最近要整一个协同过滤的推荐demo于是网上参考了些别人的博文思考思考。
import numpy as np
import pandas as pd
header = ['user_id', 'item_id', 'rating', 'timestamp']
df = pd.read_csv('u.data', sep='\t', names=header)
首先是导入我们的数据,基于movielens的1M数据,pandas非常方便的能够将数据以CSV格式读入,文本文件的话用sep参数输入你的分隔符也能等效。
# 计算唯一用户和电影的数量标准化矩阵
n_users = df.user_id.unique().shape[0]
n_items = df.item_id.unique().shape[0]
# 使用scikit-learn库将数据集分割成测试和训练。Cross_validation.train_test_split根据测试样本的比例(test_size)
from sklearn import cross_validation as cv
train_data, test_data = cv.train_test_split(df, test_size=0.2)
# 基于邻域的协同过滤
# 第一步是创建uesr-item矩阵,此处需创建训练和测试两个UI矩阵
train_data_matrix = np.zeros((n_users, n_items))
for line in train_data.itertuples():
train_data_matrix[line[1] - 1, line[2] - 1] = line[3]
print('train_data_matrix\n%s'%train_data_matrix)
test_data_matrix = np.zeros((n_users, n_items))
for line in test_data.itertuples():
test_data_matrix[line[1] - 1, line[2] - 1] = line[3]
通过我们之前得到的用户和电影的总数得到标准规模的矩阵,然后通过pd的迭代器给np[user][item]赋予评分,来形成user-item矩阵。
# 计算相似度
# 使用sklearn的pairwise_distances函数来计算余弦相似性
from sklearn.metrics.pairwise import pairwise_distances
item_similarity = pairwise_distances(train_data_matrix.T, metric='cosine')
通过输入初始评分矩阵的转置也就是以电影作为行,通过 pairwise_distances()计算相似度。我们的一行相当于一个矢量,这个方法就是计算这些向量的距离,返回的是距离矩阵,这里我们得到的就是相似度。这里的相似度度量是cosine,也就是余弦相似度作为相似度的衡量,且支持稀疏矩阵。
def predict(ratings, similarity, type='user'):
# 基于用户相似度矩阵的
if type == 'user':
mean_user_rating = ratings.mean(axis=1)
# You use np.newaxis so that mean_user_rating has same format as ratings
ratings_diff = (ratings - mean_user_rating[:, np.newaxis])
pred = mean_user_rating[:, np.newaxis] + similarity.dot(ratings_diff) / np.array(
[np.abs(similarity).sum(axis=1)]).T
# 基于物品相似度矩阵
elif type == 'item':
pred = ratings.dot(similarity) / np.array([np.abs(similarity).sum(axis=1)])#求评价均值
return pred
我们注意力先放在物品相似的计算上通过相似矩阵和评分矩阵做矩阵乘法,主要是根据下面公式生成最后推荐的权重,也就是用户的相似度与用户评分相乘,刚好与矩阵乘法结果对应,但是最后的结果得转化为评分所以除以各个相似度的参数总合,得到标准化的评分结果。
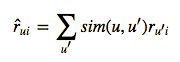
权重计算公式

评分标准化
# 预测结果
item_prediction = predict(train_data_matrix, item_similarity, type='item')
user_prediction = predict(train_data_matrix, user_similarity, type='user')
print(item_prediction[0:8])
# print(user_prediction)
# 评估指标,均方根误差
# 使用sklearn的mean_square_error (MSE)函数,其中,RMSE仅仅是MSE的平方根
# 只是想要考虑测试数据集中的预测评分,因此,使用prediction[ground_truth.nonzero()]筛选出预测矩阵中的所有其他元素
from sklearn.metrics import mean_squared_error
from math import sqrt
def rmse(prediction, ground_truth):
prediction = prediction[ground_truth.nonzero()].flatten()#取测试矩阵相同的部分计算RMSE
ground_truth = ground_truth[ground_truth.nonzero()].flatten()
return sqrt(mean_squared_error(prediction, ground_truth))
# print('User-based CF RMSE: ' + str(rmse(user_prediction, test_data_matrix)))
print('Item-based CF RMSE: ' + str(rmse(item_prediction, test_data_matrix)))
最后测试一下我们的RMSE

Item RMSE
几点优化:
1.生成评分时不考虑全部用户而是取top-k个电影来生成评分
2.不考虑评分而考虑评分的偏差
3.使用皮尔森作为度量标准
参考文章:http://blog.ethanrosenthal.com/2015/11/02/intro-to-collaborative-filtering/