Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services)或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
一、Scrapy框架组件介绍
在介绍Scrapy的工作原理之前,我们简单了解下Scrapy框架中的各个组件。如下图16-1所示。
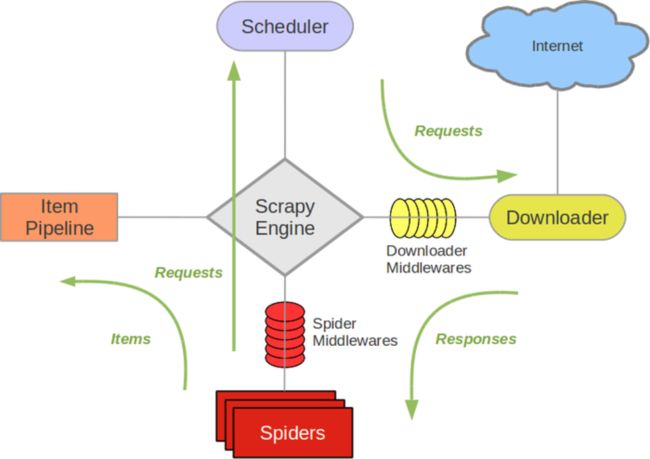
Scrapy框架主要由六大组件组成,它们分别是调试器(Scheduler)、下载器(Downloader)、爬虫(Spider)、中间件(Middleware)、实体管道(Item Pipeline)和Scrapy引擎(Scrapy Engine)。
1.1、调度器(Scheduler)
调度器,负责对Spider提交的下载请求进行调度。说白了可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址(不做无用功)。用户可以跟据自己的需求定制调度器。
1.2、下载器(Downloader)
下载器,负责下载页面(发送HTTP请求/接收HTTP响应)。是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。
1.3、爬虫(Spider)
爬虫,负责提取页面中数据,并产生对新页面的下载请求。是用户最关心的部份,也是由用户自己实现。用户定制自己的爬虫,用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
1.4、中间件(Middleware)
中间件,负责对Request对象和Response对象进行处理。如上图16-1所示,Scrapy框架中有两种中间件:爬虫中间件(Spider Middleware)和下载器中间件(Downloader Middleware)。
爬虫中间件是介入到Scrapy的Spider处理机制的钩子框架,可以添加代码来处理发送给Spiders的Response及Spider产生的Item和Request。
下载器中间件是介于Scrapy的Request/Response处理的钩子框架,是用于全局修改Scrapy Request和Response的一个轻量、底层的系统。
1.5、实体管道(Item Pipeline)
实体管道,用于处理爬虫提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
1.6、Scrapy引擎(Scrapy Engine)
Scrapy引擎是整个框架的核心。它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。
二、Scrapy运行流程
1)当爬虫(Spider)要爬取某URL地址的页面时,使用该URL初始化Request对象提交给引擎(Scrapy Engine),并设置回调函数。
Spider中初始的Request是通过调用start_requests() 来获取的。start_requests() 读取start_urls 中的URL,并以parse为回调函数生成Request 。
2)Request对象进入调度器(Scheduler)按某种算法进行排队,之后的每个时刻调度器将其出列,送往下载器。
3)下载器(Downloader)根据Request对象中的URL地址发送一次HTTP请求到网络服务器把资源下载下来,并封装成应答包(Response)。
4)应答包Response对象最终会被递送给爬虫(Spider)的页面解析函数进行处理。
5)若是解析出实体(Item),则交给实体管道(Item Pipeline)进行进一步的处理。
由Spider返回的Item将被存到数据库(由某些Item Pipeline处理)或使用Feed exports存入到文件中。
6)若是解析出的是链接(URL),则把URL交给调度器(Scheduler)等待抓取。
以上就是Scrapy框架的运行流程,也就是它的工作原理。Request和Response对象是血液,Item是代谢产物。
三、Spiders
在所有的组件中,爬虫(Spider)组件对于用户来说是最核心的组件,完全由用户自己开发。Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取Item)。 换句话说,Spider就是我们定义爬取的动作及分析某个网页(或者是有些网页)的地方。
从Spider的角度来看,爬取的运行流程如下循环:
1)以初始的URL初始化Request,并设置回调函数。 当该Request下载完毕并返回时,将生成Response,并作为参数传给该回调函数。
2)在回调函数内分析返回的(网页)内容,返回 Item 对象或者 Request 或者一个包括二者的可迭代容器。返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数(函数可相同)。
3)在回调函数内,可以使用选择器(Selectors) 来分析网页内容,并根据分析的数据生成Item。
4)最后,由Spider返回的Item将被存到数据库或存入到文件中。