
框架总览
背景及现状
前端工程的2个阶段
- 库/框架
- 构建工具
如何做前端工程化
- 模块化
- 组件化
- 规范化
- 自动化
npm的基本使用和总结
- npm 是什么?
- npm常用命令
- package.json详解
- npm2和npm2以上版本的原理和区别
- 自己封装一个npm包
cli功能设计
总结
1. 背景及现状
从本质上讲,所有Web应用,都是一种运行在网页浏览器中的软件,这些软件的图形用户界面(Graphical User Interface,简称GUI)即为前端。
如此复杂的Web应用,动辄几十上百人共同开发维护,其前端界面通常也颇具规模,工程量不亚于一般的传统GUI软件:
我们希望能在日常开发中制订一个规范化的前端工作流,很好地规范统一项目的模块化开发和前端资源,让代码的维护和互相协作更加容易更加方便,令前端开发自动化成为一种习惯。同时,让大家能够释放生产力,提高开发效率,更好更快地完成团队开发以及项目后期维护和扩展。
前端工程本质上是软件工程的一种。软件工程化关注的是性能、稳定性、可用性、可维护性等方面,注重基本的开发效率、运行效率的同时,思考维护效率。一切以这些为目标的工作都是"前端工程化"。工程化是一种思想而不是某种技术。
2.框架和构建工具的选型
现在的前端开发倒也并非一无所有,回顾一下曾经经历过或听闻过的项目,为了提升其前端开发效率和运行性能,前端团队的工程建设大致会经历三个阶段:
2.1 库/框架选型

前端工程建设的第一项任务就是根据项目特征进行技术选型。
基本上现在没有人完全从0开始做网站,React/Vue/Angularjs等框架横空出世,解放了不少生产力,合理的技术选型可以为项目节省许多工程量这点毋庸置疑。
2.1.1 框架产生的背景:
Augular:用于构建清晰简洁的动态 web 应用。
React: 引入虚拟 dom 解决需要大量 dom 操作的复杂页面的性能问题。
Vue: 引入虚拟DOM、双向数据绑定、指令解析等,借鉴了Augular和React的优点。
2.1.2 如下几个点来考虑选择何种框架:
- 是否能更好的解决业务中的问题
- 是否要轻量(React 比 vue 大,vue 更适合轻量级应用,比如活动页)
- 是否要简单
- 是否需要动画
- 是否需要组件化
- 页面是否复杂(Vue 性能比 React 更快)
- 是否需要双向绑定
2.2 构建工具

2.2.1 构建工具是什么
构建工具的主要功能就是实现自动化处理,例如对代码进行检查、预编译、合并、压缩;生成雪碧图、sourceMap、版本管理;运行单元测试、监控等,当然有的工具还提供模块化、组件化的开发流程功能。
网上各类的构建工具非常多,有家喻户晓的 Grunt、Gulp、Webpack,也有各大公司团队开源的构建工具,这里通过 Github 的 Star 数量来简单的对比下各个工具的流行度:
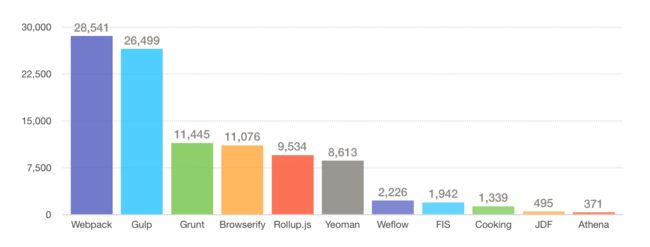
如果把工具按类型分可以分为这三类:
基于任务运行的工具:
Grunt、Gulp
它们会自动执行指定的任务,就像流水线,把资源放上去然后通过不同插件进行加工,它们包含活跃的社区,丰富的插件,能方便的打造各种工作流。基于模块化打包的工具:
Browserify、Webpack、rollup.js
有过 Node.js 开发经历的应该对模块很熟悉,需要引用组件直接一个require就 OK,这类工具就是这个模式,还可以实现按需加载、异步加载模块。整合型工具:
Yeoman、FIS、jdf、Athena、cooking、weflow
使用了多种技术栈实现的脚手架工具,好处是即开即用,缺点就是它们约束了技术选型,并且学习成本相对较高。
2.2.2 构建工具选型
在做选型的时候,我们往往会考虑以下几个因素:
- 是否符合团队的技术栈
- 是否符合项目需求
- 生态圈是否完善、社区是否活跃
还是排除 1、2 主观的因素,我们在不同类型的工具中选择几个热门(满足因素3),也就是:Grunt、Gulp、Webpack、Yeoman 看看它们的工作流、优劣点以及适用场景。
1、Grunt & Gulp
工作流:
这两款工具都是基于任务类型,所以它们的工作流是一致的:
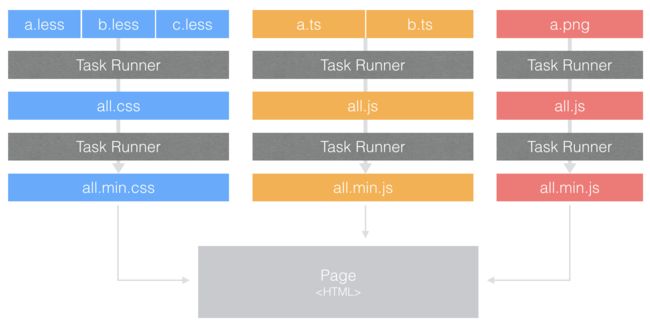
可以看到它们打包的策略通常是 All in one,最后页面还是引用 css、img、js,开发流程与徒手开发相比并无差异。
特点与不足
Grunt
Grunt 是老牌的构建工具,特点是配置驱动,你需要做的就是了解各种插件的功能,然后把配置整合到 Gruntfile.js 中,可以看下面的配置例子,简单直接:
module.exports = function(grunt) {
grunt.initConfig({
jshint: {
files: ['Gruntfile.js', 'src/**/*.js', 'test/**/*.js'],
options: {
globals: {
jQuery: true
}
}
},
watch: {
files: ['<%= jshint.files %>'],
tasks: ['jshint']
}
});
grunt.loadNpmTasks('grunt-contrib-jshint');
grunt.loadNpmTasks('grunt-contrib-watch');
grunt.registerTask('default', ['jshint']);
};
Grunt 缺点也是配置驱动,当任务非常多的情况下,试图用配置完成所有事简直就是个灾难;再就是它的 I/O 操作也是个弊病,它的每一次任务都需要从磁盘中读取文件,处理完后再写入到磁盘,例如:我想对多个 less 进行预编译、压缩操作,那么 Grunt 的操作就是:
读取 less 文件 -> 编译成 css -> 存储到磁盘 -> 读取 css -> 压缩处理 -> 存储到磁盘
这样一来当资源文件较多,任务较复杂的时候性能就是个问题了。
Gulp
Gulp 特点是代码驱动,写任务就和写普通的 Node.js 代码一样:
var gulp = require('gulp');
var pug = require('gulp-pug');
var less = require('gulp-less');
var minifyCSS = require('gulp-csso');
gulp.task('html', function(){
return gulp.src('client/templates/*.pug')
.pipe(pug())
.pipe(gulp.dest('build/html'))
});
gulp.task('css', function(){
return gulp.src('client/templates/*.less')
.pipe(less())
.pipe(minifyCSS())
.pipe(gulp.dest('build/css'))
});
gulp.task('default', [ 'html', 'css' ]);
再一个对文件读取是流式操作(Stream),也就是说一次 I/O 可以处理多个任务,还是 less 的例子,Gulp 的流程就是:
读取 less 文件 -> 编译成 css -> 压缩处理 -> 存储到磁盘
Gulp 作为任务类型的工具没有明显的缺点,唯一的问题可能就是完成相同的任务它需要写的代码更多一些,所以除非是项目有历史包袱(原有项目就是基于 Grunt 构建)在 Grunt 与 Gulp 对比看来还是比较推荐 Gulp!
适用场景:
通过上面的介绍可以看出它们侧重对整个过程的控制管理,实现简单、对架构无要求、不改变开发模式,所以非常适合前端、小型、需要快速启动的项目。
Webpack
Webpack 是目前最热门的前端资源模块化管理和打包工具,还是先通过一张图大致了解它的运行方式:
工作流
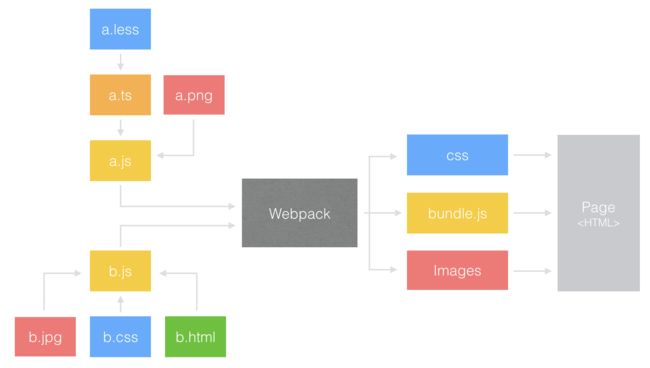
特点与不足
Webpack 的特点:
- 把一切都视为模块:不管是 CSS、JS、Image 还是 HTML 都可以互相引用,通过定义 entry.js,对所有依赖的文件进行跟踪,将各个模块通过 loader 和 plugins 处理,然后打包在一起。
- 按需加载:打包过程中 Webpack 通过 Code Splitting 功能将文件分为多个 chunks,还可以将重复的部分单独提取出来作为 commonChunk,从而实现按需加载。
Webpack 也是通过配置来实现管理,与 Grunt 不同的时,它包含的许多自动化的黑盒操作所以配置起来会简单很多(但遇到问题调试起来就很麻烦),一个典型的配置如下:
module.exports = {
//插件项
plugins: [commonsPlugin],
//页面入口文件配置
entry: {
index : './src/js/page/index.js'
},
//入口文件输出配置
output: {
path: 'dist/js/page',
filename: '[name].js'
},
module: {
//加载器配置
loaders: [
{ test: /\.css$/, loader: 'style-loader!css-loader' },
{ test: /\.js$/, loader: 'jsx-loader?harmony' },
{ test: /\.scss$/, loader: 'style!css!sass?sourceMap'},
{ test: /\.(png|jpg)$/, loader: 'url-loader?limit=8192'}
]
},
//其它解决方案配置
resolve: {
root: '/Users/Bell/github/flux-example/src', //绝对路径
extensions: ['', '.js', '.json', '.scss'],
alias: {
AppStore : 'js/stores/AppStores.js',
ActionType : 'js/actions/ActionType.js',
AppAction : 'js/actions/AppAction.js'
}
}
};
Webpack 的不足:
- 上手比较难:官方文档混乱、配置复杂、难以调试(Webpack2 已经好了很多)对于新手而言需要经历踩坑的过程;
- 对于 Server 端渲染的多页应用有点力不从心:Webpack 的最初设计就是针对 SPA,所以在处理 Server 端渲染的多页应用时,不管你如何 chunk,总不能真正达到按需加载的地步,往往要去考虑如何提取公共文件才能达到最优状态。
模块化与组件化
提到 Webpack 就不得不说它的模块化加载方式,先来看下传统的模块化方式:
├── scripts/
│ ├── dropdown.js
│ ├── lazyload.js
│ ├── modal.js
│ └── slider.js
├── styles/
│ ├── button.less
│ ├── list.less
│ ├── modal.less
│ └── slider.less
传统的模块化基于单种编程语言,目的是为了解耦和重用,而因为前端本身的特点(需要三种编程语言配合)以及能力限制,所以不能实现跨资源加载也就难以实现组件化。
而 Webpack 打破的这种思维局限,它的 Require anything 的理念在实现模块化的同时也能够很方便实现组件化,借助 Webpack 就可以很轻松的实现这种代码组织结构:
├──components/
│ ├── button/
│ │ ├── button.js
│ │ ├── button.less
│ │ ├── dropdwon.js
│ │ └── icon.png
│ ├── modal/
│ ├── slider/
一旦实现组件化,那么我们的项目开发方式和分工合作方式就可以升级,可以实现分组件并行开发,也可以方便的引用其它项目使用的组件。
适用场景:
综上所述,Webpack 特别适合配合 React.js、Vue.js 构建单页面应用以及需要多人合作的大型项目,在规范流程都已约定好的情况下往往能极大的提升开发效率与开发体验。
然而,做到这些就够了么?前端工程化才刚刚开始!
如何做前端工程化
前面讲的2个阶段虽然相比曾经“茹毛饮血”的时代进步不少,但用于支撑第的多人合作开发以及精细的性能优化似乎还欠缺点什么。
到底,缺什么呢?
前端工程化就是为了让前端开发能够“自成体系”,个人认为主要应该从模块化、组件化、规范化、自动化四个方面思考。
1.模块化
简单来说,模块化就是将一个大文件拆分成相互依赖的小文件,再进行统一的拼装和加载。

-
JS的模块化
在ES6之前,JavaScript一直没有模块系统,这对开发大型复杂的前端工程造成了巨大的障碍。对此社区制定了一些模块加载方案,如CommonJS、AMD和CMD等。
现在ES6已经在语言层面上规定了模块系统- export和import。一个文件就是一个模块。在文件中定义的变量,函数,对象在外部是无法获取的。如果你希望外部可以读取模块当中的内容,就必须使用export来对其进行暴露(输出)以import的形式引入变量。这种方式完全可以取代现有的CommonJS和AMD规范,而且使用起来相当简洁,并且有静态加载的特性。
关于ES6 的模块系统,参考3篇比较有代表性的文章:
- es6模块 import, export 知识点小结](https://zhuanlan.zhihu.com/p/57565371)
- es6中的模块化
- ES6 Module之export 解读
-
css的模块化
先来回顾一下在日常编写CSS代码时都有哪些痛点:
全局污染 - CSS的选择器是全局生效的,所以在class名称比较简单时,容易引起全局选择器冲突,导致样式互相影响。
命名混乱 - 因为怕全局污染,所以日常起class名称时会尽量加长,这样不容易重复,但当项目由多人维护时,很容易导致命名风格不统一。
样式重用困难 - 有时虽然知道项目上已有一些相似的样式,但因为怕互相影响,不敢重用。
代码冗余 - 由于样式重用的困难性等问题,导致代码冗余。
A CSS Module is a CSS file in which all class names and animation names are scoped locally by default. CSS模块就是所有的类名都只有局部作用域的CSS文件。
目前css模块化用的比较多的有2种方法:
1. css BEM
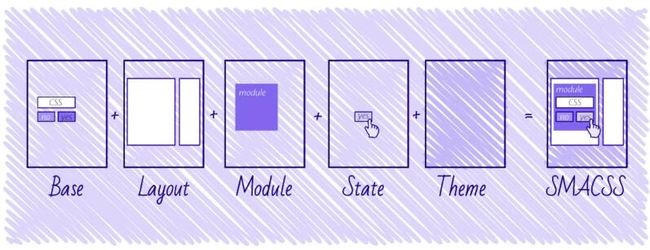
BEM 分别代表着:Block(块)、Element(元素)、Modifier(修饰符),是一种组件化的 CSS 命名方法和规范,由俄罗斯 Yandex 团队所提出。其目的是将用户界面划分成独立的(模)块,使开发更为简单和快速,利于团队协作开发。
block 代表了更高级别的抽象或组件
block__element 代表 block 的后代,用于形成一个完整的 block 的整体
block--modifier代表 block 的不同状态或不同版本
为什么使用BEM?
1.性能
CSS引擎查找样式表,对每条规则都按从右到左的顺序去匹配
以下这段代码看起来很快,实际上很慢。
通常我们会认为浏览器是这样工作的:找到唯一ID元素ul-id —> 把样式应用到li元素上。
事实上: 从右到左进行匹配,遍历页面上每个li元素并确定其父元素
ul-id li {}
所以不要让你的css超过三层
2.语义化
看以下例子是否一目了然。
.person{} /*人*/
.person-hand{} /*人的手*/
.person-female{} /*女人*/
.person-female-hand{} /*女人的手*/
.person-hand-left{} /*人的左手*/
- 规则
- 块名需能清晰的表达出,其用途、功能或意义,具有唯一性。
- 块名称之间用-连接。
- 每个块名前应增加一个前缀,这前缀在 CSS 中有命名空间(如:m-、u-、分别代表:mod 模块、ui 元件)。
- 每个块在逻辑上和功能上都相互独立。
- 由于块是独立的,可以在应用开发中进行复用,从而降低代码重复并提高开发效率。
- 块可以放置在页面上的任何位置,也可以互相嵌套。
- 同类型的块,在显示上可能会有一定的差异,所以不要定义过多的外观显示样式,主要负责结构的呈现。
这样就能确保块在不同地方复用和嵌套时,增加其扩展性。
综上所述,最终我们可以把BEM规则最终定义成:
.[命名空间]-[组件名/块]-[元素名/元素]-[修饰符]
常见的命名空间有:
基础公共:base
容器: container
布局:layout
页头:header
内容:content/container
页面主体:main
页尾:footer
导航:nav
侧栏:sidebar
栏目:column
页面外围控制整体佈局宽度:wrapper
2. CSS modules

CSS的规则都是全局的,尽管每一个组件的样式都是通过import引入的,但是任何一个组件的样式规则,并非模块化。而是都对整个页面有效。
产生局部作用域的唯一方法,就是使用一个独一无二的class的名字,不会与其他选择器重名。这就是 CSS Modules 的做法。
以React为例:
React-create-app 2X以下,脚手架没有集成css module,需要自己手动配置webpack.
{
test: /\.scss$/,
use: ExtractTextPlugin.extract({
fallback: {
loader: 'style-loader',
options: {
insertAt: 'top'
}
},
use: [
{
loader: 'typings-for-css-modules-loader',
options: {
modules: true,
namedExport: true,
camelCase: true,
minimize: true,
localIdentName: "[local]_[hash:base64:5]"
}
},
{
loader: 'sass-loader',
options: {
outputStyle: 'expanded',
sourceMap: true
}
}
]
})
},
如果开发语言 不是ts的话,不需要安装typings-for-css-modules-loader,如果没有使用scss的话,也不需要安装sass-loader。只需安装css-loader和style-loader 即可。配置如下:
{
test: /\.css$/,
loader: "style-loader!css-loader?modules"
},
webpack配置结束了,那么React组件中如何使用?
下面是一个React组件App.js。
import React from 'react';
import * as style from './App.scss';
export default () => {
return (
Hello World
);
};
上面代码中,我们将样式文件App.scss输入到style对象,然后引用style.title代表一个class。
.title {
color: red;
}
构建工具会将类名style.title编译成一个哈希字符串。
Hello World
App.css也会同时被编译。
.App-DBWEL {
color: red;
}
这样一来,这个类名就变成独一无二了,只对App组件有效。操作详情可以参考CSS Modules 用法教程
网络上关于react 中使用css modules教程大都以react-create-app 2X及以下版本为例。在2X以上的版本不适用。大家开发过程中需要注意。2x以上的版本已经被集成到React-create-app中。以React-create-app 3.3.0+Typescript+css-loader 1.0.0为例。不需要添加webpack loader了。只需要修改即可,如下:
// 默认支持css Modules,只需讲css文件名改成.module.css结尾就可以。如果没有使用css请将该配置注释掉
{
test: cssRegex,
exclude: cssModuleRegex,
use: getStyleLoaders({
importLoaders: 1,
sourceMap: isEnvProduction && shouldUseSourceMap,
}),
sideEffects: true,
},
// using the extension .module.css
{
test: cssModuleRegex,
use: getStyleLoaders({
importLoaders: 1,
sourceMap: isEnvProduction && shouldUseSourceMap,
// 注意这里要改,之前是modules:{getLocalIdent: getCSSModuleLocalIdent},没有modules: true,
modules: true,
getLocalIdent: getCSSModuleLocalIdent
}),
},
// 同时支持css Modules,只需讲css文件名改成.module.scss或者.module.sass结尾就可以。如果没有使用scss请将该配置注释掉
{
test: sassRegex,
exclude: sassModuleRegex,
use: getStyleLoaders({
importLoaders: 2,
sourceMap: isEnvProduction && shouldUseSourceMap,
},
'sass-loader'
),
sideEffects: true,
},
{
test: sassModuleRegex,
use: getStyleLoaders({
importLoaders: 2,
sourceMap: isEnvProduction && shouldUseSourceMap,
// 注意这里要改,之前是modules:{getLocalIdent: getCSSModuleLocalIdent},没有modules: true,
modules: true,
getLocalIdent: getCSSModuleLocalIdent,
},
'sass-loader'
),
},
}
-
资源的模块化
Webpack的强大之处不仅仅在于它统一了JS的各种模块系统,取代了Browserify、RequireJS、SeaJS的工作。更重要的是它的万能模块加载理念,即所有的资源都可以且也应该模块化。如下图:
我们可以将使用的资源进行分类,公共代码放到scripts中,项目中使用的图标放到icons中,用到的图片放到images中。公共样式放到css文件中。由webpack统一进行打包。
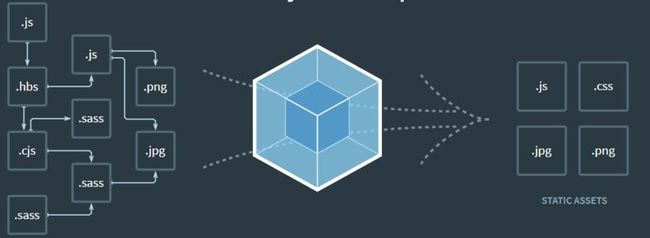
资源模块化后,优点是:
- 依赖关系单一化。所有CSS和图片等资源的依赖关系统一走JS路线,无需额外处理CSS预处理器的依赖关系,也不需处理代码迁移时的图片合并、字体图片等路径问题;
- 资源处理集成化。现在可以用loader对各种资源做各种事情,比如复杂的vue-loader等等;
- 项目结构清晰化。使用Webpack后,你的项目结构总可以表示成这样的函数: dest = webpack(src, config)。
组件化
组件化实际上是一种按照模板(HTML)+样式(CSS)+逻辑(JS)三位一体的形式对面向对象的进一步抽象。
组件化≠模块化。模块化只是在文件层面上,对代码或资源的拆分;而组件化是在设计层面上,对UI(用户界面)的拆分。组件化更重要是一种分治思想。
分治的确是非常重要的工程优化手段。在我看来,前端作为一种GUI软件,光有JS/CSS的模块化还不够,对于UI组件的分治也有着同样迫切的需求:
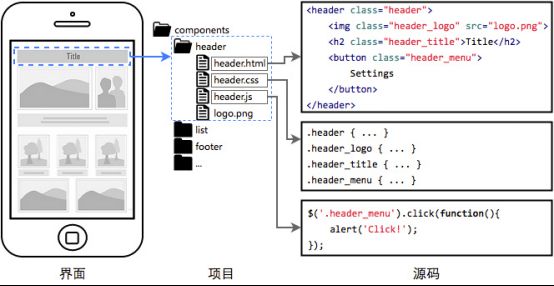
如上图,这是我所信仰的前端组件化开发理念,简单解读一下:
1. 页面上的每个独立的可视/可交互区域视为一个组件;
2. 每个组件对应一个工程目录,组件所需的各种资源都在这个目录下就近维护;
3. 由于组件具有独立性,因此组件与组件之间可以 自由组合;
4. 页面只不过是组件的容器,负责组合组件形成功能完整的界面;
5. 当不需要某个组件,或者想要替换组件时,可以整个目录删除/替换。
其中第二项描述的就近维护原则,是最具工程价值的地方,它为前端开发提供了很好的分治策略,每个开发者都将清楚的知道,自己所开发维护的功能单元,其代码必然存在于对应的组件目录中,在那个目录下能找到有关这个功能单元的所有内部逻辑,样式也好,JS也好,页面结构也好,都在那里。
组件化开发具有较高的通用性,无论是前端渲染的单页面应用,还是后端模板渲染的多页面应用,组件化开发的概念都能适用。组件HTML部分根据业务选型的不同,可以是静态的HTML文件,可以是前端模板,也可以是后端模板:

不同的技术选型决定了不同的组件封装和调用策略。
基于这样的工程理念,我们很容易将系统以独立的组件为单元进行分工划分:

由于系统功能被分治到独立的模块或组件中,粒度比较精细,组织形式松散,开发者之间不会产生开发时序的依赖,大幅提升并行的开发效率,理论上允许随时加入新成员认领组件开发或维护工作,也更容易支持多个团队共同维护一个大型站点的开发。
结合前面提到的模块化开发,整个前端项目可以划分为这么几种开发概念:
| 名称 | 说明 | 举例 |
|---|---|---|
| JS模块 | 独立的算法和数据单元 | 浏览器环境检测(detect),网络请求(ajax),应用配置(config),DOM操作(dom),工具函数(utils),以及组件里的JS单元 |
| CSS模块 | 独立的功能性样式单元 | reset样式,栅格系统(grid),字体图标(icon-fonts),动画样式(animate),以及组件里的CSS单元 |
| UI组件 | 独立的可视/可交互功能单元 | 页头(header),页尾(footer),导航栏(nav),搜索框(search) |
| 页面 | 前端这种GUI软件的界面状态,是UI组件的容器 | 首页(index),列表页(list),用户管理(user) |
| 应用 | 整个项目或整个站点被称之为应用,由多个页面组成,甚至由多个应用或者系统组成 | SPA(单一页面应用)、PWA(渐进式Web应用)、微前端 |
以上5种开发概念以相对较少的规则组成了前端开发的基本工程结构,基于这些理念,前端开发就成了这个样子:
| 示意图 | 描述 |
|---|---|
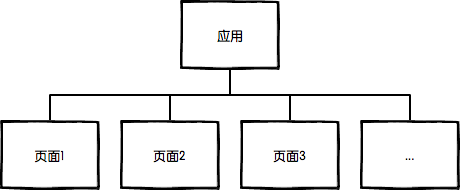
img1.png
|
|
| 整个Web应用由页面组成 | |
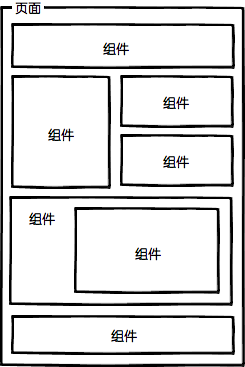
img2.png
|
|
| 页面由组件组成 | |
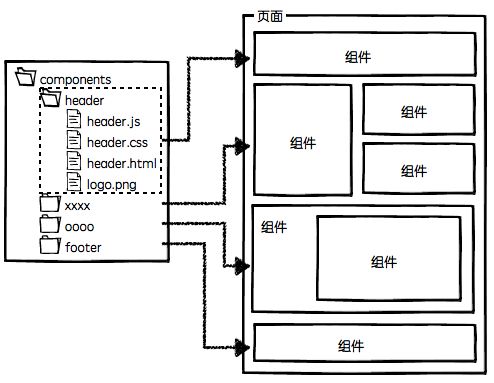
img3.png
|
|
| 一个组件一个目录,资源就近维护 | |
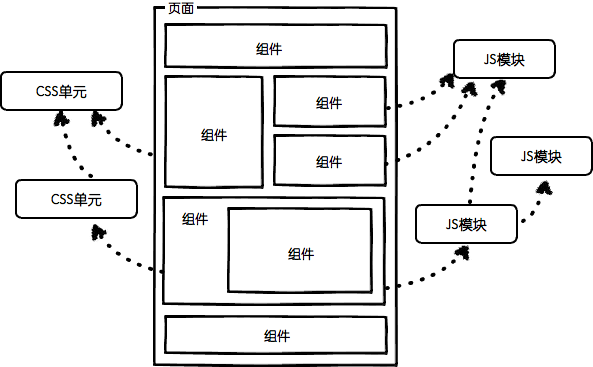
img4.png
|
|
| 组件可组合, 组件的JS可依赖其他JS模块, CSS可依赖其他CSS单元 |
综合上面的描述,对于一般中小规模的项目,大致可以规划出这样的源码目录结构:
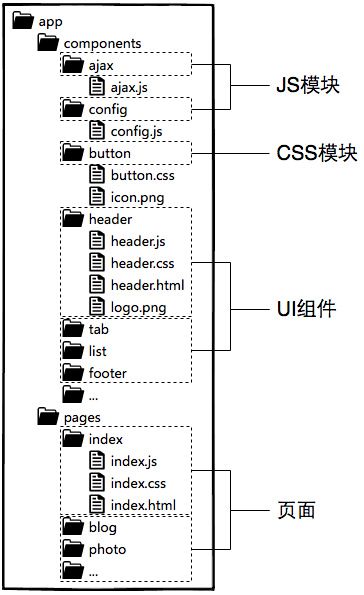
如果项目规模较大,涉及多个团队协作,还可以将具有相关业务功能的页面组织在一起,形成一个子系统,进一步将整个站点拆分出多个子系统来分配给不同团队维护。以上架构设计历经许多不同公司不同业务场景的前端团队验证,收获了不错的口碑,是行之有效的前端工程分治方案。
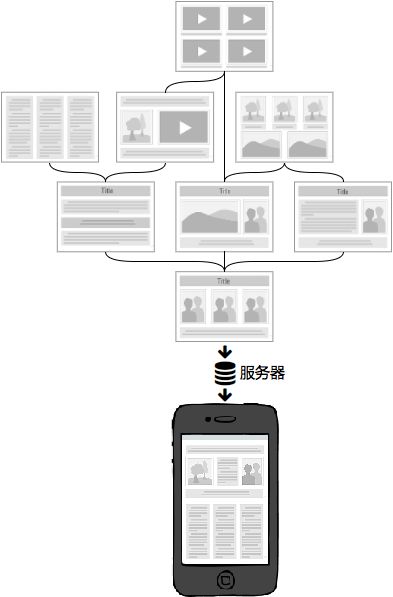
“智能”静态资源管理
上面提到的模块化/组件化开发,仅仅描述了一种开发理念,也可以认为是一种开发规范,倘若你认可这规范,对它的分治策略产生了共鸣,那我们就可以继续聊聊它的具体实现了。
很明显,模块化/组件化开发之后,我们最终要解决的,就是模块/组件加载的技术问题。然而前端与客户端GUI软件有一个很大的不同:
前端是一种远程部署,运行时增量下载的GUI软件
前端应用没有安装过程,其所需程序资源都部署在远程服务器,用户使用浏览器访问不同的页面来加载不同的资源,随着页面访问的增加,渐进式的将整个程序下载到本地运行,“增量下载”是前端在工程上有别于客户端GUI软件的根本原因。
上图展示了一款界面繁多功能丰富的应用,如果采用Web实现,相信也是不小的体量,如果用户第一次访问页面就强制其加载全站静态资源再展示,相信会有很多用户因为失去耐心而流失。根据“增量”的原则,我们应该精心规划每个页面的资源加载策略,使得用户无论访问哪个页面都能按需加载页面所需资源,没访问过的无需加载,访问过的可以缓存复用,最终带来流畅的应用体验。
这正是Web应用“免安装”的魅力所在。
由“增量”原则引申出的前端优化技巧几乎成为了性能优化的核心,有加载相关的按需加载、延迟加载、预加载、请求合并等策略;有缓存相关的浏览器缓存利用,缓存更新、缓存共享、非覆盖式发布等方案;还有复杂的BigRender、BigPipe、Quickling、PageCache等技术。这些优化方案无不围绕着如何将增量原则做到极致而展开。
所以我觉得:
前端开发最迫切需要做好的就是在基础架构中贯彻增量原则。
相信这种贯彻不会随着时间的推移而改变,在可预见的未来,无论在HTTP1.x还是HTTP2.0时代,无论在ES5亦或者ES6/7时代,无论是AMD/CommonJS/UMD亦或者ES6 module时代,无论端内技术如何变迁,我们都有足够充分的理由要做好前端程序资源的增量加载。
正如前面说到的,第三阶段前端工程缺少点什么呢?我觉得是在其基础架构中缺少这样一种“智能”的资源加载方案。没有这样的方案,很难将前端应用的规模发展到第四阶段,很难实现落地前面介绍的那种组件化开发方案,也很难让多方合作高效率的完成一项大型应用的开发,并保证其最终运行性能良好。在第四阶段,我们需要强大的工程化手段来管理”玩具般简单“的前端开发。
在我的印象中,Facebook是这方面探索的伟大先驱之一,早在2010年的Velocity China大会上,来自Facebook的David Wei博士就为业界展示了他们令人惊艳的静态网页资源管理和优化技术。
David Wei博士在当年的交流会上提到过一些关于Facebook的一些产品数据:
- Facebook整站有10000+个静态资源;
- 每个静态资源都有可能被翻译成超过100种语言版本;
- 每种资源又会针对浏览器生成3种不同的版本;
- 要针对不同带宽的用户做5种不同的打包方法;
- 有3、4个不同的用户组,用于小批次体验新的产品功能;
- 还要考虑不同的送达方法,可以直接送达,或者通过iframe的方式提升资源并行加载的速度;
- 静态资源的压缩和非压缩状态可切换,用于调试和定位线上问题

这是一个状态爆炸的问题,将所有状态乘起来,整个网站的资源组合方式会达到几百万种之多(去重之后统计大概有300万种组合方式)。支撑这么大规模前端项目运行的底层架构正是魏博士在那次演讲中分享的Static Resource Management System(静态资源管理系统),用以解决Facebook项目中有关前端工程的3D问题(Development,Deployment,Debugging)。
那段时间 FIS 项目正好遇到瓶颈,当时的FIS还是一个用php写的task-based构建工具,那时候对于前端工程的认知度很低,觉得前端构建不就是几个压缩优化校验打包任务的组合吗,写好流程调度,就针对不同需求写插件呗,看似非常简单。但当我们支撑越来越多的业务团队,接触到各种不同的业务场景时,我们深刻的感受到task-based工具的粗糙,团队每天疲于根据各种业务场景编写各种打包插件,构建逻辑异常复杂,隐隐看到不可控的迹象。
我们很快意识到把基础架构放到构建工具中实现是一件很愚蠢的事,试图依靠构建工具实现各种优化策略使得构建变成了一个巨大的黑盒,一旦发生问题,定位起来非常困难,而且每种业务场景都有不同的优化需求,构建工具只能通过静态分析来优化加载,具有很大的局限性,单页面/多页面/PC端/移动端/前端渲染/后端渲染/多语言/多皮肤/高级优化等等资源加载问题,总不能给每个都写一套工具吧,更何况这些问题彼此之间还可以有多种组合应用,工具根本写不过来。
Facebook的做法无疑为我们亮起了一盏明灯,不过可惜它并不开源(不是技术封锁,而是这个系统依赖FB体系中的其他方面,通用性不强,开源意义不大),我们只能尝试挖掘相关信息,网上对它的完整介绍还是非常非常少,分析facebook的前端代码也没有太多收获,后来无意中发现了facebook使用的项目管理工具phabricator中的一个静态管理方案Celerity,以及相关的说明,看它的描述很像是Facebook静态资源管理系统的一个mini版!
简单看过整个系统之后发现原理并不复杂(小而美的典范),它是通过一个小工具扫描所有静态资源,生成一张资源表,然后有一个PHP实现的资源管理框架(Celerity)提供了资源加载接口,替代了传统的script/link等静态的资源加载标签,最终通过查表来加载资源。
虽然没有真正看过FB的那套系统,但眼前的这个小小的框架给了当时的我们足够多的启示:
静态资源管理系统 = 资源表 + 资源加载框架
多么优雅的实现啊!
资源表是一份数据文件(比如JSON),是项目中所有静态资源(主要是JS和CSS)的构建信息记录,通过构建工具扫描项目源码生成,是一种k-v结构的数据,以每个资源的id为key,记录了资源的类别、部署路径、依赖关系、打包合并等内容,比如:
{
"a.js": {
"url": "/static/js/a.5f100fa.js",
"dep": [ "b.js", "a.css" ]
},
"a.css": {
"url": "/static/css/a.63cf374.css",
"dep": [ "button.css" ]
},
"b.js": {
"url": "/static/js/b.97193bf.js"
},
"button.css": {
"url": "/static/css/button.de33108.js"
}
}
而资源加载框架则提供一些资源引用的API,让开发者根据id来引用资源,替代静态的script/link标签来收集、去重、按需加载资源。调用这些接口时,框架通过查表来查找资源的各项信息,并递归查找其依赖的资源的信息,然后我们可以在这个过程中实现各种性能优化算法来“智能”加载资源。
根据业务场景的不同,加载框架可以在浏览器中用JS实现,也可以是后端模板引擎中用服务端语言实现,甚至二者的组合,不一而足。
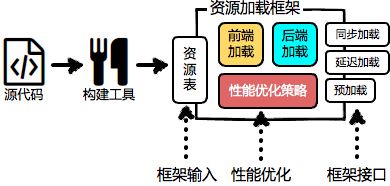
有关加载框架的具体实现我曾写过很多文章介绍,可以扩展阅读:
- 前端工程与性能优化
- 前端工程与模块化框架
这种设计很快被验证具有足够的灵活性,能够完美支撑不同团队不同技术规范下的性能优化需求,前面提到的按需加载、延迟加载、预加载、请求合并、文件指纹、CDN部署、Bigpipe、Quickling、BigRender、首屏CSS内嵌、HTTP 2.0服务端推送等等性能优化手段都可以很容易的在这种架构上实现,甚至可以根据性能日志自动进行优化(Facebook已实现)。
因为有了资源表,我们可以很方便的控制资源加载,通过各种手段在运行时计算页面的资源使用情况,从而获得最佳加载性能。无论是前端渲染的单页面应用,还是后端渲染的多页面应用,这种方法都同样适用。
此外,它还很巧妙的约束了构建工具的职责——只生成资源表。资源表是非常通用的数据结构,无论什么业务场景,其业务代码最终都可以被扫描为相同结构的表数据,并标记资源间的依赖关系,有了表之后我们只需根据不同的业务场景定制不同的资源加载框架就行了,从此彻底告别一个团队维护一套工具的时代!!!
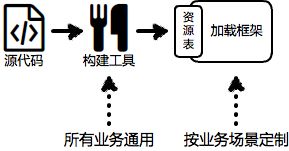
恩,如你所见,虽然彻底告别了一个团队一套工具的时代,但似乎又进入了一个团队一套框架的时代。其实还是有差别的,因为框架具有很大的灵活性,而且不那么黑盒,采用框架实现资源管理相比构建更容易调试、定位和升级变更。
深耕静态资源加载框架可以带来许多收益,而且有足够的灵活性和健壮性面向未来的技术变革,这个我们留作后话。
规范化
规范化其实是工程化中很重要的一个部分,项目初期规范制定的好坏会直接影响到后期的开发质量。
比如:
模块化和组件化确定了开发模型,而这些东西的实现就需要规范去落实。规范化其实是工程化中很重要的一个部分,项目初期规范制定的好坏会直接影响到后期的开发质量:
目录结构的制定
-
编码规范
制定一套良好的编码规范可以增强团队开发协作、提高代码质量。
推荐参考凹凸实验室打造的前端代码规范。编码规范包括
-
HTML规范。
基于 W3C、苹果开发者 等官方文档,并结合团队业务和开发过程中总结的规范约定,让页面HTML代码更具语义性。
-
CSS规范。
统一规范团队 CSS 代码书写风格和使用 CSS 预编译语言语法风格,提供常用媒体查询语句和浏览器私有属性引用,并从业务层面统一规范常用模块的引用。
-
JS规范。
统一规范团队 CSS 代码书写风格和使用 CSS 预编译语言语法风格,提供常用媒体查询语句和浏览器私有属性引用,并从业务层面统一规范常用模块的引用。
-
图片规范。
了解各种图片格式特性,根据特性制定图片规范,包括但不限于图片的质量约定、图片引入方式、图片合并处理等,旨在从图片层面优化页面性能。
-
命名规范。
从 目录、图片、HTML/CSS文件、ClassName 的命名等层面约定规范团队的命名习惯,增强团队代码的可读性。
-
-
前后端接口规范
“基于 Ajax 带来的 SPA 时代”,这种模式下,前后端的分工非常清晰,前后端的关键协作点是 Ajax 接口,引发一个重要问题:前后端的对接界面双方却关注甚少,没有任何接口约定规范情况下各自撸起袖子就是干,导致我们在产品项目开发过程中,前后端的接口联调对接工作量占比在30%-50%左右,甚至会更高。往往前后端接口联调对接及系统间的联调对接都是整个产品项目研发的软肋。
接口规范主要初衷就是规范约定先行,尽量避免沟通联调产生的不必要的问题,让大家身心愉快地专注于各自擅长的领域。
那么,对于这一SPA阶段,前后端分离有几个重要的关注挑战:
-
职责分离
- 前后端仅仅通过异步接口(AJAX/JSONP)来编程;
- 前后端都各自有自己的开发流程,构建工具,测试集合;
- 关注点分离,前后端变得相对独立并松耦合。
后端 前端 提供数据 接收数据,返回数据 处理业务逻辑 处理渲染逻辑 -
规范原则
- 接口返回数据即显示,前端仅做渲染逻辑处理;
- 渲染逻辑禁止跨多个接口调用;
- 前端关注交互、渲染逻辑,尽量避免业务逻辑处理的出现;
- 请求响应传输数据格式:JSON,JSON数据尽量简单轻量,避免多级JSON的出现;
-
响应格式
- 响应基本格式及处理状态值的规范。
- 基本响应格式
- 列表响应格式
- 特殊内容
- 下拉框、复选框、单选框统一由后端逻辑判定选中返回给前端展示;
- 关于Boolean类型,JSON数据传输中一律使用1/0来标示,1为是/True,0为否/False
- 关于日期类型,JSON数据传输中一律使用字符串,具体日期格式因业务而定;
- 响应基本格式及处理状态值的规范。
-
文档规范
组件管理
git分支管理
commit描述规范
视觉图标规范
...
自动化
前端工程化的很多脏活累活都应该交给自动化工具来完成。需要秉持的一个理念是:
任何简单机械的重复劳动都应该让机器去完成。
图标合并
持续继承
自动化构建
自动化部署
1.代码 SVN 管理,手动打包代码,生成到 window server 服务器,用 IIS 进行部署
前端 jquery / flex3,后端.NET
2.代码 SVN 管理,运维同学通过 jenkins 拉取代码,进行部署
此时已经用 react,后端 java
3.代码 GitLab 管理,前端使用 CI + docker + k8s 自动化打包上线
- 自动化测试
上面这一系列的过程,可能都是你手动一步一步的打开文件、敲命令等纯劳力的重复性去做,而且还要保证每个步骤都是正确的才能进行下一步操作,一旦发生错误还没有可追溯可跟踪的相关日志和记录。
--
npm的基本使用和总结

3.1 npm 是什么
3.1.1npm出现的背景
当一个项目依赖的代码越来越多,程序员发现这是一件很麻烦的事情:
1.去 jQuery 官网下载 jQuery
2.去 BootStrap 官网下载 BootStrap
3.去 Underscore 官网下载 Underscore
......
有些程序员就受不鸟了,一个拥有三大美德的程序员 Isaac Z. Schlueter (以下简称 Isaaz)给出了一个解决方案:用一个工具把这些代码集中到一起来管理吧!这个工具就是他用 JavaScript (运行在 Node.js 上)写的 npm,全称是 Node Package Manager。
3.1.2npm的思路
1.买个服务器作为代码仓库(repository),在里面放所有需要被共享的代码
2.发邮件通知 jQuery 、Bootstrap 、Underscore 的作者使用 npm publish 把代码提交到 repository 上,分别取名 jquery、bootstrap 和 underscore(注意大小写)
3.社区里的其他人如果想使用这些代码,就把 jquery、bootstrap 和 underscore 写到 package.json 里,然后运行 npm install ,npm 就会帮他们下载代码
4.下载完的代码出现在 node_modules 目录里,就可以随意使用了。
这些可以被使用的代码被叫做「包」(package),这就是 npm名字的由来:Node Package(包) Manager(管理器)。
3.1.3发展
Isaaz 通知 jQuery 作者 John Resig,他会答应吗?这事儿不一定啊,对不对。只有社区里的人都觉得 「npm 是个宝」的时候,John Resig 才会考虑使用 npm。
那么 npm 是怎么火的呢?
npm 的发展是跟 node.js 的发展相辅相成的。node.js 是由一个在德国工作的美国程序员 Ryan Dahl 写的。他写了 node.js,但是 node.js 缺少一个包管理器,于是他和npm的作者一拍即合、抱团取暖,最终 node.js 内置了 npm。
后来的事情大家都知道,node.js 火了。随着 node.js 的火爆,大家开始用 npm 来共享 JS 代码了,于是 jQuery 作者也将 jQuery 发布到 了 npm 上。所以现在,你可以使用 npm install jquery 来下载 jQuery 代码了。现在用 npm 来分享代码已经成了前端的标配。
安装node环境的时候,已经自动安装了 npm 命令行工具,不需要单独安装。可以通过 npm -v 测试npm是否可用
3.2 npm常用的命令
3.2.1 npm init
前端工程化里最重要的是npm init.用来初始化一个前端工程项目。
说到npm init就不得不说package.json,我们都知道npm init 命令用来初始化一个简单的 package.json 文件,执行该命令后终端会依次询问 name, version, description 等字段。只需要执行npm init即可,以交互方式完成package.json的创建。package.json是 NodeJS 约定的用来存放项目的信息和配置等信息的文件。
如果想生成默认package.json,可以执行npm init -y,连交互式界面都不会出现。
事实上,最小单位的npm包就是只包含一个package.json文件的包,这样的话npm init就完成了一个npm包的创建。
package.json不存在时,用npm init可以自动生成package.json,再次执行npm init可以更新你项目所依赖的第三方模块。
3.2.2 npm install
npm 5x下npm install执行原理:
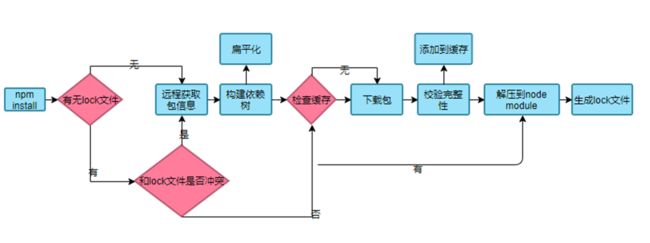
当我们的工程化项目需要安装依赖包的时候需要执行npm install命令,npm install有以下几种方式:
| 命令 | 作用 |
|---|---|
| npm inistall packageName | 本地安装,安装到项目目录下,不在package.json中写入依赖 |
| npm inistall packageName -g | 全局安装,安装在Node全局安装目录下的node_modules下 |
| npm inistall packageName --save | 安装到项目目录下,并在package.json文件的dependencies中写入依赖,简写为-S |
| npm inistall packageName --save-dev | 安装到项目目录下,并在package.json文件的devDependencies中写入依赖,简写为-D |
具体说明如下:
npm install packageName -g
安装模块到全局,不会在项目node_modules目录中保存模块包。
不会将模块依赖写入devDependencies或dependencies 节点。
运行 npm install 初始化项目时不会下载模块。
npm install packageName
会把packageName包安装到node_modules目录中
不会修改package.json
运行 npm install 初始化项目时不会下载模块。
npm install packageName --save
会把packageName包安装到node_modules目录中
会在package.json的dependencies属性下添加packageName
之后运行npm install命令时,会自动安装packageName到node_modules目录中
之后运行npm install --production或者注明NODE_ENV变量值为production时,会自动安装packageName到node_modules目录中,即是在线上环境运行时会将包安装
npm install packageName --save-dev
会把packageName包安装到node_modules目录中
会在package.json的devDependencies属性下添加packageName
之后运行npm install命令时,会自动安装packageName到node_modules目录中
之后运行npm install –production或者注明NODE_ENV变量值为production时,不会自动安装packageName到node_modules目录中
指定版本安装
npm install packageName@verson
注意: 从npm 5x开始,可以不用手动添加-s/--save指令。直接执行npm install packageName就会默认把依赖包添加到dependencies.
使用原则:
devDependencies 节点下的模块是我们在开发时需要用的,比如项目中使用的 gulp ,压缩css、js的模块。这些模块在我们的项目部署后是不需要的,所以我们可以使用--save-dev的形式安装。像 express 这些模块是项目运行必备的,应该安装在 dependencies 节点下,所以我们应该使用--save的形式安装。
package.json中的依赖包格式如下:
总结为一句话:运行时需要用到的包使用––save,否则使用––save-dev。
3.2.3 NPM依赖包版本号~和^和*的区别
依赖包安装完并不意味着就万事大吉了,版本的维护和更新也很重要。
npm 依赖管理的一个重要特性是采用了语义化版本 (semver) 规范,作为依赖版本管理方案。
semver 约定一个包的版本号必须包含3个数字,格式必须为 MAJOR.MINOR.PATCH, 意为 主版本号.小版本号.修订版本号.
- MAJOR 对应大的版本号迭代,做了不兼容旧版的修改时要更新 MAJOR 版本号
- MINOR 对应小版本迭代,发生兼容旧版API的修改或功能更新时,更新MINOR版本号
- PATCH 对应修订版本号,一般针对修复 BUG 的版本号
对于包作者(发布者),npm 要求在 publish 之前,必须更新版本号。npm 提供了 npm version 工具,执行 npm version major|minor|patch 可以简单地将版本号中相应的数字加1.
常用的规则示例如下表:
| range | 含义 | 例 |
|---|---|---|
^2.2.1 |
指定的 MAJOR 版本号下, 所有更新的版本 | 匹配 2.2.3, 2.3.0; 不匹配 1.0.3, 3.0.1 |
~2.2.1 |
指定 MAJOR.MINOR 版本号下,所有更新的版本 | 匹配 2.2.3, 2.2.9 ; 不匹配 2.3.0, 2.4.5 |
>=2.1 |
版本号大于或等于 2.1.0 |
匹配 2.1.2, 3.1 |
<=2.2 |
版本号小于或等于 2.2 |
匹配 1.0.0, 2.2.1, 2.2.11 |
1.0.0 - 2.0.0 |
版本号从 1.0.0 (含) 到 2.0.0 (含) | 匹配 1.0.0, 1.3.4, 2.0.0 |
* |
这意味着安装最新版本的依赖包 | 下载最新的包 |
任意两条规则,用空格连接起来,表示“与”逻辑,即两条规则的交集:
如 >=2.3.1 <=2.8.0 可以解读为: >=2.3.1 且 <=2.8.0
- 可以匹配
2.3.1,2.4.5,2.8.0 - 但不匹配
1.0.0,2.3.0,2.8.1,3.0.0
任意两条规则,通过 || 连接起来,表示“或”逻辑,即两条规则的并集:
如 ^2 >=2.3.1 || ^3 >3.2
- 可以匹配
2.3.1,2,8.1,3.3.1 - 但不匹配
1.0.0,2.2.0,3.1.0,4.0.0
PS: 除了这几种,还有如下更直观的表示版本号范围的写法:
-
*或x匹配所有主版本 -
1或1.x匹配 主版本号为 1 的所有版本 -
1.2或1.2.x匹配 版本号为 1.2 开头的所有版本
PPS: 在常规仅包含数字的版本号之外,semver 还允许在 MAJOR.MINOR.PATCH 后追加 - 后跟点号分隔的标签,作为预发布版本标签 - Prerelese Tags,通常被视为不稳定、不建议生产使用的版本。例如:
1.0.0-alpha1.0.0-beta.11.0.0-rc.3
上表中我们最常见的是 ^1.8.11 这种格式的 range, 因为我们在使用 npm install 安装包时,npm 默认安装当前最新版本,例如 1.8.11, 然后在所安装的版本号前加^号, 将 ^1.8.11 写入 package.json 依赖配置,意味着可以匹配 1.8.11 以上,2.0.0 以下的所有版本。
固定版本:首先我们可以指定特定的版本号,直接写1.2.3,前面什么前缀都没有,这样固然没问题,但是如果依赖包发布新版本修复了一些小bug,那么需要手动修改package.json文件。
^ 版本: 虽然不需要手动修改package.json文件就可享用修复后的依赖包,但^版本之间跨越比较大,更甚至有些高版本于低版本不兼容。
~ 版本: 不仅不需要手动修改package.json文件,也不像^版本之间跨越比较大,这样可以保证项目不会出现大的问题,也能保证包中的小bug可以得到修复。
*版本: 意味着时刻安装最新版本的依赖包,缺点同^版本,可能会造成版本不兼容。
3.2.4 npm update
问题来了,在安装完一个依赖包之后有新版本发布了,如何使用 npm 进行版本升级呢?——答案是简单的 npm install 或 npm update,但在不同的 npm 版本,不同的 package.json, package-lock.json 文件,安装/升级的表现也不同。
我们不妨还以 webpack举例,做如下的前提假设:
项目最初初始化时,安装了当时最新的包 [email protected],并且 package.json 中的依赖配置为: "webpack": "^1.8.0"
假设当前 webpack 最新版本为 5.2.0, webpack 1.x 最新子版本为 1.15.0
如果我们使用的是 npm 3:
| # | package.json | node_modules (BEFORE) | command (npm 3) | node_modules (AFTER) |
|---|---|---|---|---|
| a | webpack: ^1.8.0 | [email protected] | install | [email protected] |
| b | webpack: ^1.8.0 | 空 | install | [email protected] |
| c | webpack: ^1.8.0 | [email protected] | update | [email protected] |
| d | webpack: ^1.8.0 | 空 | update | [email protected] |
根据这个表我们可以对 npm 3 得出以下结论:
如果本地 node_modules 已安装,再次执行 install 不会更新包版本, 执行 update 才会更新; 而如果本地 node_modules 为空时,执行 install/update 都会直接安装更新包;
npm update 总是会把包更新到符合 package.json 中指定的 semver 的最新版本号——本例中符合 ^1.8.0 的最新版本为 1.15.0
一旦给定 package.json, 无论后面执行 npm install 还是 update, package.json 中的 webpack 版本一直顽固地保持 一开始的 ^1.8.0 岿然不动
这里不合理的地方在于,如果最开始团队中第一个人安装了 [email protected], 而新加入项目的成员, checkout 工程代码后执行 npm install 会安装1.15.0 版本。但万一有不熟悉不遵循此约定的包发布者,发布了不兼容的包,此时就可能出现因依赖环境不同导致的 bug。
下面由 npm 5 带着 package-lock.json 闪亮登场:
执行 install/update 的效果是这样的 (node 9.8.0, npm 5.7.1 环境下试验),下表为表述简单,省略了包名 webpack, install 简写 i, update 简写为 up
| # | package.json | node_modules (BEFORE) | package-lock (BEFORE) | command (npm 5) | package.json (AFTER) | node_modules (AFTER) |
|---|---|---|---|---|---|---|
| a) | ^1.8.0 | @1.8.0 | @1.8.0 | i | ^1.8.0 | @1.8.0 |
| b) | ^1.8.0 | 空 | @1.8.0 | i | ^1.8.0 | @1.8.0 |
| c) | ^1.8.0 | @1.8.0 | @1.8.0 | up | ^1.15.0 | @1.15.0 |
| d) | ^1.8.0 | 空 | @1.8.0 | up | ^1.8.0 | @1.15.0 |
| e) | ^1.15.0 | @1.8.0 | @1.15.0 | i | ^1.15.0 | @1.15.0 |
| f) | ^1.15.0 | @1.8.0 | @1.15.0 | up | ^1.15.0 | @1.15.0 |
与 npm 3 相比,在安装和更新依赖版本上主要的区别为:
- package-lock用来锁定npm install.无论何时执行 install, npm 都会优先按照 package-lock 中指定的版本来安装 webpack; 避免了 npm 3 表中情形 b) 的状况;
- 无论node_modules是否为空。执行npm update后node_modules都会更新。若node_modules不为空,执行 npm update,package.json 中的版本号也会随之更新。为空的话不更新。
3.无论何时完成安装/更新, package-lock 文件总会跟着 node_modules 更新 —— (因此可以视 package-lock 文件为 node_modules 的 JSON 表述)
更新模块注意事项:
更新模块只能往后面版本更新,不能往老的版本回滚更新。
比如先安装了 lodash 模块 3.9.* 版本,可以往后更新到 3.10.* 版本,但是不能往前更新回 3.8.* 版本。
更新模块只能更新到小版本号最新的那个版本,不能更新大版本号。
一个模块的版本号由三部分组成:大版本号.小版本号.修订号。
如 lodash 模块的某个版本 3.9.1,其中:
3 是大版本号
9 是小版本号
1 是修订号�使用 $ npm update lodash 只能将 3.9.1 更新到小版本号最大的那个版本,这里是 3.10.1,而不能更新到 4.* 版本。这一点要特别特别特别的注意。要更新到模块的最新版本需要使用 npm update moduleName@latest 更新。
3.2.5最佳实践
总结起来,在npm 5X 时代,我认为的依赖版本管理应当是:
使用 npm: >=5.1 版本, 保持 package-lock.json 文件默认开启配置
初始化:
第一作者初始化项目时使用 npm install
升级依赖包:
升级小版本: 本地执行 npm update 升级到新的小版本
升级大版本: 本地执行 npm install
也可手动修改 package.json 中版本号为要升级的版本(大于现有版本号)并指定所需的 semver, 然后执行 npm install
本地验证升级后新版本无问题后,提交新的 package.json, package-lock.json 文件
降级依赖包:
正确: npm install
错误: 手动修改 package.json 中的版本号为更低版本的 semver, 这样修改并不会生效,因为再次执行 npm install 依然会安装 package-lock.json 中的锁定版本
删除依赖包:
Plan A: npm uninstall
Plan B: 把要卸载的包从 package.json 中 dependencies 字段删除, 然后执行 npm install 并提交 package.json 和 package-lock.json
任何时候有人提交了 package.json, package-lock.json 更新后,团队其他成员应在 svn update/git pull 拉取更新后执行 npm install 脚本安装更新后的依赖包
恭喜你终于可以跟 rm -rf node_modules && npm install 这波操作说拜拜了(其实并不会)
3.2.6npm run
npm run是npm run-script的简写,顾名思义就是执行脚本。执行的脚本配置在package.json中的 scripts对象。例如:
"scripts": {
"start": "node scripts/start.js",
"build": "node scripts/build.js",
"test": "node scripts/test.js"
},
这样就可以通过npm run start脚本代替 node scripts/start.js脚本来启动项目,而无需每次都敲一遍这么长的脚本。
$ npm run start
# 等同于执行
$ node scripts/start.js
3.2.6.1 npm run的原理
npm 脚本的原理非常简单。每当执行npm run,就会自动新建一个 Shell,在这个 Shell 里面执行指定的脚本命令。因此,只要是 Shell(一般是 Bash)可以运行的命令,就可以写在 npm 脚本里面。
比较特别的是,npm run新建的这个 Shell,会将当前目录的node_modules/.bin子目录加入PATH变量,执行结束后,再将PATH变量恢复原样。
这意味着,当前目录的node_modules/.bin子目录里面的所有脚本,都可以直接用脚本名调用,而不必加上路径。比如,当前项目的依赖里面有 Mocha,只要直接写mocha test就可以了。
"test": "mocha test"
而不用写成下面这样。
"test": "./node_modules/.bin/mocha test"
由于 npm 脚本的唯一要求就是可以在 Shell 执行,因此它不一定是 Node 脚本,任何可执行文件都可以写在里面。
3.2.6.2 npm run—用法指南(传入参数)
- 通过设置全局变量获取参数
在node中,有全局变量process表示的是当前的node进程。process.env包含着关于系统环境的信息。但是process.env中并不存在NODE_ENV这个东西。NODE_ENV是用户一个自定义的变量,一般用来判断生产环境或开发环境。例如:
// package.json
"scripts": {
"start": "SET NODE_ENV=development&& node ./bin/watch.js",
},
// watch.js
if(process.env.NODE_ENV === 'development'){}
- process.argv获取传入参数
可以通过命令行传入,例如:
npm run start --port=3000
或者// package.json中写死,比如
"scripts": {
"start": "node ./bin/watch.js --port=3000",
},
输出的process.argv是一个数组:

这个数组包含了启动Node.js进程时的命令行参数,其中:
- 数组的第一个元素process.argv[0]——返回启动Node.js进程的可执行文件所在的绝对路径
- 第二个元素process.argv[1]——为当前执行的JavaScript文件路径
- 剩余的元素为其他命令行参数
3.2.6.3 执行顺序
如果 npm 脚本里面需要执行多个任务,那么需要明确它们的执行顺序。
如果是并行执行(即同时的平行执行),可以使用&符号。
$ npm run script1.js & npm run script2.js
如果是继发执行(即只有前一个任务成功,才执行下一个任务),可以使用&&符号。
$ npm run script1.js && npm run script2.js
3.3package.json详解
什么是Node.js的模块(Module)?在Node.js中,模块是一个库或框架,也是一个Node.js项目。Node.js项目遵循模块化的架构,当我们创建了一个Node.js项目,意味着创建了一个模块,这个模块的描述文件,被称为package.json。
npm init之后,会根据你的输入生成一个package.json的文件。
{
"name": "Hello World", // 包名,必填字段
"version": "0.0.1", //包的版本号,必填字段
"author": "张三", //包的作者
"description": "第一个node.js程序", //包的描述
"keywords": [ //关键字。方便使用者在 npm search中搜索。格式为字符串。
"node.js",
"javascript"
],
"repository": { //用于指示源代码存放的位置
"type": "git",
"url": "https://path/to/url"
},
"license": "MIT",
"engines": { //指明了该项目所需要的node.js版本
"node": "0.10.x"
},
"bugs": { // 你项目的提交问题的url和(或)邮件地址。
"url": "http://path/to/bug",
"email": "[email protected]"
},
"contributors": [ //包的其他贡献者
{
"name": "李四",
"email": "[email protected]"
}
],
"scripts": { //指定了运行脚本命令的npm命令行缩写,使用scripts字段定义脚本命令。
"start": "node index.js"
},
"dependencies": { // 生产/开发环境依赖包列表
"express": "latest",
"mongoose": "~3.8.3",
"handlebars-runtime": "~1.0.12",
"express3-handlebars": "~0.5.0",
"MD5": "~1.2.0"
},
"devDependencies": { //指定项目开发所需要的模块。
"bower": "~1.2.8",
"grunt": "~0.4.1",
"grunt-contrib-concat": "~0.3.0",
"grunt-contrib-jshint": "~0.7.2",
"grunt-contrib-uglify": "~0.2.7",
"grunt-contrib-clean": "~0.5.0",
"browserify": "2.36.1",
"grunt-browserify": "~1.3.0",
}
}
其他配置项可以查看文章package.json 配置学习。写的非常详细。
3.4 npm2和npm2以上版本的原理和区别
3.4.1 npm 2 嵌套结构
npm 2 在安装依赖包时,采用简单的递归安装方法。执行 npm install 后,npm 2 依次递归安装 webpack 和 nconf 两个包到 node_modules 中。执行完毕后,我们会看到 ./node_modules 这层目录只含有这两个子目录。
node_modules/
├── nconf/
└── webpack/
进入更深一层 nconf 或 webpack 目录,将看到这两个包各自的 node_modules 中,已经由 npm 递归地安装好自身的依赖包。包括 ./node_modules/webpack/node_modules/webpack-core , ./node_modules/conf/node_modules/async 等等。而每一个包都有自己的依赖包,每个包自己的依赖都安装在了自己的 node_modules 中。依赖关系层层递进,构成了一整个依赖树,这个依赖树与文件系统中的文件结构树刚好层层对应。
最方便的查看依赖树的方式是直接在 app 目录下执行 npm ls 命令。
[email protected]
├─┬ [email protected]
│ ├── [email protected]
│ ├── [email protected]
│ ├── [email protected]
│ └── [email protected]
└─┬ [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── ...
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
└─┬ [email protected]
├── [email protected]
└── [email protected]
这样的目录结构优点在于层级结构明显,便于进行傻瓜式的管理:
- 例如新装一个依赖包,可以立即在第一层 node_modules 中看到子目录
- 在已知所需包名和版本号时,甚至可以从别的文件夹手动拷贝需要的包到 node_modules 文件夹中,再手动修改 package.json 中的依赖配置
- 要删除这个包,也可以简单地手动删除这个包的子目录,并删除 package.json 文件中相应的一行即可
实际上,很多人在 npm 2 时代也的确都这么实践过,的确也都可以安装和删除成功,并不会导致什么差错。
但这样的文件结构也有很明显的问题:
- 对复杂的工程, node_modules 内目录结构可能会太深,导致深层的文件路径过长而触发 windows 文件系统中,文件路径不能超过 260 个字符长的错误
- 部分被多个包所依赖的包,很可能在应用 node_modules 目录中的很多地方被重复安装。随着工程规模越来越大,依赖树越来越复杂,这样的包情况会越来越多,造成大量的冗余。
——在我们的示例中就有这个问题,webpack 和 nconf 都依赖 async 这个包,所以在文件系统中,webpack 和 nconf 的 node_modules 子目录中都安装了相同的 async 包,并且是相同的版本。
+-------------------------------------------+
| app/ |
+----------+------------------------+-------+
| |
| |
+----------v------+ +---------v-------+
| | | |
| [email protected] | | [email protected] |
| | | |
+--------+--------+ +--------+--------+
| |
+-----v-----+ +-----v-----+
|[email protected]| |[email protected]|
+-----------+ +-----------+
3.4.2 npm 3 - 扁平结构
主要为了解决以上问题,npm 3 的 node_modules 目录改成了更加扁平状的层级结构。文件系统中 webpack, nconf, async 的层级关系变成了平级关系,处于同一级目录中。
+-------------------------------------------+
| app/ |
+-+---------------------------------------+-+
| |
| |
+----------v------+ +-------------+ +---------v-------+
| | | | | |
| [email protected] | | [email protected] | | [email protected] |
| | | | | |
+-----------------+ +-------------+ +-----------------+
虽然这样一来 webpack/node_modules 和 nconf/node_modules 中都不再有 async 文件夹,但得益于 node 的模块加载机制,他们都可以在上一级 node_modules 目录中找到 async 库。所以 webpack 和 nconf 的库代码中 require('async') 语句的执行都不会有任何问题。
这只是最简单的例子,实际的工程项目中,依赖树不可避免地会有很多层级,很多依赖包,其中会有很多同名但版本不同的包存在于不同的依赖层级,对这些复杂的情况, npm 3 都会在安装时遍历整个依赖树,计算出最合理的文件夹安装方式,使得所有被重复依赖的包都可以去重安装。
npm 文档提供了更直观的例子解释这种情况:
假如
package{dep}写法代表包和包的依赖,那么A{B,C},B{C},C{D}的依赖结构在安装之后的 node_modules 是这样的结构:
A
+-- B
+-- C
+-- D
这里之所以 D 也安装到了与 B C 同一级目录,是因为 npm 会默认会在无冲突的前提下,尽可能将包安装到较高的层级。
如果是
A{B,C},B{C,D@1},C{D@2}的依赖关系,得到的安装后结构是:
A
+-- B
+-- C
`-- D@2
+-- D@1
这里是因为,对于 npm 来说同名但不同版本的包是两个独立的包,而同层不能有两个同名子目录,所以其中的 D@2 放到了 C 的子目录而另一个 D@1 被放到了再上一层目录。
很明显在 npm 3 之后 npm 的依赖树结构不再与文件夹层级一一对应了。想要查看 app 的直接依赖项,要通过 npm ls 命令指定 --depth 参数来查看:
npm ls --depth 1
PS: 与本地依赖包不同,如果我们通过
npm install --global全局安装包到全局目录时,得到的目录依然是“传统的”目录结构。而如果使用 npm 3 想要得到“传统”形式的本地 node_modules 目录,使用npm install --global-style命令即可。
3.5 自己封装一个npm包

1.创建文件夹hello-acg
2.切换终端进入hello-acg文件夹 并输入 npm init --yes(初始化配置)
- 修改package.json文件
{
"name": "hello-acg",
"version": "1.0.0",
"description": "常用的表单验证",
"main": "./src/index.js",
"scripts": {
},
"keywords": [],
"author": "",
"license": "MIT",
"devDependencies": {
}
}
- 添加LICENCE或LICENSE文件, 说明对应的开源协议
到SPDX License List 或者Open Source Initiative,下载相应协议的模板,我们这里选用MIT,修改必要的协议时间和作者:
MIT License
Copyright (c)
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
5.添加ReadMe.md和.gitignore文件
可以去github gitignore 下载一个最相近的模板然后改改
或者执行命令:
echo > .babelrc
echo > .npmignore
echo > .gitignore
echo > README.md
生成如下目录:
hello-acg
------------- .gitignore
------------- .npmignore
------------- LICENCE
------------- README.md
------------- package.json
- 代码结构组织加入代码相关的目录
mkdir bin
mkdir src
mkdir lib
echo > bin/helloacg
echo > src/index.js
echo > lib/test.js
生成如下目录:
hello-acg
├── bin // 存放内部命令对应的可执行文件
│ ├── index // 用于存放javascript代码(一般为引入入口文件并执行.文件无后缀)
├── lib/ // 目录: 用于存放javascript业务代码
│ ├── index.js // javascript业务代码
├── src/ // 目录: 源代码目录
│ ├── index.js // 文件: 入口文件
├── .babelrc
├── LICENCE
├── .gitignore
├── .npmignore
├── package.json
├── README.md
windows系统新建文件为: echo > 带后缀的文件名
linux系统下新建文件为: touch 带后缀的文件名
7.编写src/index.js文件如下:
let validateForm = {
/**
* 描述:检测邮箱格式是否正确
* @parmas1 检测所需文本
* return bool
*/
checkEmail(textValue = " ") {
let result = false;
let text = textValue.replace(/(^\s*)|(\s*$)/g, ""); // 去除左右空格
let reg = /^([a-zA-Z]|[0-9]|_)+@([0-9]|[a-zA-Z])+.com$/; // 检测大陆常见邮箱
result = reg.test(text);
return result;
},
/**
* 描述:检测密码格式至少有length位以上,其中密码必须包含一个数字、一个字母、一个特殊符号,不能有空格,中文字符。
* @parmas1 检测所需文本 @parmas2 设置密码最短长度。
* return bool
*/
checkPassword(textValue = " ", length = 0) {
let text = textValue.replace(/(^\s*)|(\s*$)/g, ""); // 去除左右空格
// 查看长度是否小于多少位
if (text.length < length) return false;
// 查看是否有数字
let reg = /\d{1,}/g;
if (reg.test(text) == false) return false;
// 查看是否有字母
reg = /[a-zA-Z]{1,}/g;
if (reg.test(text) == false) return false;
// 查看是否有空格
reg = /\s/g;
if (reg.test(text)) return false;
// 查看是否有中文
reg = /[\u4E00-\u9FA5\uF900-\uFA2D]/g;
if (reg.test(text)) return false;
// 查看是否有特俗符合
reg = /[~!@#$%^&*()_+/-{}'"]{1,}/g;
if (reg.test(text) == false) return false;
return true;
},
/**
* 描述:检测用户格式至少有length位以上,其中用户名不能有空格,中文字符。
* @parmas1 检测所需文本 @parmas2 设置密码最短长度。
* return bool
*/
checkUserName(textValue = " ", length = 0) {
let text = textValue.replace(/(^\s*)|(\s*$)/g, ""); // 去除左右空格
// 查看长度是否小于多少位
if (text.length < length) return false;
// 查看是否有空格
reg = /\s/g;
if (reg.test(text)) return false;
// 查看是否有中文
reg = /[\u4E00-\u9FA5\uF900-\uFA2D]/g;
if (reg.test(text)) return false;
return true;
}
};
module.exports = validateForm;
8.申请一个npm 账号 以及创建好相关 github 项目
前往申请 npm 账号: https://www.npmjs.com/
此处本人创建的 github 项目名字为hp-validateform,你需要另外重新起个名字。
- 发布 npm 包
进入项目根目录,登录刚刚申请的npm 账号。登录完成以后执行提交。
npm login # 登陆
npm publish # 发布
发布npm包的时候需要注意把npm仓库镜像库,从国内的淘宝源切换到npm国外源,不然无法提交。
得到原本的镜像地址
npm get registry
https://registry.npmjs.org/
设成百度的或者淘宝镜像
npm config set registry http://registry.npm.baidu-int.com/
npm config set registry http://registry.npm.taobao.org/
换成原来的
npm config set registry https://registry.npmjs.org/
10.安装并使用
终端输入:npm i hp-validate-form
使用:
let obj = require("hp-validate-form");
console.log(obj)

cli功能设计
cli设计可以查看我开发的Neves
Neves脚手架文档
总结
在业界内有这么一句话:任何简单机械的重复劳动都应该让机器去完成。
总结
回顾一下前面提到过的前端工程三个阶段:
- 第一阶段:库/框架选型
- 第二阶段:简单构建优化
- 第三阶段:JS/CSS模块化开发
现在补充上第四阶段:
- 第四阶段:组件化开发与资源管理
由于先天缺陷,前端相比其他软件开发,在基础架构上更加迫切的需要组件化开发和资源管理,而解决资源管理的方法其实一点也不复杂:
一个通用的资源表生成工具 + 基于表的资源加载框架
现代前端技术不再是以前刀耕火种的年代了。所以前端工程化的很多脏活累活都应该交给自动化工具来完成。如现在社区和市场上有 Jenkins、Travis CI、Circle CI、Codeship 等很多知名持续集成和持续部署工具(CI/CD),这些工具都可帮你自动完成构建、测试、部署代码的过程。