本主题,通过爬取一个翻译网站,实现一个在线翻译程序为例,来说明下怎么处理签名验证的反爬虫技术分析过程。
- 签名校验的一般套路;
- 通过百度分析签名的实现原理;
- 用Python爬取百度的翻译结果;
一、签名校验的一般套路
面对互联网这么大个数据宝库,现在各种爬虫程序、爬虫框架遍地横行,各种IT江湖人士与非IT的各位寨主、帮主疯狂的爬取各自需要的数据。不过很多Web服务提供商也开始认识数据的价值,变免费为收费(百度,有道,金山三家在线翻译服务都开始收费了),也同时为了减轻服务器的负载、降低运营成本,Web服务供应商开始在技术上采取反爬虫机制。其中签名校验就是其中一种。
Web的签名校验理论上都是可以破解的。签名校验的关键是生成一个签名字符串,该签名要么在服务生成,要么在浏览器客户端生成;
1. 如果在服务器生成,需要客户端传递信息,在服务器生成后,发送给客户端,再由客服端发送给服务器校验,这种方式源头还是在客户端,理论上也是对所有用户开放的,也能找到客户传递的信息,并获取服务器发送的签名,从而破解。
2. 如果是在客户端浏览器生成的,则基于Javascrip的脚本非变编译性,我们可以找到生成签名的Javascript代码,通过分析代码破解签名算法。
二、百度翻译的签名算法分析
1、使用浏览器开发工具分析百度翻译
本主题使用Safari浏览器分析,其他浏览器基本上类似,有的没有开发工具,可以下载开发插件。
Safari的开发菜单如果没有,需要在设置中开启:
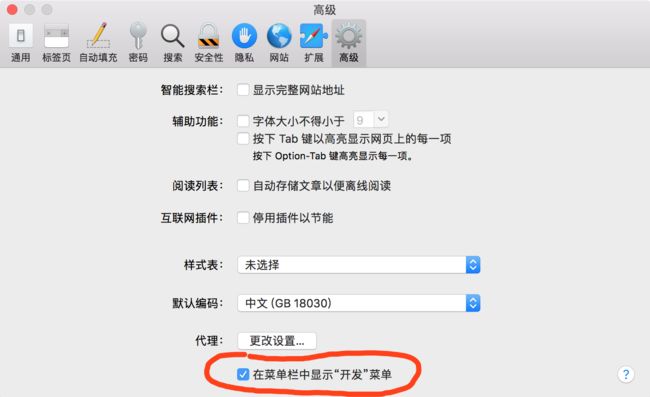
(1)打开浏览器开发工具
方式一:使用浏览器系统菜单

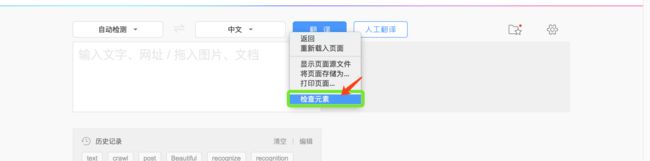

【网络】标签功能用来跟踪浏览器网络请求与服务器响应的过程比较有用。
【资源】主要用来分析浏览器下载后的资源数据,分析结果比较有用。
(2)跟踪翻译时的浏览器行为
在浏览器页面上输入需要翻译的数据,点击【网络】标签显示【网络】视图,在其中可以选择XHR查看浏览器发起的异步请求,异步请求都是通过Javascript代码实现:

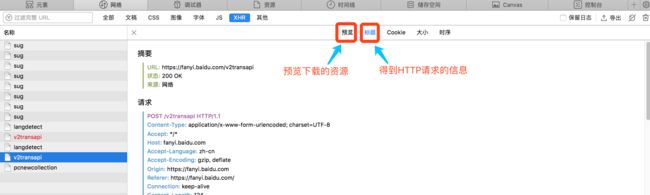
其中 【标题】中显示请求过程中相关信息包含:【摘要】【请求】【响应】与【请求数据】四个字段信息。
(3)分析调用方式并分析数据
从【摘要】字段中获取请求的URL:


我们首先得找到实现sign与token算法的Javascript代码,这个过程麻烦而无趣,可以自己写程序下载资源慢慢使用文本编辑工具找(比如Sublime,UtralEdit,Eclipse,VisualStudio,XCode等),也可以在浏览器的开发工具中慢慢找。关键是找到方法,我这儿采用的方法就是:在自己觉得对眼的js脚本中搜索关键字
sign与
token。
(4)找到签名的Javascript代码
►打开【JS】资源的视图:

►逐个文件搜索:
按照js文件搜索
sign与
token关键字(使用ctrl+f启动搜索视图):

2、分析Javascript代码
(1)AJAX请求代码分析,找到m函数
define("translation:widget/translate/input/translate", function(t, a) {
"use strict";
var e = t("translation:widget/translate/input/prompt"),
n = t("translation:widget/translate/input/textarea"),
r = t("translation:widget/common/util"),
s = t("translation:widget/translate/output/output"),
o = t("translation:widget/common/config/trans"),
i = t("translation:widget/translate/input/processlang"),
l = t("translation:widget/common/string"),
u = t("translation:widget/translate/input/soundicon"),
g = t("translation:widget/translate/input/hash"),
c = t("translation:widget/common/environment"),
d = t("translation:widget/translate/input/longtext"),
p = t("translation:widget/common/sendLog"),
y = t("translation:widget/translate/details/dictionary/simplemeans"),
f = t("translation:widget/translate/history/history"),
//========================================================================
m = t("translation:widget/translate/input/pGrab"),
//========================================================================
h = t("translation:widget/translate/details/adLink/adLink"),
w = {
onTrans: function(t) {
y.translateStopRepeat() || y.shutdownAudio();
var a = (n.getElem(), n.getVal()),
e = this,
s = t && t.transtype;
if (r.isUrl(a))
return void this.translateWebPage(a);
if (a.length > 0 && p.sendIndexDisplayLog({
action: "query"
}), this.isQueryValid(a)) {
var o = a;
o.length > 50 && (o = l.cutByByte(o, 0, 50).replace(/[\uD800-\uDBFF]$/, ""));
var i = {
query: o
};
$.ajax({
url: "/langdetect",
type: "POST",
data: I,
success: function(t) {
0 === t.error && t.lan ? e.langIsDeteced(t.lan, a, s) : e.reponseQuery(a)
}
})
}
},
isQueryValid: function(t) {
return t ? !0 : !1
},
processQuery: function(t) {
var a = t;
if (l.getByte(t) > o.MAX_QUERY_COUNT) {
c.set("needLongtextTip", !0);
var e = t;
a = l.cutByByte(t, 0, o.MAX_QUERY_COUNT).replace(/[\uD800-\uDBFF]$/, ""), e = l.cutByByte(e, o.MAX_QUERY_COUNT, o.MAX_QUERY_COUNT + 9), d.showTip({
query: e
})
}
return a
},
langIsDeteced: function(t, a, n, r) {
if (null !== t) {
var s = $(".select-from-language .language-selected").attr("data-lang"),
o = $(".select-to-language .language-selected").attr("data-lang"),
l = !1;
c.get("langChangedByUser") && t === o && (l = !0);
var g = null;
r && !c.get("fromLangIsAuto") && s !== t ? g = i.processOcrLang(t, s, o) : (e.show(t, s), g = i.getLang(t, s, o)), u.show();
var d = this,
a = this.processQuery(a),
//========================================================================
p = {
from: g.fromLang,
to: g.toLang,
query: a,
transtype: n,
simple_means_flag: 3,
sign: m(a),
token: window.common.token
};
//========================================================================
this.translateXHR && 4 !== this.translateXHR.readyState && this.translateXHR.abort(), this.translateXHR = $.ajax({
type: "POST",
url: "/v2transapi",
cache: !1,
data: p
}).done(function(t) {
c.set("isInRtTransState", !0), d.translateSuccess(t, g.fromLang, g.toLang, a, l)
})
}
},
translateWebPage: function(t) {
var a = "/";
"https:" === location.protocol && (a = "http://fanyi.baidu.com/"), document.location.href = [a + "transpage?", "query=" + encodeURIComponent(t), "&source=url", "&ie=utf8", "&from=" + $(".select-from-language .language-selected").attr("data-lang"), "&to=" + $(".select-to-language .language-selected").attr("data-lang"), "&render=1"].join("")
},
textareaFocus: function() {
n.focus()
},
translateSuccess: function(t, a, e, r, i) {
return n.getVal() ? (r && encodeURIComponent(r).length < o.MAX_URL_COUNT && f.add(a, e, $.trim(r)), f.hideHistory(), h.hide(), s.checkResponse({
res: t,
from: a,
to: e,
query: r,
badCaseByForce: I
}), void g.setHash({
query: r
})) : void c.set("isInRtTransState", !1)
},
reponseQuery: function() {}
};
a.onTranslate = function(t) {
w.onTrans(t)
}, a.translateAfterOcr = function(t, a) {
_hmt.push(["_trackEvent", "首页", "59_首页页面_翻译query量_图片"]), w.langIsDeteced(t, a, void 0, !0)
}
});
根据m的定义格式,可以使用其中的字符串搜索到m的定义。m的定义如下:
m = t("translation:widget/translate/input/pGrab"),
(2)找到m函数的原始定义
我们就根据"translation:widget/translate/input/pGrab"找代码,找到的代码如下:
define("translation:widget/translate/input/pGrab", function(r, o, t) {
"use strict";
function a(r) {
if (Array.isArray(r)) {
for (var o = 0, t = Array(r.length); o < r.length; o++)
t[o] = r[o];
return t
}
return Array.from(r)
}
function n(r, o) {
for (var t = 0; t < o.length - 2; t += 3) {
var a = o.charAt(t + 2);
a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a), a = "+" === o.charAt(t + 1) ? r >>> a : r << a, r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a
}
return r
}
function e(r) {
var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (null === o) {
var t = r.length;
t > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr(-10, 10))
} else {
for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = []; h > C; C++)
"" !== e[C] && f.push.apply(f, a(e[C].split(""))), C !== h - 1 && f.push(o[C]);
var g = f.length;
g > 30 && (r = f.slice(0, 10).join("") + f.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + f.slice(-10).join(""))
}
var u = void 0,
l = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);
u = null !== i ? i : (i = window[l] || "") || "";
for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) {
var A = r.charCodeAt(v);
128 > A ? S[c++] = A : (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)), S[c++] = A >> 18 | 240, S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224, S[c++] = A >> 6 & 63 | 128), S[c++] = 63 & A | 128)
}
for (var p = m, F = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), D = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), b = 0; b < S.length; b++)
p += S[b], p = n(p, F);
return p = n(p, D), p ^= s, 0 > p && (p = (2147483647 & p) + 2147483648), p %= 1e6, p.toString() + "." + (p ^ m)
}
var i = null;
t.exports = e
});
这个模块定义中有a,n,e三个函数定义,但最后有个语句,说明最终的签名算法函数是e:
t.exports = e
剩下的事情就是读懂e函数中的算法。e函数最后的return语句,最后一个语句的返回值与我们在浏览器看到的sign值格式类似。
p %= 1e6, p.toString() + "." + (p ^ m)
下面是浏览器中的sign值格式:
请求数据
MIME 类型: application/x-www-form-urlencoded; charset=UTF-8
from: en
to: zh
query: perfect
transtype: realtime
simple_means_flag: 3
================================================
sign: 173319.411190
================================================
token: 5132afa657f678cc1ed6c0caf37fc2a2
3、百度签名算法的处理技巧
遗憾的是,现在没有时间去详细移植这段算法到Python,计算移植后也没有多大意义,因为这个算法今后也会改变。但我们有了百度的Javascript代码,充分利用这个代码才是最牛的,程序员就用程序员的手段搞定,找一个Javascript运算引擎,在Python中直接执行Javascript代码,获取sign算法计算结果(想把这个算法搞明白的童鞋,我不拦你)。
实际上很多语言的各种库中,基本上总有一款都能支持Javascript调用的,我知道的Java,C++,C#都是可以的,作为语言中的大杀器Python有支持Javascript运行的库是必然的:js2py模块就是。
js2py的安装:
>pip install js2py
三、使用Python实现爬取百度翻译的信息
1、js2py的使用
#coding=utf-8
import js2py
script=r'''
a=20;
f=function(param1,param2){
return param1+param2
}
'''
#构造JS执行上下文环境
ctx = js2py.EvalJs()
#加载脚本
ctx.execute(script)
#访问变量
print(ctx.a) #20
#调用函数
print(ctx.f(45,55)) #100
2、使用requests获取window.common.token
window.common.token的值实际是在主页中一段javascript代码定义的,可以通过请求http://fanyi.baidu.com/得到。由于主页得到的是一段HTML资源,所以获取window.common.token
使用正则表达式查找即可。下面是在主页中找到的token的定义:

import requests
import re
#token识实在主页中加载
session = requests.Session()
response = session.get("http://fanyi.baidu.com/")
token = re.findall("token: ('.*'),",response.content.decode())[0]
print(token)
我机器返回的是:'9b8bb341109338ba7e875bd9a9dd88ba',其中需要解释下的是Python的正则表达式,"token: ('.*'),"就是返回token:与,之间的任意字符串,返回的是列表,我们使用取第一个。
3、在Python中调用百度js脚本得到签名
百度签名函数中需要一个变量i,该变量主页的脚本中定义。下面是签名算法函数中有关的一段代码:
var u = void 0,
//===========================================================
l = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);
//===========================================================
u = null !== i ? i : (i = window[l] || "") || "";
//===========================================================
for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) {
var A = r.charCodeAt(v);
128 > A ? S[c++] = A : (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)), S[c++] = A >> 18 | 240, S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224, S[c++] = A >> 6 & 63 | 128), S[c++] = 63 & A | 128)
}
for (var p = m, F = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), D = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), b = 0; b < S.length; b++)
p += S[b], p = n(p, F);
return p = n(p, D), p ^= s, 0 > p && (p = (2147483647 & p) + 2147483648), p %= 1e6, p.toString() + "." + (p ^ m)
其中u获取的是window[l],如果大家对l变量的ASCII码103,116,107翻译成字符就是gtk,所以u的值应该是window.gtk或者window [ gtk ]。
#coding=utf-8
import js2py
import requests
import re
session = requests.Session()
response = session.get("http://fanyi.baidu.com/")
#获取window.gtk的值。
gtk = re.findall(";window.gtk = ('.*?');",response.content.decode())[0]
#要翻译的单词
word = 'perfect'
context = js2py.EvalJs()
#从浏览器拷贝的签名生成函数脚本(r-raw表示原生字符串)
js = r'''
function a(r) {
if (Array.isArray(r)) {
for (var o = 0, t = Array(r.length); o < r.length; o++)
t[o] = r[o];
return t
}
return Array.from(r)
}
function n(r, o) {
for (var t = 0; t < o.length - 2; t += 3) {
var a = o.charAt(t + 2);
a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a),
a = "+" === o.charAt(t + 1) ? r >>> a : r << a,
r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a
}
return r
}
function e(r) {
var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (null === o) {
var t = r.length;
t > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr(-10, 10))
} else {
for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = []; h > C; C++)
"" !== e[C] && f.push.apply(f, a(e[C].split(""))),
C !== h - 1 && f.push(o[C]);
var g = f.length;
g > 30 && (r = f.slice(0, 10).join("") + f.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + f.slice(-10).join(""))
}
var u = void 0
, l = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);
u ='null !== i ? i : (i = window[l] || "") || ""';
for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) {
var A = r.charCodeAt(v);
128 > A ? S[c++] = A : (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)),
S[c++] = A >> 18 | 240,
S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224,
S[c++] = A >> 6 & 63 | 128),
S[c++] = 63 & A | 128)
}
for (var p = m, F = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), D = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), b = 0; b < S.length; b++)
p += S[b],
p = n(p, F);
return p = n(p, D),
p ^= s,
0 > p && (p = (2147483647 & p) + 2147483648),
p %= 1e6,
p.toString() + "." + (p ^ m)
}
'''
#在javascript脚本中把u的值替换成window.gtk
js = js.replace('\'null !== i ? i : (i = window[l] || "") || ""\'',gtk)
#执行js
context.execute(js)
#调用函数得到sign
sign = context.e(word)
print(sign) #173319.411190
下面是程序计算与浏览器中显示的出来的sign值比较:

百度翻译中提供三个请求功能:
( 1). sug请求简单的翻译,是免费的,可以随意获取,没有采取反爬虫技术。

( 3). v2transapi提供功能更加强悍的翻译结果。包含下面图示中的使用箭头标示的四个翻译结果

4、使用v2transapi实现功能更强的翻译
下面代码的实现原理:
(1)首先使用get方法请求百度翻译的首页https://fanyi.baidu.com/,从中获取两个信息token,gtk,其中的关键在于我们使用了从浏览器产生的headers格式。
(2)然后使用gtk产生sign,并使用token与sign,以及其他数据构造请求数据,发去爬取请求,获得我们需要的数据。
数据的解析与分析,这里代码就不实现了。
【代码如下】:
import requests
import re
import js2py
import json
class SignAndToken:
def __init__(self):
#加载主页
self.session = requests.Session()
self.headers={
"Cookie":"Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1541668433; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1541430897,1541471052,1541641285,1541668433; from_lang_often=%5B%7B%22value%22%3A%22de%22%2C%22text%22%3A%22%u5FB7%u8BED%22%7D%2C%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%2C%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%5D; to_lang_often=%5B%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%2C%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%5D; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; REALTIME_TRANS_SWITCH=1; SOUND_PREFER_SWITCH=1; SOUND_SPD_SWITCH=1; locale=zh; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=1430_21119_27401_26350_22158; PSINO=1; delPer=0; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; BDUSS=hsVWV6czh0a1hOQ3BaYkhTM0FrOXhNYnBCUWFsMlY0clhlYkNvTkRKdENDUGxiQUFBQUFBJCQAAAAAAAAAAAEAAAAFyMhmAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEJ70VtCe9FbY0; BIDUPSID=C53590ACE23DAC88DBE0C3D65AEBAA30; PSTM=1539535646; BAIDUID=DB00283B42FBC875B67496A00F47ABAB:FG=1",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Upgrade-Insecure-Requests":"1",
"Host":"fanyi.baidu.com",
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.1 Safari/605.1.15",
"Accept-Language":"zh-cn",
"Accept-Encoding": "gzip, deflate"
}
self.session.headers = self.headers
response = self.session.get("https://fanyi.baidu.com/")
#获取token
self.token = re.findall("token: ('.*'),",response.content.decode())[0]
self.token=self.token[1:-1]
print(self.token)
#获取gtk
# 获取window.gtk的值。
self.gtk = re.findall(";window.gtk = ('.*?');", response.content.decode())[0]
#初始化Javascript脚本执行上下文环境
self.context = js2py.EvalJs()
def sign(self,word):
# 从浏览器拷贝的签名生成函数脚本(r-raw表示原生字符串)
js = r'''
function a(r) {
if (Array.isArray(r)) {
for (var o = 0, t = Array(r.length); o < r.length; o++)
t[o] = r[o];
return t
}
return Array.from(r)
}
function n(r, o) {
for (var t = 0; t < o.length - 2; t += 3) {
var a = o.charAt(t + 2);
a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a),
a = "+" === o.charAt(t + 1) ? r >>> a : r << a,
r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a
}
return r
}
function e(r) {
var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (null === o) {
var t = r.length;
t > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr(-10, 10))
} else {
for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = []; h > C; C++)
"" !== e[C] && f.push.apply(f, a(e[C].split(""))),
C !== h - 1 && f.push(o[C]);
var g = f.length;
g > 30 && (r = f.slice(0, 10).join("") + f.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + f.slice(-10).join(""))
}
var u = void 0
, l = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);
u ='null !== i ? i : (i = window[l] || "") || ""';
for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) {
var A = r.charCodeAt(v);
128 > A ? S[c++] = A : (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)),
S[c++] = A >> 18 | 240,
S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224,
S[c++] = A >> 6 & 63 | 128),
S[c++] = 63 & A | 128)
}
for (var p = m, F = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), D = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), b = 0; b < S.length; b++)
p += S[b],
p = n(p, F);
return p = n(p, D),
p ^= s,
0 > p && (p = (2147483647 & p) + 2147483648),
p %= 1e6,
p.toString() + "." + (p ^ m)
}
'''
# 在javascript脚本中把u的值替换成window.gtk
js = js.replace('\'null !== i ? i : (i = window[l] || "") || ""\'', self.gtk)
# 执行js
self.context.execute(js)
# 调用函数得到sign
return self.context.e(word)
class TranslateTool:
def __init__(self):
self.sign_token=SignAndToken()
self.url="https://fanyi.baidu.com/v2transapi/"
self.headers={
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Accept":"*/*",
"Host":"fanyi.baidu.com",
"Accept-Language":"zh-cn",
"Accept-Encoding":"gzip, deflate",
"Origin":"https://fanyi.baidu.com",
"Referer":"https://fanyi.baidu.com/",
"Connection":"keep-alive",
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.1 Safari/605.1.15",
"X-Requested-With": "XMLHttpRequest",
"Cookie":"Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1541696184; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1541430897,1541471052,1541641285,1541668433; from_lang_often=%5B%7B%22value%22%3A%22de%22%2C%22text%22%3A%22%u5FB7%u8BED%22%7D%2C%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%2C%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%5D; to_lang_often=%5B%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%2C%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%5D; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; REALTIME_TRANS_SWITCH=1; SOUND_PREFER_SWITCH=1; SOUND_SPD_SWITCH=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=1430_21119_27401_26350_22158; PSINO=1; delPer=0; locale=zh; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; BDUSS=hsVWV6czh0a1hOQ3BaYkhTM0FrOXhNYnBCUWFsMlY0clhlYkNvTkRKdENDUGxiQUFBQUFBJCQAAAAAAAAAAAEAAAAFyMhmAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEJ70VtCe9FbY0; BIDUPSID=C53590ACE23DAC88DBE0C3D65AEBAA30; PSTM=1539535646; BAIDUID=DB00283B42FBC875B67496A00F47ABAB:FG=1"
}
def translate(self,word):
token=self.sign_token.token
sign=self.sign_token.sign(word)
#构造请求数据
data={
'from': 'en',
'to': 'zh',
'query': word,
'transtype': 'realtime',
'simple_means_flag': 3,
'sign': sign,
'token': token
}
#response=requests.post(self.url,data=data,headers=self.headers)
response=self.sign_token.session.post(self.url,data=data)
return response.content
tool=TranslateTool()
re=json.loads(tool.translate("perfect").decode())
print(re)
【运行结果】:

5、使用langdetect侦测输入的语言类型
langdetect的请求没有采用反爬虫技术,可以采用通用的http请求获取,这里就不提供实现代码:
MIME 类型: application/x-www-form-urlencoded; charset=UTF-8
kw: perfect
补充一个langdetect的小例子:
#coding=utf-8
import requests
import re
import js2py
import json
# 构造请求数据
url="https://fanyi.baidu.com/langdetect"
data = {
'query': '英雄'
}
response = requests.post(url, data=data)
print(response.content.decode())

6、使用sug实现简单翻译
sug与langdetect的请求基本上一样,其请求也没有采用反爬虫技术,可以采用通用的http请求获取,这里就不提供实现代码:
MIME 类型: application/x-www-form-urlencoded; charset=UTF-8
kw: perfect
补充一个sug的小例子:
#coding=utf-8
import requests
import re
import js2py
import json
# 构造请求数据
url="https://fanyi.baidu.com/sug"
data = {
'kw': 'test'
}
response = requests.post(url, data=data)
content=response.content.decode()
data=json.loads(content)["data"]
for item in data:
print(item['v'])

资源
- 代码清单:
|-测试javascript调用:callJavascript.py
|-获取百度产生的token:gettoken_baidu.py
|-完整翻译数据爬取:v2transapi.py - 下载地址:
|-https://github.com/QiangAI/PythonSkill/tree/master/baiduCrawler