上一篇: 数据挖掘:理论与算法笔记1-走进数据科学
下一篇: [数据挖掘:理论与算法笔记3-从贝叶斯到决策树]
(https://www.jianshu.com/p/61e5ea13dfc8)
2. 数据预处理: 抽丝剥茧,去伪存真
2.1 数据清洗
数据缺失有以下几种类型
a. Missing completely at random: 缺失的概率是随机的,比如门店的计数器因为断电断网等原因在某个时段数据为空。
b. Missing conditionally at random: 数据是否缺失取决于另外一个属性,比如一些女生不愿意填写自己的体重。
c. Not missing at random: 数据缺失与自身的值有关,比如高收入的人可能不愿意填写收入。
处理的办法也有几种类型
a. 删数据,如果缺失数据的记录占比比较小,直接把这些记录删掉完事。
b. 手工填补,或者重新收集数据,或者根据domain knowledge来补数据。
c. 自动填补,简单的就是均值填充,或者再加一个概率分布看起来更真实些,也可以结合实际情况通过公式计算,比如门店计数缺失,我们就是参考过往的客流数据,转化数据,缺失时段的销售额,用一个简单公式自动计算回补。
Outlier(离群点)
Outlier在数据挖掘中是一件很麻烦的事情,比如我们收集了一堆身高数据,其中有一个人是姚明,他的身高值就会显得特别突兀。这对某些算法影响很大,比如最小二乘,
2.2 异常值与重复数据监测
局部离群点因子(Local Outlier Factor, LOF)
对比某一点的局部密度和临近区域的密度, A点的局部密度远低于其临近区域的密度,所以A就是一个离群点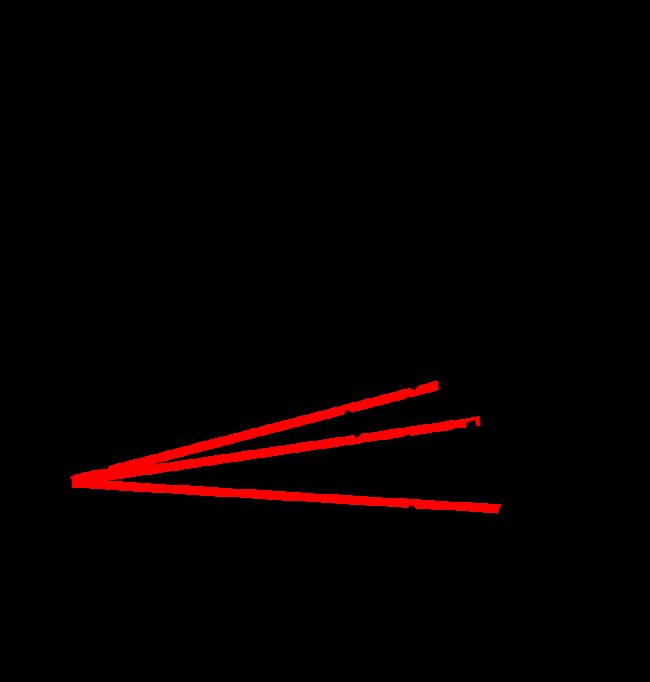
LOF算法逻辑如下:
a. 计算k-distance of A:点A的第k距离,也就距离A第k远的点的距离,不包括A, 记为k-distance(p)
b. 计算k-distance neighborhood of A:点A的第k距离邻域,就是A的第k距离以内的所有点,包括第k距离, 记为Nk(A) [k为下角标]
c. 计算reachability-distance:可达距离,若小于第k距离,则可达距离为第k距离,若大于第k距离,则可达距离为真实距离
d. 计算local reachability density:局部可达密度, 密度越高则可达距离之和越小,而LRD越大

e. 计算local outlier factor: 局部离群因子

Duplicate Records
如果高度疑似的样本是挨着的,就可以用滑动窗口对比,为了让相似记录相邻,可以每条记录生成一个hash key, 根据key去排序。
2.3 类型转换与采样
经过了缺失填充和去重,有了error free的数据集之后还需要做一些转换工作,比如说类型。数据类型有Continues,Discrete,Ordinal(比如优良中差), Nominal(比如职业), Nominal比较特殊,我们用one-hot encoding就好了。
采样
为了解决数据库IO瓶颈,可以通过对数据采样来降低时间复杂度,Aggregation也是减少数据量的一种方式。
大多数机器学习算法假设数据是均匀分布的,实际上经常会遇到不平衡数据集,,此时多数类主导少数类,分类器更偏向于多数类。当数据量足够大的时候应当考虑减少多数类的大小来平衡数据集,这叫欠采样,当数据量不足时应该尝试增加稀有样本数量来平衡数据集,这叫过采样。如果少数类样本实在采集不到了,考虑通过随机过采样算法合成少数类,比如SMOTE(Synthetic Minority Oversampling Technique)
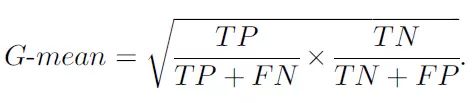
整体准确率不适用与不平衡数据集,需要引入新的度量模式比如G-mean, 它会看正类上的准确率,再看负类上的准确率,然后两者相乘。
另一种度量模式是F-measure, 常见于衡量推荐算法。F-Measure是Precision和Recall加权调和平均:
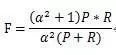
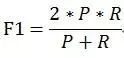
2.4 数据描述与可视化
正则化
因为数据的衡量单位不一,可以用Normalization把数据映射到[0.1]区间,常见的有min-max normalization和z-score normalization.
均值度量
数据的一般性描述有mean, median, mode, variance.
mean是均值,median取数据排序后在中间位置的值,避免因为极端离群点影响客观评价, mode是出现频率最高的元素,其实用的比较少,variance则是衡量数据集与其均值的偏离。
数据相关性
统计学之父Pearson有两个相关系数公式
Pearson correlation coefficient如下:

r是一个-1到1之间的值,r>0则正相关,r<0则负相关, 注意r=0严格意义也不能说不相关,只能说非线性相关。
Pearson chi-square公式如下:

这两公式都是计算相关性的,显然前者适用与有metric data的情况,后者适用于分类统计的情况。
可视化
一维数据圆饼图,柱状图;二维数据散点图;三维数据用三维坐标呈现;高维数据需要先做转换或映射,比如用matlab的Box Plots,也可以用平行坐标呈现。最后介绍了两个软件
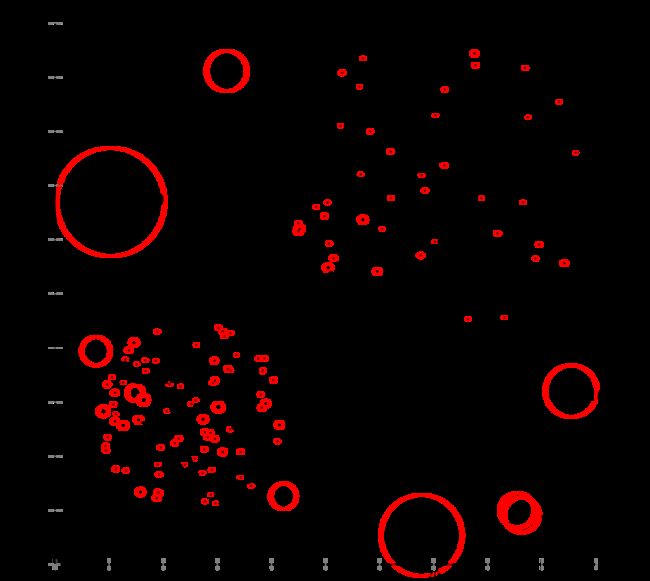
CiteSpace(呈现文章引用情况), Gephi可以把元素之间关系用网络形式展现(如社交关系),下图为Gephi生成:
要对Gephi了解更多可以看底部reference中知乎的一篇文章。
2.5 特征选择
这节开始介绍Feature Selection和Feature Extraction两个核心算法
当我们做特定分析的时候,可能属性非常多,但有些属性是不相关的,有些属性是重复的,所以我们需要用Feature Selection挑选出来最相关的属性降低问题难度。
熵增益(Entropy Information Gain)
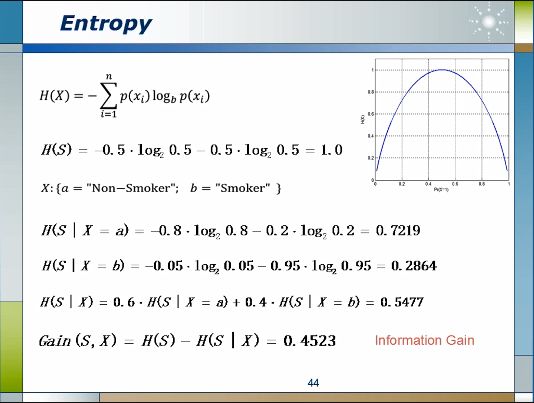
假设我们遇到的特定问题是要猜测某个人的性别,男女比例的概率各一半,如果没有任何额外信息我们随机猜测的结果只能是五五分。再假设有60%的人不抽烟,40%的人是烟民,而且抽烟的人95%是男人,5%是女人,不抽烟的人当中80%是女人,20%是男人。知道一个是否抽烟以后再判断他/她的性别就有把握多了。
此处引入熵(Entropy)的概率来衡量系统的不确定性,下图第一行是计算熵的公式,如果不知道是否抽烟的信息,则熵值为1,即不确定性最高。然后分别计算出不抽烟人群的熵值为0.7219,抽烟人群的熵值为0.2864,整体熵值为0.5477, 1-0.5477=0.4523, 这个数字就是信息增量(Information Gain)
Branch and Bound(分支定界)
如果我们想从n个属性中挑选出m个最优属性,需要注意算法复杂度会随n的增长呈现指数级爆炸增长,计算量会变得非常大,为了降低复杂度这里引入了分支定界的剪枝算法。比如我们要从5个属性中挑选出两个相关性最强的属性,可以先画一个top-down的搜索树,每当往下推一层就减少一个属性,根据属性的单调性假设,属性越少效能越低,所以如果发现节点(1,3,4,5)小于左边某个只有两个属性的节点(2,3)的效能,则可以忽略节点(1,3,4,5)下面的计算,把这一整支都直接删除,从而减少计算量。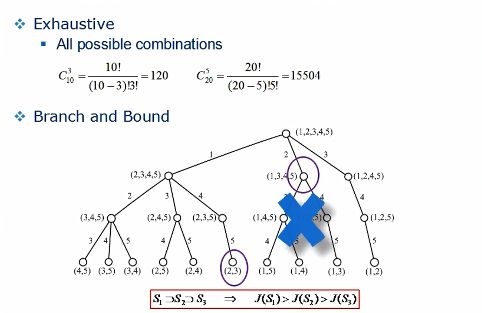
特征选择还有sequential forward, sequential backward, simulated annealing(模拟退火), tabu search(竞技搜索), genetic algorithms(遗传算法)等方式去优化。
2.6 主成分分析
这一节讲Feature Extraction, 图像深度识别提取edge就属于Feature Extraction.
Principal Component Analysis(主成分分析)
PCA又是Pearson最早提出的,主要目的是降维,分析主成分提取最大的个体差异变量,削减回归分析和聚类分析中变量的数目,方式是通过正交变换将一系列可能线性相关的变量转换为一组线性不相关的新变量。
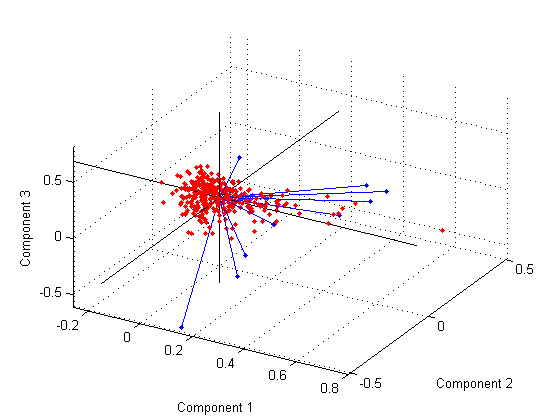
我们先看一个二维图像的例子,左边是原始数据,横轴和纵轴可以当作高和宽,经过转换,实际是把坐标顺时针转动了45度,这样一来纵轴的差异就很小了, 这需要一点线性代数知识来生成转置矩阵。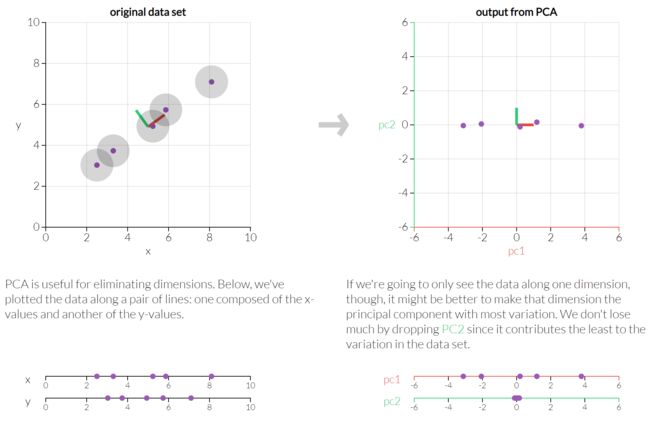
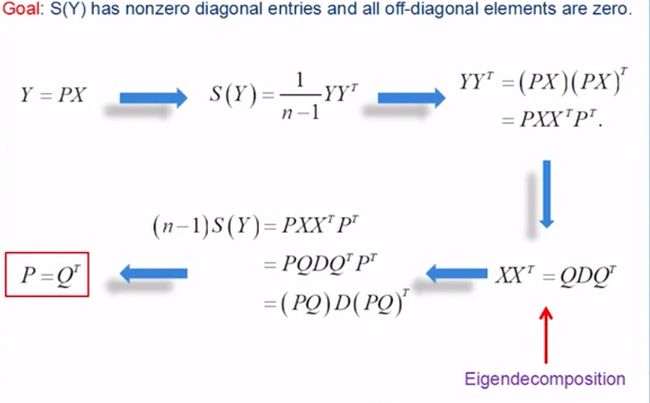
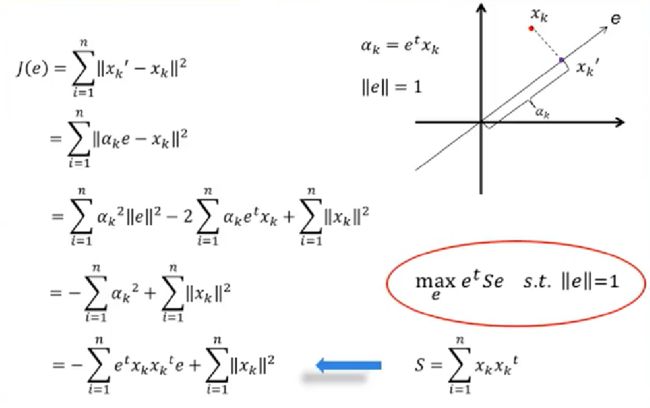
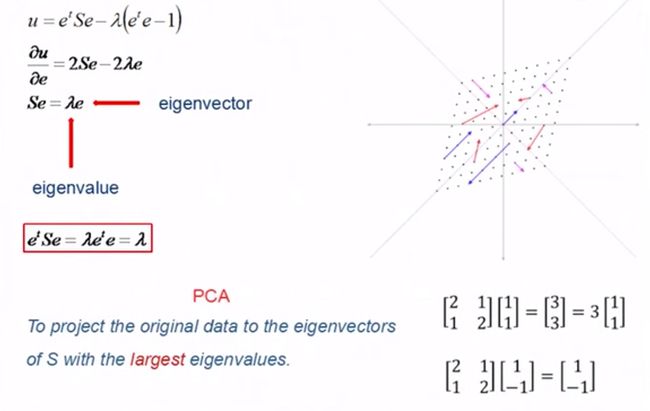
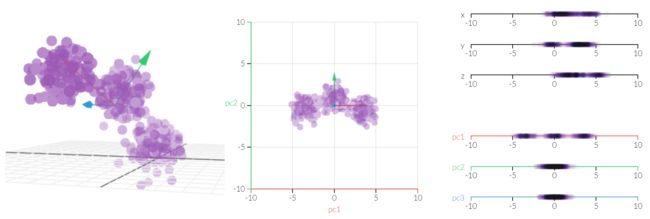
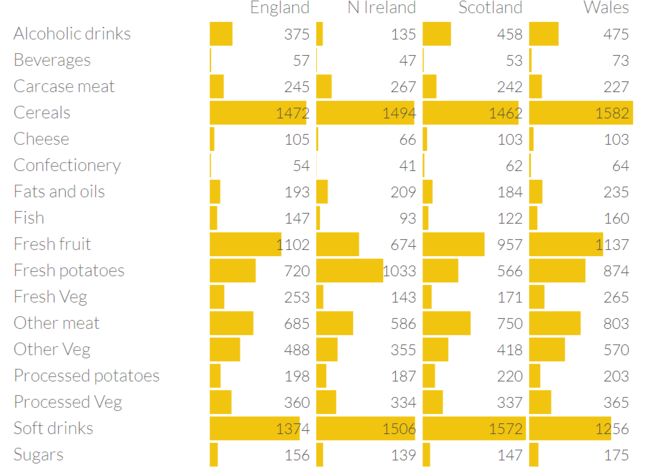
经过PCA转换后会发现北爱尔兰是个离群点

看回前面的表确实北爱尔兰人吃更多fresh patatoes, 但是少消耗很多fresh fruits, cheese, fish and alcoholic drinks 想像一下,不管多少维空间,我们可以用一根投影轴线插进去,让空间中的每个点与这个线上某个点的距离的平方和最小,线上的这个点就是高维空间的投影了。
2.7 线性判别分析
PCA属于非监督学习,不考虑class information, 如果是有标签的数据我们就要用LDA了, 它能够保留区分信息。
Linear Discriminant Analysis
LDA的原理是,将带上标签的数据(点),通过投影的方法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近。虽然也是降维,但好的LDA算法对不同类别是有明显的区分度的。
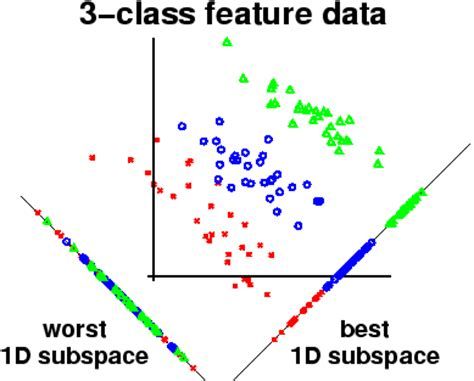
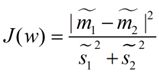
具体的推导我就偷懒省去了,有兴趣的可以看底部reference中的链接。
上一篇: 数据挖掘:理论与算法笔记1-走进数据科学
下一篇: [数据挖掘:理论与算法笔记3-从贝叶斯到决策树]
(https://www.jianshu.com/p/61e5ea13dfc8)
references:
机器学习-异常检测算法(二):Local Outlier Factor
局部异常因子算法-LOF
Local outlier factor
Fast Branch & Bound Algorithm in Feature Selection
Principal Component AnalysisExplained Visually
降维算法二:LDA(Linear Discriminant Analysis)
介绍用Gephi进行数据可视化