 else 0 for x in pre]
print("Accuracy: ", accuracy_score(y_test, pre))
ps:如果要套其他数据就要从 utils.py中的create_criteo_dataset入手。
然后就在cmd中python train.py就可以执行成功了。
结果如下:(省略了一开始的误差)
·······
0.6361494
0.63559574
0.635045
0.6344969
0.6339517
0.6334093
0.63286966
0.6323327
0.6317983
0.6312668
0.6307378
0.6302117
0.6296881
0.6291671
Accuracy: 0.81
就是执行一步步把误差给计算出来,然后最后返回Accuracy。准确率是0.81。
在论文中测试的数据集是Frappe以及Movielens,待更新~~~~~~