浅谈GPU虚拟化和分布式深度学习框架的异同

撰文 | 袁进辉
经常有人来问我:GPU虚拟化和分布式深度学习框架的异同,以及是不是用GPU虚拟化技术也可以解决现在超大规模深度学习模型的分布式训练难题。
这次不妨把我的观点简要总结并分享出来,只想知道结论的朋友只需看简短的答案:两者不是一回事,二者的思想是对立的,GPU虚拟化对解决分布式训练深度学习模型的难题没有任何作用(不谈负作用的话)。
想知道原因的读者请继续阅读下文。
1
GPU虚拟化
GPU虚拟化的主要出发点是,有些计算任务的颗粒度比较小,单个任务无法占满整颗GPU,如果为每一个这样的任务单独分配一颗GPU并让这个任务独占,就会造成浪费。因此,人们希望可以让多个细粒度的任务共享一颗物理的GPU,同时,又不想让这些任务因共享资源互相干扰,也就是希望实现隔离。
因此,GPU 虚拟化要实现“一分多”,也就是把一颗物理的GPU分成互相隔离的几个更小的虚拟GPU,也就是vGPU,每颗vGPU独立运行一个任务,从而实现多个任务共享一颗物理的GPU。
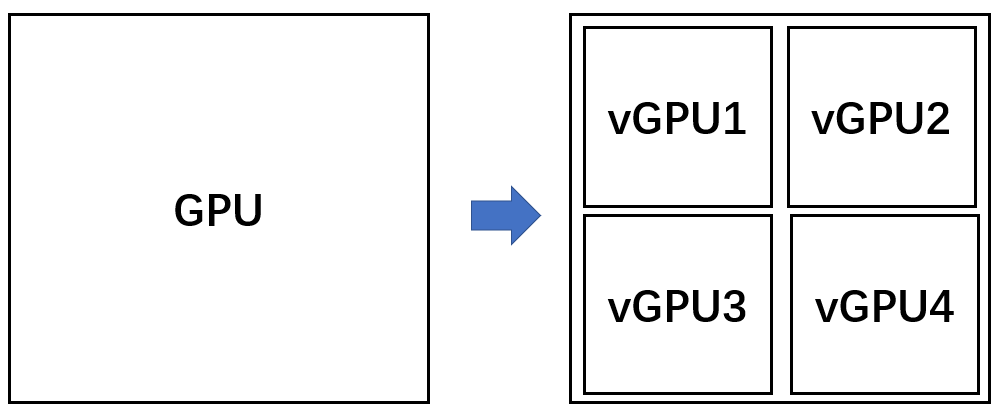
GPU虚拟化在推理任务中有需求,这是因为推理任务的负载取决于服务请求的多寡,在服务请求的低谷,推理需要的计算时有时无,多个不同的推理任务通过GPU虚拟化共享资源说的通。
在模型调试环节或教学环境,GPU虚拟化也有需求,算法工程师或学生每改一次代码就启动一次任务,这个任务或者因为错误很快就停止,或者被工程师杀死,不会持续的需要资源,如果每个人独占一颗GPU,势必造成浪费。因此,把一颗GPU虚拟化成多颗vGPU,大家轮流使用,这样比较经济划算。
一般来说,正式的深度学习训练任务计算量都比较大,唯恐资源不够,而不是发愁资源多余,因此GPU虚拟化在训练过程中不太需要。在正式训练中如果出现 GPU 利用率不高的时候,采取的措施往往是对训练进程进行 profiling,找出 GPU 处于 idle 的原因,比如 io、通信、cpu 计算,而不是切分 GPU。
GPU虚拟化可能为云计算的“超售”带来机会,可以让任务在资源池中“飘来飘去”。总之,GPU虚拟化主要是为了解决资源利用率不足的问题。
当然,解决GPU共享不一定必须借助GPU虚拟化。譬如,和一位业内朋友讨论时,他提出一种设计:在推理服务框架(例如Triton)层次本身就可以实现池化并实现多任务共享GPU。这种办法相对于GPU虚拟化不太云原生,但在处理同一个公司内部多个业务时也有自身的优点。
GPU虚拟化的实现方法有多种可能,推荐感兴趣的读者阅读文末腾讯团队写的一篇深度文章《GPU虚拟化、算力隔离和qGPU》。
其中,最简单的一种方式是 API 劫持,基本思路是把NVIDIA 的API提供一套同名的实现,用户程序原本是直接调用NVIDIA实现的函数,现在却“神不知鬼不觉地”把用户对NVIDIA函数的调用换成对自己这一套函数的调用(用户程序并不需要修改),在自己这一套函数里对可使用的资源数量施加一些限制,再把调用转发给真正的NVIDIA版函数。可以看出,这是一个工作量比较大且繁琐,但技术上却并不高深的做法。
2
分布式深度学习
最理想的分布式深度学习框架是:用户面对多机多卡编程时,不需要考虑这些GPU之间复杂的拓扑和数据传输,仍然像面对一个单体的“超级芯片”一样编程,单卡的代码和多卡的代码一致,同时,这些GPU协作时整体的利用率接近100%,也就是实现线性加速比。实际上,这方面恰恰是OneFlow最大的优势。

可见,分布式深度学习需要的是“多合一”,与GPU虚拟化的“一分多”截然不同。
如果说二者有一点相仿,仅仅是在用多个卡“模仿”一个卡,以及一个卡“模仿”多个卡,在”模仿”的字面意思上相似,但在核心难题和实现途径上截然不同。要实现“多合一”的目标,恰恰要去虚拟化(这里的虚拟化也就是引入抽象层的意思)。如果有人声称GPU虚拟化可以在训练任务上实现“多合一”,那一定是忽悠外行的。
为什么这么说呢?
首先,虚拟化追求的是任务无感(task agnostic),也就是什么任务,这个任务怎么来使用GPU,都不关心,也无法知晓,资源的划分和隔离方法都是确定不变的。但深度学习框架要做好,必须是任务相关的,框架都要深入分析每一个任务,并为这个任务和资源配额编译生成一个特别的执行方案(譬如有的是数据并行,有的模型并行、流水并行等等)。相信技术同行比较容易理解这一点。
其次,虚拟化追求的是任务可以在资源池中“飘来飘去”,但深度学习训练任务和资源的对应关系都不得不静态固化下来,也就是所谓的静态至上。
很多人应该已经注意到了,绝大部分深度学习训练场景,资源都是独占的。这明明不符合“云计算”的思想,为什么他们知道这不明智还要这么做?
那真的只是因为不得不这样。
第一,深度学习训练作业中的诸多计算都是毫秒、数十毫秒级别,动态调度必然引入运行时做决策的开销,这些开销即使在其它场合微不足道,在深度学习里相对于数十毫秒的任务粒度来说都不可忽视。那么干脆把能在运行前固定下来的都定下来,不要在运行时做决策,譬如静态的placemet,静态的任务切分等等,无所不用其极。
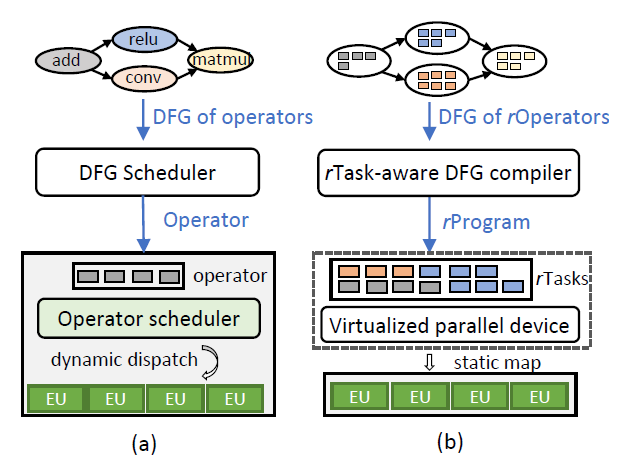
熟悉微软去年发表在OSDI上的Rammer论文的朋友应该注意到了,其静态调度方案中,每个Kernel在GPU 的哪些流处理器上执行都是定下来的(上图b子图中的static map)。
第二,深度学习训练任务中包含大量的数据传输,GPU之间的传输带宽通常比片上访存带宽低非常多,因此数据传输的开销非常大,为了提高设备利用率,必须想办法把计算和传输通过流水线重叠起来,也就是把传输的时间掩盖到计算背后。
为了实现这种“重叠”,无非是消费者“预取”,或者是生产者“预发送”。而在“预取”中,消费者必须知道生产者所在的位置才可行,而在“预发送”中,生产者必须知道消费者所处的位置才可行。如果任务在集群中飘来飘去,生产者不能提前知道消费者在哪里,也就无从谈起“预发送”了,重叠计算和传输就变得不可能。
第三,多个深度学习任务共享资源,可能会互相干扰,使得每个任务的执行时间不可预测,发生抖动,形成straggler,使得整体系统的性能下降,得不偿失。
分布式深度学习训练从根本上是排斥“飘来飘去”的,要求是静态的、独占的,这恰恰与虚拟化的精神相悖。
总之,从编程接口的角度看,OneFlow的一致性视角,把多机多卡“虚拟化”成一个超级芯片,大大降低了用户编写分布式深度学习程序的难度。但是,为了让用户从计算效率上也感觉是在一个超级芯片上工作,恰恰需要“去虚拟化”的手段,要为每一个不同的任务都编译得到不一样的资源映射方案,而且这个映射方案是静态的,不鼓励飘来飘去。
最后,全世界从事深度学习框架研发的人群的数量远超从事GPU虚拟化的人群,在研发面向AI基础架构的群体里,绝大多数水平最拔尖的工程师也是工作在深度学习框架这个赛道里,而不是其它方向。深度学习框架,毫无争议地是人工智能领域里最重要的基础设施软件。
推荐阅读:关于GPU共享的文章,这里给出一篇腾讯资深工程师的博客链接,感兴趣的读者可以在同一个仓库中找到其它几篇关联内容。
GPU共享一:你真的需要吗?
(https://github.com/zw0610/zw0610.github.io/blob/master/notes-cn/gpu-sharing-1.md)
注:题图源自Pixabay
其他人都在看
OneFlow v0.4.0 正式发布
动态调度的“诅咒”③
数据搬运的“诅咒”②
资源依赖的“诅咒”①
训练GPT-3,为什么原有的深度学习框架吃不消?
点击“阅读原文”,欢迎下载体验OneFlow新一代开源深度学习框架

![]()