[toc]
前言
本篇主要对CS20SI的chatbot项目进行分析,主要涉及四个文件, 可以在github上看到。
- chatbot.py
- config.py
- data.py
- model.py
Data
原始预料
movie_lines.txt
- movie_lines.txt
- contains the actual text of each utterance
- fields:
- lineID
- characterID (who uttered this phrase)
- movieID
- character name
- text of the utterance
example:
L19692 +++$+++ u214 +++$+++ m13 +++$+++ STRIKER +++$+++ It's a damn good thing he doesn't know how much I hate his guts.
L19691 +++$+++ u198 +++$+++ m13 +++$+++ ELAINE +++$+++ Sluggish. Like a wet sponge.
...
movie_conversations.txt
- movie_conversations.txt
- the structure of the conversations
- fields
- characterID of the first character involved in the conversation
- characterID of the second character involved in the conversation
- movieID of the movie in which the conversation occurred
- list of the utterances that make the conversation, in chronological
order: ['lineID1','lineID2',..,'lineIDN']
has to be matched with movie_lines.txt to reconstruct the actual content
example:
u0 +++$+++ u2 +++$+++ m0 +++$+++ ['L194', 'L195', 'L196', 'L197']
u0 +++$+++ u2 +++$+++ m0 +++$+++ ['L198', 'L199']
u0 +++$+++ u2 +++$+++ m0 +++$+++ ['L200', 'L201', 'L202', 'L203']
...
数据处理
- 首先,对于一个对话,两两提取question和answer,这样就可以得到一个question集合(encoder)和一个answer集合(decoder),然后拆分数据集,保存为train.dec, train.enc, test.dec, test.enc。每行是原始句子。
train.dec
Can we go now?
- 进行token2id工作,这里需要以下几个步骤:
- 分词;
- 构建词的token2id,这里需要包括4个特殊词:
, , , - 保存decoder所有词汇到vocab.dec; 保存encoder所有词汇到vocab.enc;(排个序词频小于某个阈值的不放进,缩小词表 ) 并记录两个词表长度到config文件,用于后续使用方便。
最终将上面的原始句子变成id的形式(不一定对应)保存起来,对于decoder,要在开始加,对应id为2和3.
train_ids.dec
2 44 26 21 9 14 3300 26 85 11 82 8 6 265 21 3
数据访问接口
提供get_batch函数来获取某个bucket的一个batch的训练数据。
get_batch
def get_batch(data_bucket, bucket_id, batch_size=1):
""" Return one batch to feed into the model, time-major format, each row of them represents an feed to the model
batch_encoder_inputs: the padded inputs of encoder with ids in reverse (encoder_size, batch_size);
encoder_size = max_encoder_time;
batch_decoder_inputs: the padded inputs of decoder with ids,(decoder_size, batch_size);
column [2,..,3] or [2,..3,0,..,0] (0: padding; 2: begin; 3: end);
decoder_size = max_decoder_time
batch_masks: same size as batch_decoder_inputs with value 0 or 1
"""
函数的功能是按照提供的bucket号,从分完组的buckets中提取出batch_size个训练数据。这里一个训练数据指的是一个question和一个对应的answer,分别是一维向量。
那么batch_size个就是两个(batch_size,encoder_size)以及(batch_size,decoder_size)大小的向量。
padding: 这里对于同一个bucket中的训练数据,将其padding到bucket的大小,就保证了对于同一个bucket,输入的数据维度是一致的。
这里返回的时候行列转置一下,也就是time-major的形式(==为什么?==)
这里返回的还有个mask矩阵(==为什么?==)
Model
create_placeholders()
inference()
create_loss()
creat_optimizer()
create_placeholders
包括4部分:
-
encoder_inputs
A list of 1D int32 Tensors of shape [batch_size], list size is max_size of encoder_inputs这里,建立最大encoder_size个tensor,每个tensor都是batch_size的大小,这里,并不是每次都会用到所有的tensor,如果某一步选batch的时候从一个比较小的bucket取数据(8,10)(encoder长度为8,decoder为10),那么feed的时候只会feed给8个encoder tensor. -
decoder_inputs这里与encoder_inputs建立的大小不同,建立最大decoder_size+1个,因为这里用encoder_inputs[1:]作为target,也就是输出结果,那么如果bucket取了最大的那个(如43),那么decoder的output也要43,而output是input右偏移一位,所以input需要多一位,不然decode的时候输入和输出长度就不一致了。 -
decoder_masks
和decoder_inputs大小一样,需要注意的是,和上面两个一样,feed的时候也是根据选择的bucket大小feed一部分,即decoder_size个,每个tensor的大小是batch_size,表示batch_size个训练数据的decode部分,在计算loss的时候的权重,即去掉padding的部分,只留下前面的部分,留下部分如下图所示:
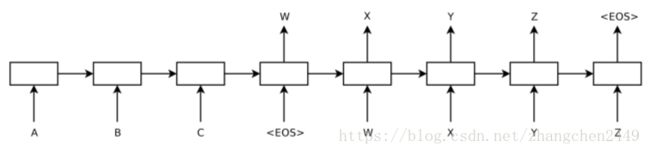 image
image
example:
decoder_input = [,W,X,Y,Z, ,PAD,PAD,PAD]
target = [W,X,Y,Z,,0,0,0,0]`
mask = [1,1,1,1,1,0,0,0,0]
内积后,实际上训练的只剩下上图所示的那部分了,padding的部分误差为0,不会反向传播进行训练。
-
targets,定义为decoder_inputs[1:]
inference
- 定义RNN结构,如选用GRU还是LSTM,用几层,每个cell的隐层单元数是多少。
- 定义
softmax_loss_function,这里采用sampled_softmax_loss
tf.nn.sampled_softmax_loss
@tf_export("nn.sampled_softmax_loss")
def sampled_softmax_loss(weights,
biases,
labels,
inputs, # A `Tensor` of shape `[batch_size, dim]`. The forward
activations of the input network.
num_sampled,
num_classes,
num_true=1,
sampled_values=None,
remove_accidental_hits=True,
partition_strategy="mod",
name="sampled_softmax_loss",
seed=None):
'''
Args:
weights: A `Tensor` of shape `[num_classes, dim]`, or a list of `Tensor`
objects whose concatenation along dimension 0 has shape
[num_classes, dim]. The (possibly-sharded) class embeddings.
biases: A `Tensor` of shape `[num_classes]`. The class biases.
labels: A `Tensor` of type `int64` and shape `[batch_size,
num_true]`. The target classes. Note that this format differs from
the `labels` argument of `nn.softmax_cross_entropy_with_logits_v2`.
inputs: A `Tensor` of shape `[batch_size, dim]`. The forward
activations of the input network.
num_sampled: An `int`. The number of classes to randomly sample per batch.
num_classes: An `int`. The number of possible classes.
num_true: An `int`. The number of target classes per training example.
sampled_values: a tuple of (`sampled_candidates`, `true_expected_count`,
`sampled_expected_count`) returned by a `*_candidate_sampler` function.
(if None, we default to `log_uniform_candidate_sampler`)
remove_accidental_hits: A `bool`. whether to remove "accidental hits"
where a sampled class equals one of the target classes. Default is
True.
partition_strategy: A string specifying the partitioning strategy, relevant
if `len(weights) > 1`. Currently `"div"` and `"mod"` are supported.
Default is `"mod"`. See `tf.nn.embedding_lookup` for more details.
name: A name for the operation (optional).
seed: random seed for candidate sampling. Default to None, which doesn't set
the op-level random seed for candidate sampling.
Returns:
A `batch_size` 1-D tensor of per-example sampled softmax losses.
'''
这里传进去的inputs是每一个时刻的结果,维度为[batch_size, num_decoder_symbols],输出是batch_size大小的tensor,表示最后一层单个cell的loss。
create_loss
构建seq2seq模型(tf.contrib.legacy_seq2seq.embedding_attention_seq2seq),计算batch_size个训练数据的loss的计算方式(tf.contrib.legacy_seq2seq.model_with_buckets),其中最后一层loss计算方式为上面定义的sampled_softmax_loss
tf.contrib.legacy_seq2seq.embedding_attention_seq2seq
def embedding_attention_seq2seq(encoder_inputs,
decoder_inputs,
cell,
num_encoder_symbols,
num_decoder_symbols,
embedding_size,
num_heads=1,
output_projection=None,
feed_previous=False,
dtype=None,
scope=None,
initial_state_attention=False):
'''
Args:
encoder_inputs: A list of 1D int32 Tensors of shape [batch_size].
decoder_inputs: A list of 1D int32 Tensors of shape [batch_size].
cell: tf.nn.rnn_cell.RNNCell defining the cell function and size.
num_encoder_symbols: Integer; number of symbols on the encoder side.
num_decoder_symbols: Integer; number of symbols on the decoder side.
embedding_size: Integer, the length of the embedding vector for each symbol.
num_heads: Number of attention heads that read from attention_states.
output_projection: None or a pair (W, B) of output projection weights and
biases; W has shape [output_size x num_decoder_symbols] and B has
shape [num_decoder_symbols]; if provided and feed_previous=True, each
fed previous output will first be multiplied by W and added B.
feed_previous: Boolean or scalar Boolean Tensor; if True, only the first
of decoder_inputs will be used (the "GO" symbol), and all other decoder
inputs will be taken from previous outputs (as in embedding_rnn_decoder).
If False, decoder_inputs are used as given (the standard decoder case).
dtype: The dtype of the initial RNN state (default: tf.float32).
scope: VariableScope for the created subgraph; defaults to
"embedding_attention_seq2seq".
initial_state_attention: If False (default), initial attentions are zero.
If True, initialize the attentions from the initial state and attention
states.
Returns:
A tuple of the form (outputs, state), where:
outputs: A list of the same length as decoder_inputs of 2D Tensors with
shape [batch_size x num_decoder_symbols] containing the generated
outputs.
state: The state of each decoder cell at the final time-step.
It is a 2D Tensor of shape [batch_size x cell.state_size].
"""
这个函数比较有意思,我们仔细来看看。
projection layer 作用:attention机制下,必须保存所有的encoder的output,大小是[batch_size x num_decoder_symbols],如果不使用projecttion layer,那么在内部会给你创建一个outputprojection,它的num_decoder_symbols就是decoder词表的大小,然后封装一下cell,把projecttion操作也加进去。就是说:
- output projection 为给定 (w,b):那么调用
cell.call()的输出就是(batch_size,output_size)大小tensor - output projection 为 None:那么调用
cell.call()时会默认执行内部的projection操作,输出是(batch_size,num_symbols)大小tensor,为词表大小,可见多了一次projection操作,效率会比较低。
这个函数主要做以下几个步骤:
- 给encoder加上一个embeding层,然后调用
rnn.static_run得到encoder的每个时刻输出结果time_step*(batch_size,output_size),这里output_size和state_size一样大小。 - encoder部分结束,保存每一步的output到
attention_states,大小为(batch_size, attn_length, attn_size). - 根据output projection处理是否封装cell。
- 调用
embedding_rnn_decoder,处理decoder部分。
tf.contrib.legacy_seq2seq.embedding_attention_decoder
def embedding_attention_decoder(decoder_inputs,
initial_state,
attention_states,
cell,
num_symbols,
embedding_size,
num_heads=1,
output_size=None,
output_projection=None,
feed_previous=False,
update_embedding_for_previous=True,
dtype=None,
scope=None,
initial_state_attention=False):
"""RNN decoder with embedding and attention and a pure-decoding option.
Args:
decoder_inputs: A list of 1D batch-sized int32 Tensors (decoder inputs).
initial_state: 2D Tensor [batch_size x cell.state_size].
attention_states: 3D Tensor [batch_size x attn_length x attn_size].
cell: tf.nn.rnn_cell.RNNCell defining the cell function.
num_symbols: Integer, how many symbols come into the embedding.
embedding_size: Integer, the length of the embedding vector for each symbol.
num_heads: Number of attention heads that read from attention_states.
output_size: Size of the output vectors; if None, use output_size.
output_projection: None or a pair (W, B) of output projection weights and
biases; W has shape [output_size x num_symbols] and B has shape
[num_symbols]; if provided and feed_previous=True, each fed previous
output will first be multiplied by W and added B.
feed_previous: Boolean; if True, only the first of decoder_inputs will be
used (the "GO" symbol), and all other decoder inputs will be generated by:
next = embedding_lookup(embedding, argmax(previous_output)),
In effect, this implements a greedy decoder. It can also be used
during training to emulate http://arxiv.org/abs/1506.03099.
If False, decoder_inputs are used as given (the standard decoder case).
update_embedding_for_previous: Boolean; if False and feed_previous=True,
only the embedding for the first symbol of decoder_inputs (the "GO"
symbol) will be updated by back propagation. Embeddings for the symbols
generated from the decoder itself remain unchanged. This parameter has
no effect if feed_previous=False.
dtype: The dtype to use for the RNN initial states (default: tf.float32).
scope: VariableScope for the created subgraph; defaults to
"embedding_attention_decoder".
initial_state_attention: If False (default), initial attentions are zero.
If True, initialize the attentions from the initial state and attention
states -- useful when we wish to resume decoding from a previously
stored decoder state and attention states.
Returns:
A tuple of the form (outputs, state), where:
outputs: A list of the same length as decoder_inputs of 2D Tensors with
shape [batch_size x output_size] containing the generated outputs.
state: The state of each decoder cell at the final time-step.
It is a 2D Tensor of shape [batch_size x cell.state_size].
Raises:
ValueError: When output_projection has the wrong shape.
"""
- 创建
embeding matrix,这个embeding matrix在一个时刻用到了两次 - 创建一个
loop_function,作用根据decoder上一步的output(如果是事先提供了output projection, 那么会在此时计算一下;否则的话,在cell.call的时候就已经算过了),再lookup 一下第一步的embeding matrix,得到一个embeding作为下一步的输入(可以指定这个环节要不要更新embeding matrix,如果更新的话,该矩阵就是更新了两次)。
Luong NMT中是上一步的的
attention vector作为下一步输入;
- 给decoder创建embeding层,封装一下
decoder_inputs,然后调用attention_decoder
tf.contrib.legacy_seq2seq.attention_decoder
def attention_decoder(decoder_inputs,
initial_state,
attention_states,
cell,
output_size=None,
num_heads=1,
loop_function=None,
dtype=None,
scope=None,
initial_state_attention=False):
"""RNN decoder with attention for the sequence-to-sequence model.
In this context "attention" means that, during decoding, the RNN can look up
information in the additional tensor attention_states, and it does this by
focusing on a few entries from the tensor. This model has proven to yield
especially good results in a number of sequence-to-sequence tasks. This
implementation is based on http://arxiv.org/abs/1412.7449 (see below for
details). It is recommended for complex sequence-to-sequence tasks.
Args:
decoder_inputs: A list of 2D Tensors [batch_size x input_size].
initial_state: 2D Tensor [batch_size x cell.state_size].
attention_states: 3D Tensor [batch_size x attn_length x attn_size].
cell: tf.nn.rnn_cell.RNNCell defining the cell function and size.
output_size: Size of the output vectors; if None, we use cell.output_size.
num_heads: Number of attention heads that read from attention_states.
loop_function: If not None, this function will be applied to i-th output
in order to generate i+1-th input, and decoder_inputs will be ignored,
except for the first element ("GO" symbol). This can be used for decoding,
but also for training to emulate http://arxiv.org/abs/1506.03099.
Signature -- loop_function(prev, i) = next
* prev is a 2D Tensor of shape [batch_size x output_size],
* i is an integer, the step number (when advanced control is needed),
* next is a 2D Tensor of shape [batch_size x input_size].
dtype: The dtype to use for the RNN initial state (default: tf.float32).
scope: VariableScope for the created subgraph; default: "attention_decoder".
initial_state_attention: If False (default), initial attentions are zero.
If True, initialize the attentions from the initial state and attention
states -- useful when we wish to resume decoding from a previously
stored decoder state and attention states.
Returns:
A tuple of the form (outputs, state), where:
outputs: A list of the same length as decoder_inputs of 2D Tensors of
shape [batch_size x output_size]. These represent the generated outputs.
Output i is computed from input i (which is either the i-th element
of decoder_inputs or loop_function(output {i-1}, i)) as follows.
First, we run the cell on a combination of the input and previous
attention masks:
cell_output, new_state = cell(linear(input, prev_attn), prev_state).
Then, we calculate new attention masks:
new_attn = softmax(V^T * tanh(W * attention_states + U * new_state))
and then we calculate the output:
output = linear(cell_output, new_attn).
state: The state of each decoder cell the final time-step.
It is a 2D Tensor of shape [batch_size x cell.state_size].
Raises:
ValueError: when num_heads is not positive, there are no inputs, shapes
of attention_states are not set, or input size cannot be inferred
from the input.
"""
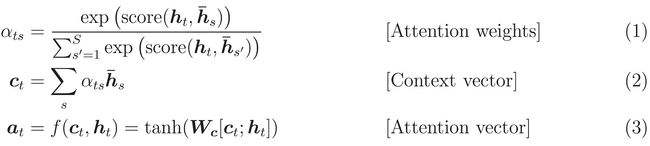
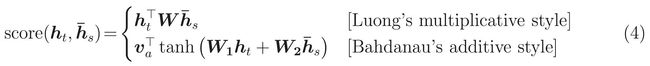
核心公式:
cell\_output, new\_state = cell(linear(input, prev\_attn), prev\_state) \ \ ····· (1)
new\_attn = softmax(V^T * tanh(W * attention\_states + U * new\_state))\ \ ····· (2)
output = linear(cell\_output, new\_attn)\ \ ····· (3)
- 计算
$W*attention\_states$,这里采用了卷积的形式,根据传入的attention_states (batch_size, attn_length, attn_size),reshape成(batch_size, attn_length, 1, attn_size),采用[1,1,1,1]的stride、[1, 1, attn_size, attention_vec_size]的filter,生成(batch_size, attn_length, 1, attention_vec_size)的结果. - 用
Linear()函数计算$U * new\_state$,然后reshape成[batch_size, 1, 1, attention_vec_size]. - 计算
$new\_attn$,也就是attention weights,大小为(batch_size, 1, 1, attn_length) - 把
attention weightsreshape成(batch_size, attn_length,1,1)
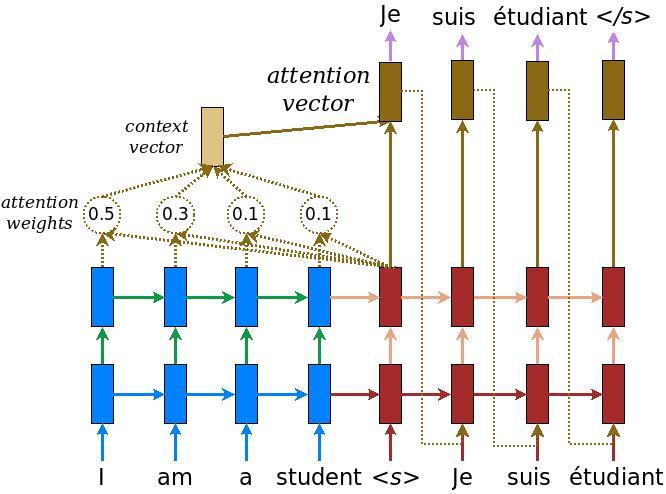 image
image
在tensorflow中,GRU单元的output大小是和state大小一样的,如下所示:
### run.cell.impl.py
### line 435
### class GRUCell(LayerRNNCell):
@property
def state_size(self):
return self._num_units
@property
def output_size(self):
return self._num_units
...
def call(self, inputs, state):
...
return new_h, new_h # 返回的output和state也是同一个
tf.contrib.legacy_seq2seq.model_with_buckets
这个函数,用于构建模型,每个bucket分别构建,所以返回的时候也是按照bucket分开的;计算loss的时候,根据bucket大小,提取出前几个decoder_inputs与encoder_inputs,用对应的seq2seq模型计算出output的结果,最后output(bucket_num 个 tensor([batch_size x num_decoder_symbols]))结果,按照每个bucket,执行softmax_loss_function对应的计算loss的方法,生成每个batch_size*num_decoder_symbols大小的结果(这里num_decoder_symbols表示词表大小,也是输出层维度),先调用传进去的计算loss的方法,得到形如decoder_size* (batch_size,)的list,与对应的decoder_masks(是一个tensor的list,list大小是对应的decoder_size,tensor大小是(batch_size,))(表示每个时刻输出在计算loss的权重)进行内积,得到batch_size*num_decoder_symbols的值,表示该batch中每个训练样本,每个时间节点的误差,进而可以得到一个样本的误差,以及一个batch的平均误差..
self.outputs, self.losses = tf.contrib.legacy_seq2seq.model_with_buckets(
self.encoder_inputs,
self.decoder_inputs,
self.targets,
self.decoder_masks,
config.BUCKETS,
lambda x, y: _seq2seq_f(x, y, False),
softmax_loss_function=self.softmax_loss_function)
源码剖析
def model_with_buckets(encoder_inputs,
decoder_inputs,
targets,
weights,
buckets,
seq2seq,
softmax_loss_function=None,
per_example_loss=False,
name=None):
"""Create a sequence-to-sequence model with support for bucketing.
The seq2seq argument is a function that defines a sequence-to-sequence model,
e.g., seq2seq = lambda x, y: basic_rnn_seq2seq(
x, y, rnn_cell.GRUCell(24))
Args:
encoder_inputs: A list of Tensors to feed the encoder; first seq2seq input.
decoder_inputs: A list of Tensors to feed the decoder; second seq2seq input.
targets: A list of 1D batch-sized int32 Tensors (desired output sequence).
weights: List of 1D batch-sized float-Tensors to weight the targets.
buckets: A list of pairs of (input size, output size) for each bucket.
seq2seq: A sequence-to-sequence model function; it takes 2 input that
agree with encoder_inputs and decoder_inputs, and returns a pair
consisting of outputs and states (as, e.g., basic_rnn_seq2seq).
softmax_loss_function: Function (labels, logits) -> loss-batch
to be used instead of the standard softmax (the default if this is None).
**Note that to avoid confusion, it is required for the function to accept
named arguments.**
per_example_loss: Boolean. If set, the returned loss will be a batch-sized
tensor of losses for each sequence in the batch. If unset, it will be
a scalar with the averaged loss from all examples.
name: Optional name for this operation, defaults to "model_with_buckets".
Returns:
A tuple of the form (outputs, losses), where:
outputs: The outputs for each bucket. Its j'th element consists of a list
of 2D Tensors. The shape of output tensors can be either
[batch_size x output_size] or [batch_size x num_decoder_symbols]
depending on the seq2seq model used.
losses: List of scalar Tensors, representing losses for each bucket, or,
if per_example_loss is set, a list of 1D batch-sized float Tensors.
Raises:
ValueError: If length of encoder_inputs, targets, or weights is smaller
than the largest (last) bucket.
"""
if len(encoder_inputs) < buckets[-1][0]:
raise ValueError("Length of encoder_inputs (%d) must be at least that of la"
"st bucket (%d)." % (len(encoder_inputs), buckets[-1][0]))
if len(targets) < buckets[-1][1]:
raise ValueError("Length of targets (%d) must be at least that of last "
"bucket (%d)." % (len(targets), buckets[-1][1]))
if len(weights) < buckets[-1][1]:
raise ValueError("Length of weights (%d) must be at least that of last "
"bucket (%d)." % (len(weights), buckets[-1][1]))
all_inputs = encoder_inputs + decoder_inputs + targets + weights
losses = []
outputs = []
with ops.name_scope(name, "model_with_buckets", all_inputs):
for j, bucket in enumerate(buckets):
with variable_scope.variable_scope(
variable_scope.get_variable_scope(), reuse=True if j > 0 else None):
bucket_outputs, _ = seq2seq(encoder_inputs[:bucket[0]], # 对应bucket大小作为seq2seq模型输入
decoder_inputs[:bucket[1]])
outputs.append(bucket_outputs)
if per_example_loss:
losses.append(
sequence_loss_by_example(
outputs[-1],
targets[:bucket[1]],
weights[:bucket[1]],
softmax_loss_function=softmax_loss_function))
else:
losses.append(
sequence_loss( # 根据output(logits)计算batch损失
outputs[-1],
targets[:bucket[1]],
weights[:bucket[1]],
softmax_loss_function=softmax_loss_function))
return outputs, losses
def sequence_loss(logits,
targets,
weights,
average_across_timesteps=True,
average_across_batch=True,
softmax_loss_function=None,
name=None):
"""Weighted cross-entropy loss for a sequence of logits, batch-collapsed.
Args:
logits: List of 2D Tensors of shape [batch_size x num_decoder_symbols]. list长度就是max_decoder_size
targets: List of 1D batch-sized int32 Tensors of the same length as logits.
weights: List of 1D batch-sized float-Tensors of the same length as logits.
average_across_timesteps: If set, divide the returned cost by the total
label weight.
average_across_batch: If set, divide the returned cost by the batch size.
softmax_loss_function: Function (labels, logits) -> loss-batch
to be used instead of the standard softmax (the default if this is None).
**Note that to avoid confusion, it is required for the function to accept
named arguments.**
name: Optional name for this operation, defaults to "sequence_loss".
Returns:
A scalar float Tensor: The average log-perplexity per symbol (weighted).
Raises:
ValueError: If len(logits) is different from len(targets) or len(weights).
"""
with ops.name_scope(name, "sequence_loss", logits + targets + weights):
cost = math_ops.reduce_sum(
sequence_loss_by_example(
logits,
targets,
weights,
average_across_timesteps=average_across_timesteps,
softmax_loss_function=softmax_loss_function))
if average_across_batch:
batch_size = array_ops.shape(targets[0])[0]
return cost / math_ops.cast(batch_size, cost.dtype)
else:
return cost
def sequence_loss_by_example(logits,
targets,
weights,
average_across_timesteps=True,
softmax_loss_function=None,
name=None):
"""Weighted cross-entropy loss for a sequence of logits (per example).
Args:
logits: List of 2D Tensors of shape [batch_size x num_decoder_symbols].
targets: List of 1D batch-sized int32 Tensors of the same length as logits.
weights: List of 1D batch-sized float-Tensors of the same length as logits.
average_across_timesteps: If set, divide the returned cost by the total
label weight.
softmax_loss_function: Function (labels, logits) -> loss-batch
to be used instead of the standard softmax (the default if this is None).
**Note that to avoid confusion, it is required for the function to accept
named arguments.**
name: Optional name for this operation, default: "sequence_loss_by_example".
Returns:
1D batch-sized float Tensor: The log-perplexity for each sequence.
Raises:
ValueError: If len(logits) is different from len(targets) or len(weights).
"""
if len(targets) != len(logits) or len(weights) != len(logits):
raise ValueError("Lengths of logits, weights, and targets must be the same "
"%d, %d, %d." % (len(logits), len(weights), len(targets)))
with ops.name_scope(name, "sequence_loss_by_example",
logits + targets + weights):
log_perp_list = []
for logit, target, weight in zip(logits, targets, weights):
if softmax_loss_function is None:
# TODO(irving,ebrevdo): This reshape is needed because
# sequence_loss_by_example is called with scalars sometimes, which
# violates our general scalar strictness policy.
target = array_ops.reshape(target, [-1])
crossent = nn_ops.sparse_softmax_cross_entropy_with_logits(
labels=target, logits=logit)
else:
crossent = softmax_loss_function(labels=target, logits=logit)
log_perp_list.append(crossent * weight) # 哈德曼积,得到 (batch_size,)大小的误差,表示单个时刻误差
log_perps = math_ops.add_n(log_perp_list)
if average_across_timesteps:
total_size = math_ops.add_n(weights)
total_size += 1e-12 # Just to avoid division by 0 for all-0 weights.
log_perps /= total_size
return log_perps
creat_optimizer
对于每个bucket分别创建优化器,这里为了防止梯度爆炸,使用了clip_by_global_norm