redis的基础数据结构
1.String
常见命令:set get incry decr
2. hash
常见命令:hmset hmget hkeys
3. set(集合)
常见命令:sadd smembers
4. list
常见命令:lpush lpop
5. zset (有序集合)
常见命令:zadd
zcard (获取有序集合的成员数)
zremrangebyscore (命令用于移除有序集中,指定分数(score)区间内的所有成员)
zrange (通过索引区间返回有序集合指定区间内的成员)
6.HyperLogLog
作用:是用来做基数统计的算法,每个key只需要花费 12 KB 内存 标准误差在0.81%
常见命令;pfadd pfcount
使用场合:用于统计UV 和PV
7.GeoHash
简单介绍:如果利用数据库来算"附近的人"?如果使用关系型数据库,如何存储?大家都用过摩拜单车 ,就会查看附近的车辆。Redis 提供了Geo 指令 一共有6个
常见命令:
geoadd 指令携带集合名称和经纬度以及三元组
geoadd company 118.2901 39.0909 alibaba
geoadd company 209.2102 39.9028 jd
geolist 指令计算两个元素之间的距离,携带集合名称,距离单位。
geolist company alibaba jd km
geohash 获取元素的hash 值
geohash company jd 返回的是base32位编码。
georadiusbymember 指令用来查询指定元素附近其他的元素。
georadiusbymember company jd km count 3 asc 范围20公里以内最多3个元素按照距离正序排列。
8.布隆过滤器
应用场景:我们在使用新闻客户端看新闻时,他会给我们推荐新的内容,他每次推荐都会去重,去掉那些看过的内容。如果历史记录存再关系型数据库里,需要频繁的exists查询,当系统并发量很高时,数据库是很难抗拒压力的。
常见命令:bf.add bf.exists (bf.madd和bf.mexists)
缺点:不是特别精确,会误判,也不是特别不准确,只要参数设置合理,它的准确的可以很高。
9.位图
开发场景:平时开发中,我们都需要对一些bool 类型的数据进行存取,比如用户一年签到的数据。签了为1 没签到就是0 。如果有普通的key/value 那么当用户上亿 需要的存储空间 是惊人的。
为了解决这个问题我们可以使用redis提供的位图这种数据结构。每个签到就占一个位,365天就365个位。
常用命令:getbit setbit bitcount bitpop bitfield
Key的格式为u:sign:uid:yyyyMM
# 用户2月17号签到
setbit u:sign:1234:201802 16 1 # 偏移量是从0开始,所以要把17减1
# 检查2月17号是否签到
getbit u:sign:1234:201802 16
# 统计2月份的签到次数
bitcount u:sign:1000:201902
获取2月份前28天的签到数据
bitfield u:sign:1000:201902 get u28 0
# 获取2月份首次签到的日期
bitpos u:sign:1000:201902 0 # 返回的首次签到的偏移量,加上1即为当月的某一天
redis的分布式锁
redis除了上述 应用 还可以用于做分布式锁。举个栗子
redis中缓存了一个int值 现在有两个客户端需要同时读取这个数,然后+20,次数就会出现并发问题 如下图
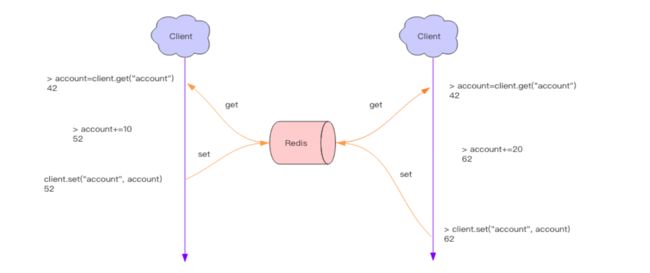
redis的分布式锁 其实就是占坑,当别的进程进来的时候,发现已经有人了,那么就会放弃或者稍后再试。
命令
setnx //命令
setnx lock:user:123 true
do something
del lock:user:123
那么就会出现问题,如果do something 出现异常了,锁就没有释放,这样就会永远陷入死锁,永远不会释放。
解决方案1. 给锁设置失效时间
setnx lock:user:123 true
expire lock:user:123 5
//do something
del lock:user:123
此时也会有问题 ,如果在加锁和设置锁超时之间服务器挂掉了,那么锁也不会得到释放,究其原因是因为:加锁和设置时间不是原子指令。如果这两条指令一起执行就不会有问题。
redis2.8 版本以上加入了set 指令的扩展,是的setnx 和expire一起执行,
set lock:user:123 true ex 5 nx ok
//do something
del lock:user:123
缺陷:
1.不能解决超时问题:如果加锁或者释放锁的执行时间过长,超出了锁的时间限制,就会出现问题。
利用redis做简单限流:
案例:如果有几片文章,我们限制这个用户几分钟内只能回复几次,就可以用redis来做简单限制
方案:我们使用zset 结构,score为时间戳,value唯一就行。可以把zset中的score看做一个窗口 ,我们只维护窗口以内的数据。
/**
userId:用户编号
userAction:用户事件,比如点赞,回复评论。
provit:限制事件,单位为秒
maxcount:次数
**/
public boolean isAllowAction(int userId,String userAction,int provit,int maxCount) throws IOException {
String key = String.format("userAction:%d:%d",userId,userAction);
Jedis jedis = new Jedis();
long systemTime = System.currentTimeMillis();
Pipeline pipeline = jedis.pipelined();
pipeline.multi();
pipeline.zadd(key,systemTime,systemTime+"");
pipeline.zremrangeByScore(key,0,systemTime - provit * 1000);
Response userAccount = pipeline.scard(key);
pipeline.expire(key,provit+1);
pipeline.exec();
pipeline.close();
return userAccount.get() > maxCount;
}
如何查询redis中的某个Key呢?
1.简单暴力用keys 和正则表达式 keys * ;如果redis中有成千上百万的key 这样会不会太慢了?而且keys 命令是遍历所有的Keys,如果在线上环境,使用改命令,则会造成redis卡顿,redis 为单线程。keys 命令的时间复杂度为O(n).
2.使用Scan命令 同keys 一样 他也提供了匹配的功能,提供了limit参数 返回结果可多可少。
命令:scan 0 match user_* count 1000; 一共有三个参数,第一个是cursor 整数值,第二个key则为正则表达式,第三个则为limit him (limit 1000 不是限定返回结果的数量,而是限定单次服务器遍历的字典槽位数量)