系列目录
- 序篇
- 准备工作
- BIOS 启动到实模式
- GDT 与保护模式
- 虚拟内存初探
- 加载并进入 kernel
- 显示与打印
- 全局描述符表 GDT
- 中断处理
- 虚拟内存完善
- 实现堆和 malloc
- 第一个内核线程
- 多线程运行与切换
- 锁与多线程同步
- 进入用户态
- 进程的实现
- 系统调用
- 简单的文件系统
- 加载可执行程序
- 键盘驱动
- 运行 shell
用户态线程
在前面几篇中,我们已经启动了 kernel 线程并实现了 multi-threads 调度运行。接下来我们需要启动用户线程,毕竟这个 OS 是提供给用户使用的,将来的大多数 thread 也将是用户态的。
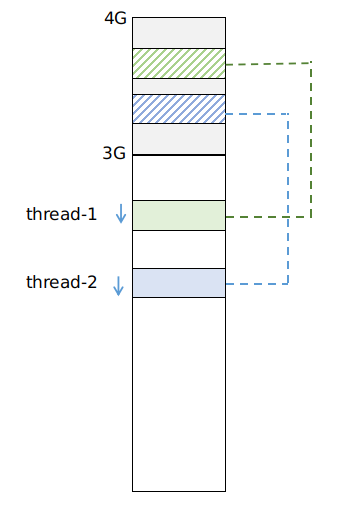
这里需要明晰一下 user 和 kernel 的 thread / stack 之间的关系,可能有的同学对此缺乏一个直观的认知。
- 每一个 user thread 都会有 2 个 stack,分别是 user 空间的 stack 和 kernel 空间的 stack;
- 正常情况下的 user thread,运行在 user stack 上;
- 当发生中断时(包括
interrupt/exception/soft int),执行流跳转到该 thread 的 kernel stack 开始执行中断 handler,执行完毕后再返回到 user stack 恢复执行;
从 kernel thread 启动
需要明确一点,user thread 不是凭空出现的,本质上它仍然需要从 kernel thread 开始运行,然后跳转到用户的 code + stack 上运行。所以这里首先回顾一下 kernel thread 启动的过程,在第一个内核线程一篇中详细讲解过。这里最核心的工作是对 kernel stack 的初始化,我们构建了如下图所示的一个 stack:
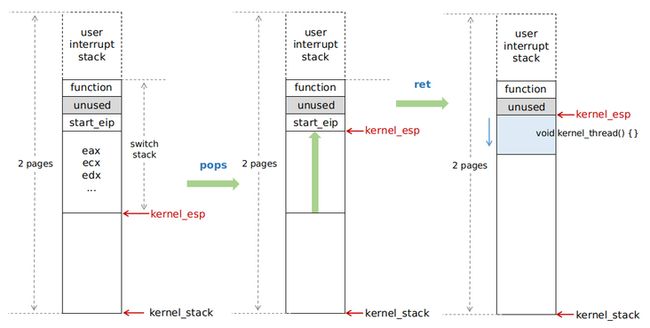
然后从 resume_thread 指令处开始运行,stack 初始位置从 kernel_esp 开始 pop,初始化了各个通用寄存器,并且经过 ret 指令跳转到函数 kernel_thread 开始运行。可以看到 kernel 线程最终是进入 kernel_thread 这个工作函数运行的,并且始终运行在 kernel stack 中(浅蓝色部分)。
如何转入 user 态
从 kernel 进入 user 态,这里要解决两个问题:
- 如何跳转到 user 代码运行,这里需要变换 CPU 特权级,从 0 -> 3;
- 如何跳转到 user stack,它在 3GB 以下 user 空间;
对于问题 1,需要提醒一下,这不是一个普通的 jmp 或者 call 指令就可以做到的。x86 的架构下 CPU 特权级降低的唯一办法是从中断返回,即 iret 指令;
对于问题 2,需要注意进入 user 空间的 stack,需要改变 ss 寄存器的值,是之指向 user 的 data segment(你可能需要复习一下 segment 相关的知识,在全局描述符表 GDT一篇中初始化过);
所以本质上用户 thread 的初始化就是模拟一次从中断返回的过程,如果你还记得中断处理一篇中的中断 stack 的结构:
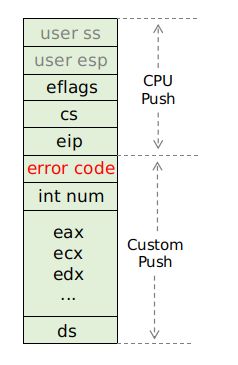
中断 stack 由两部分构成,一部分是 CPU 自动 push 的 registers,一部分是我们在中断 handler 启动时 push 的,整个中断 stack 用如下 struct 描述:
typedef struct isr_params {
uint32 ds;
uint32 edi, esi, ebp, esp, ebx, edx, ecx, eax;
uint32 int_num;
uint32 err_code;
uint32 eip, cs, eflags, user_esp, user_ss;
} isr_params_t;
typedef isr_params_t interrupt_stack_t;这里我们将它重定义为 interrupt_stack_t 结构,以后以此来表示中断 stack;
注意一下 CPU 自动 push 的 stack 部分,它实际上就已经解决了上述两个问题:
- user 代码,保存在了
cs和eip中; - user stack 的位置,保存在了
user esp和user ss中;
一旦调用 iret,上述保存的数据就会自动 pop 出来并跳转,所以我们实际上只要在 kernel stack 里构建一个上述的 interrupt_stack_t 结构,并且设置好这些值,通过一次模拟中断返回,使之能帮助我们“返回”到 user 态。
按惯例,给出本篇的主要源代码,主要是以下几个函数:
它们之间是依次调用的关系,init_thread 函数在启动 kernel thread 那一篇已经用到过,它既用来初始化 kernel thread,现在也用来进一步初始化 user thread,用一个参数开关 user 控制,因为 user thread 也必须以 kernel thread 为基础演化而来。
准备 kernel stack
这里先回顾下 kernel 线程中对 kernel stack 的初始化:

注意上方虚线部分的 user interrupt stack,之前在启动 kernel thread 时我们并没有触及这一块区域,因为 kernel 线程用不到它,而现在我们就需要将它填充为上面的 interrupt_stack_t 结构。
来看 init_thread 函数对这一部分的初始化:
interrupt_stack_t* interrupt_stack =
(interrupt_stack_t*)((uint32)thread->kernel_esp
+ sizeof(switch_stack_t));
// data segemnts
interrupt_stack->ds = SELECTOR_U_DATA;
// general regs
interrupt_stack->edi = 0;
interrupt_stack->esi = 0;
...
// user-level code env
interrupt_stack->eip = (uint32)function;
interrupt_stack->cs = SELECTOR_U_CODE;
interrupt_stack->eflags =
EFLAGS_IOPL_0 | EFLAGS_MBS | EFLAGS_IF_1;
// user stack
interrupt_stack->user_ss = SELECTOR_U_DATA;首先正确定位了 interrupt_stack 的位置,即初始 kernel_esp 上方加一个switch_stack_t 结构大小的位置处;
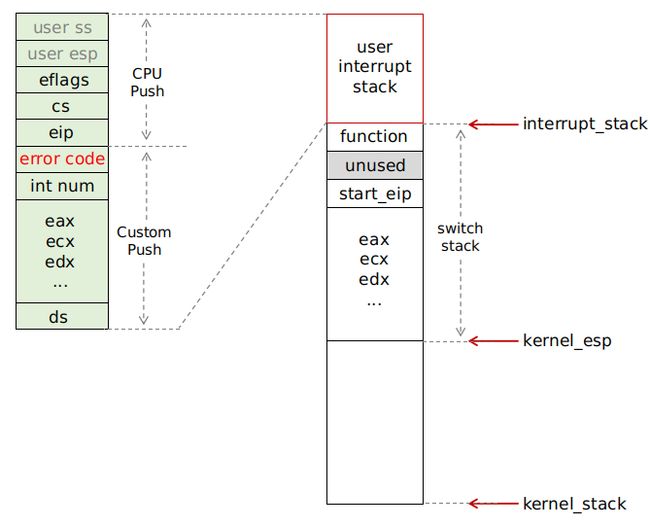
接下来就是对 interrupt stack 中各个 register 的初始化了:
ds初始化为 user 空间的data segment;- 通用寄存器初始化为 0;
cs初始化为 user 空间的code segment;eip初始化为 user thread 的工作函数,这是创建 thread 时传进来的;eflags初始化;user_ss也初始化为 user 空间的data segment;user_esp没初始化,它去哪里了?!这里暂时不初始化,因为 user stack 的位置还待定,它的初始化工作也会放在后面再讲;
启动运行 thread
上面讲过了,user thread 的运行也需要从 kernel thread 开始,所以它们启动的方式是一样的,区别在于 thread_entry_eip 的设置,这里是整个 thread 最初始的入口。
作为对比,如果是运行 kernel 线程,那么 thread_entry_eip 就是被设置为 kernel_thread 工作函数;而这里则被设置为 switch_to_user_mode 函数,来看它的代码,很简单:
switch_to_user_mode:
add esp, 8
jmp interrupt_exit回顾一下 kernel 线程开始运行的过程,在 stack 上从 kernel_esp 位置开始,pop 所有通用寄存器,然后 ret 弹出跳转到 start_eip (即 thread_entry_eip)处,这里即跳转到了 switch_to_user_mode 函数;然后 add esp, 8 跳过两格没用的,使 esp 终于正确地到达了 user interrupt stack 位置:
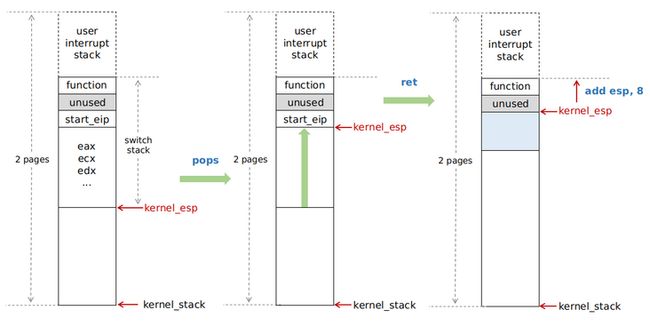
然后开始执行 interrupt_exit 函数,它是中断处理函数 isr_common_stub 的下半部分,即退出中断并恢复中断发生前的 context:
interrupt_exit:
; recover the original data segment
pop eax
mov ds, ax
mov es, ax
mov fs, ax
mov gs, ax
popa
; clean up the pushed error code and pushed ISR number
add esp, 8
; make sure interrupt is enabled
sti
; pop cs, eip, eflags, user_ss, and user_esp by processor
iret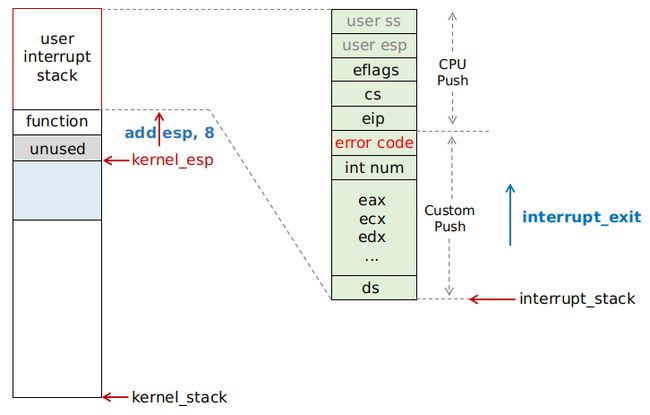
结合 user interrupt stack 的结构图,可以看到它开始“恢复”(其实不是恢复,是我们初始化构造出来的)user context;它解决了之前提到的两个问题,本质上也是我们强调过的关于 thread 的两个核心要素:
- user 代码 (
cs+eip) - user 栈 (
user ss+user esp)
当然 user context 里还包括了 user data segment,通用寄存器,eflags 等寄存器的初始值,这些都一并在这里初始化了。至此,user thread 的运行环境就初始化好了。
这一章节,初看可能会觉得有点乱,你需要好好复习一下关于 segment 的相关内容,以及中断和 kernel 线程初始化和启动的过程。这里本质上要搞清楚 kernel stack 上的两个 stack 的作用:
switch stack:这是 kernel 态下代码运行用的 stack,所有关于这个 thread 的 kernel 代码都在这里运行,并且 multi-threads 之间的 context switch 也发生在这里;interrupt stack:这是 user 态进入和退出 kernel 态的中断栈,是发生中断时由 CPU 和中断 handler 共同构建的;
user 线程的初始化运行过程,本质上就是分为了两步:
- 一开始,和 kernel 线程一样,初始化 kernel thread 运行的环境;
- 但是到了跳转
start_eip的地方,原本的 kernel_thread 的运行函数被换成了 switch_to_user_mode 函数,由它开始模拟中断返回的过程,进入interrupt stack,使之开始布置初始化 user context,并最终跳转到user 态的(code + stack)开始运行;
准备 user stack
上面准备完毕了 kernel stack,使之能以中断返回的形式,跳转进入用户 code + stack 上执行。不过我们的 user stack 还没准备好,这块区域也需要进行简单的初始化。
首先需要指定 user stack 的位置,一般来说它位于 3GB 空间的顶部区域:
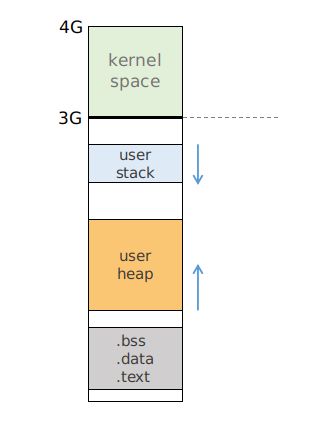
user stack 的位置理应是由这个 thread 的 process 管理的,不过目前我们并未开始构建 process 相关的内容,这里作为测试,我们可以暂时随意指定 user stack 的位置。在实际的 create_new_user_thread 函数中,会传入参数 process,指定这个 thread 应该创建在哪一个 process 下,而 process 会为这个 user thread 分配一个 user 空间的 stack 位置。
tcb_t* create_new_user_thread(pcb_t* process,
char* name,
void* user_function,
uint32 argc,
char** argv);这样同一个 process 下的多个 threads,它们的 user stack 大致是这样排布,不可以有重叠:
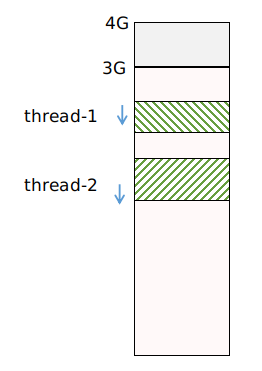
有了 user stack 的位置以后,我们就可以初始化这个 stack。user thread 的运行本质上是一次函数调用,所以它的 stack 初始化没有什么特殊之处,就是构建一个函数的调用栈,主要是两个部分:
- 参数
- 返回地址
接下来我们将这两部分内容初始化。
复制参数
参数是在 create_new_user_thread 函数就传入的 argc 和 argv。不过我们需要将他们 copy 到 user stack 上,这样 user_function 就可以以它们为参数运行起来,这其实就是我们平常的 C 程序里的 main 函数的形式:
int main(int argc, char** argv);当然 main 函数只是进程的主 thread,如果在进程中继续创建新的 thread,本质上也是类似的形式,例如常用的 pthread 库,都会涉及到 thread 函数和参数的传递:
int pthread_create(pthread_t *thread,
pthread_attr_t *attr,
void *(*start_routine)(void *),
void *arg); 复制参数的过程主要在函数 prepare_user_stack 中实现。这里涉及到参数 argv 的构建,它是一个字符串数组,所以我们先把 argv 里所有的字符串都 copy 到 user stack 的顶部,并记下它们的起始地址,使之构成一个 char* 数组,再让 argv 指向这个数组。指针之间的关系稍微有点绕,可以结合下图可以看一下:
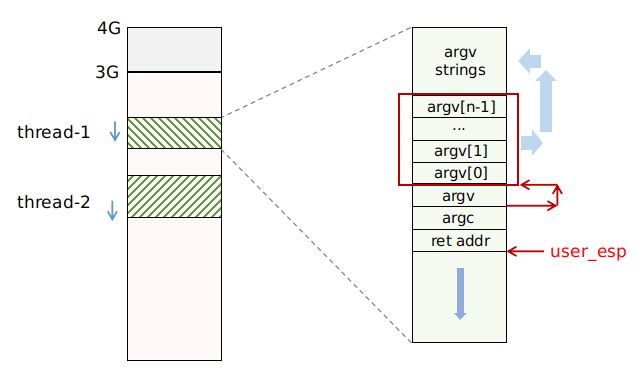
thread 结束返回
最后还剩下一个 ret addr 没有设置,它是 thread 结束后的返回地址。
这里我们需要问自己一个问题,一个 thread 结束后,应该做什么?CPU 指令流当然要继续往下走,不能就此终止了,也不能跑飞了。所以 thread 工作函数返回后必然是跳转到某处,由 kernel 对它进行最后的回收工作,这个 thread 的生命周期就算结束了,然后 scheduler 调度运行下一个 thread。
其实这个问题之前也提到过的,在 kernel 线程中,之所以我们需要用函数 kernel_thread 封装一下,就是因为 thread 需要有一个统一的退出机制:
void kernel_thread(thread_func* function) {
function();
schedule_thread_exit();
}schedule_thread_exit 就是 thread 结束后的退出机制,它不会返回,而是进入 kernel 的结束和回收流程。它的主要工作是将该 thread 的相关资源进行释放,然后标记自己状态为 TASK_DEAD,接下来调用 scheduler 调度服务,scheduler 发现它是 TASK_DEAD 就会将它清理,并调度运行下一个 thread。
所以我们是不是只要将 user stack 上的 thread 返回地址设置为 schedule_thread_exit 就 OK 了呢?答案是错误的。
因为 schedule_thread_exit 是 kernel 代码,user 态下是无法直接调用的,否则会报 segment 错误。user 空间的 code segment 范围被限定在了 3GB 以下,并且特权级 CPL 是 3,它不可能调用 3GB 以上,且 DPL 为 0 的 kernel 代码(你可能又需要去复习一下 segment 的内容)。
那么如何才能从 user 态进入 kernel 态并最终调用 schedule_thread_exit 函数呢?答案是中断,或者更准确地说,是 系统调用(system call)。关于系统调用的内容,将放在以后的文章中详细展开,在这里只需要知道,user 态下的 thread 结束方式,应该是运行一个大致是这样的函数:
void user_thread_exit() {
// This is a system call.
thread_exit();
}系统调用 thread_exit 会带领我们进入 kernel 态,并最终来到 schedule_thread_exit 函数执行 thread 结束清理工作。
看上去很完美,然而这里又带来一个新的问题,上面的 user_thread_exit 只是我们假定的,或者说希望有这么一个函数。实际上 user 的程序代码是用户自己编写的,然后从磁盘上载入运行的,里面是否真的有这么一个函数,是 kernel 不可能知晓的。那我们实际上陷入了一个悖论,导致 kernel 永远无法为 user thread 设置一个有效的,user 态下可以调用的 类似 user_thread_exit 的函数,用于作为 user 线程的 ret addr。
对于这个问题,我也没有仔细研究过,不知道标准的解决方案是什么。我的实现方法是,完全摒弃 user stack 上的 ret addr,也就是说 user thread 的工作函数也永远不返回,而是封装成一个类似 kernel_thread 的函数里,例如叫 user_thread 好了:
void user_thread(thread_func* function,int argc, void** argv) {
function(argc, argv);
thread_exit();
}但实际上我们无法强制用户按照这个规范去创建 user 线程,所以 user 态下的线程创建,不应该让用户直接操作底层的系统调用,而是应该由相应的规范的库函数去封装,例如 pthread,然后用户再去调用这些库函数,进行对 thread 的相关操作。在这些库函数里,它们会将用户传进来的工作函数 function 和参数,都封装到 user_thread 这样的符合规范的 user 线程函数中,然后再调用 OS 提供的,用于创建 thread 的系统调用。
那至于 main 函数,它也是一个线程,它的退出机制就比较好解决,也是类似的,必须将 main 也封装在一个函数中:
void _start(int argc, void** argv) {
main(argc, argv);
thread_exit();
}_start 函数就是这个上层的封装函数,实际上它才是真正的用户程序的入口函数,它理论上应该由标准库提供,在 C 程序 link 时,将它链入并设置为 ELF 可执行文件的入口地址。
设置 tss
user 线程的初始化和结束工作都 OK 了,看上去一切准备就绪,不过其实还有一个遗漏的坑没填上。之前讲过 user 态下如果发生中断,CPU 会自动进入 kernel stack 进行中断处理(当然如果 user thread 永远不中断,那就没有这个需求,但这是不可能的。最典型的,时钟中断会持续不断地发生,page fault也是不可避免的)。

这个从 user 到 kernel 的跳转过程是 CPU 自动完成的,是由硬件决定的。那么问题来了,CPU 怎么知道这个 thread 的 kernel stack 在哪里呢?
答案是 tss(task state segment),关于这个东西实在是冗长繁琐,我也不想在这里赘述。目前只需要知道将这个结构设置到 gdt 中,并且将线程的 kernel stack 设置到它的 esp0 字段上即可,这样 CPU 每次陷入 kernel 态时,就会找到这个 tss 结构,并且按照 esp0 字段,定位 kernel stack 的位置。
tss初始化相关的代码在 write_tss 这个函数;- 记得每次 thread 切换,scheduler 都需要更新 tss 的
esp0字段的值,使之指向新 thread 的 kernel stack 的顶部(高地址):
void update_tss_esp(uint32 esp) {
tss_entry.esp0 = esp;
}
void do_context_switch() {
// ...
update_tss_esp(next_thread->kernel_stack + KERNEL_STACK_SIZE);
// ...
}总结
本篇的内容稍微有些复杂,也是关于 thread 的最终篇,涉及到的内容很广泛,可能需要复习 segment,中断,以及 kernel 线程创建+启动过程等内容,将它们串联起来。趟过了这一关,相信你会对 thread 在 OS 中的运行机制会有一个全面的理解,这包括以下几个关键点:
- user 和 kernel 线程 / stack 的关系,以及它们各自的作用;
- user 和 kernel 态的转换是如何发生和返回的,code + stack 如何跳转;
- kernel stack 在线程启动时,中断发生、处理和返回时,context switch 时的结构图,和它所发挥的作用;
下一篇,我们将在 thread 的基础上,定义进程(process) 的概念。