《高性能Mysql》学习笔记(一)
前言
Mysql的质量比较好的书其实并不是很多,所以可以说是看一本少一本,这本书也算是学习MYSQL必看的一本书,当然十分厚,虽然版本很老但是讲述的内容都会十分实用的,对于学习MYSQL的人可以说是一本必读的进阶好书。
最后,这篇读书笔记是整理个人以前自学的时候看书做的笔记,做的十分粗糙=-=,现在来看很多笔记记得过于基础了。另外当时很多都是截图的,很多都是图片HHHH(流量观看慎重)。
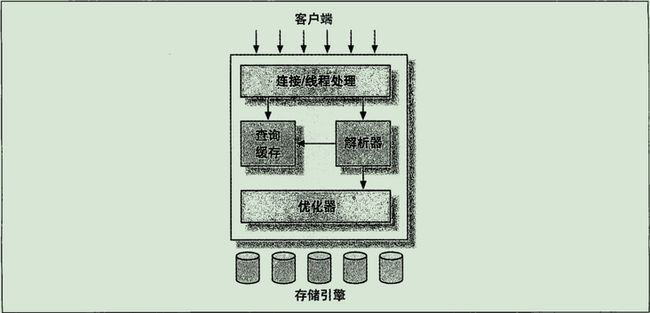
MySQL逻辑架构图
虽然看上去比较复古,但是挺经典的。
小贴士:
存储引擎不会去解析sql, 不同存储引擎不会相互通信,只是简单响应上层请求(InnoDB引擎除外,会解析外键定义,因为mysql服务器本身没有实现该功能)
连接管理和安全性
每一个连接都是一个单独线程,服务器会对连接缓存而不是创建或者销毁线程
优化与执行
执行流程:
- 解析查询
- 创建数据结构(解析树),优化(重写查询,读表顺序优化,选择索引等)
- 尝试查询缓存(SELECT)
- 返回结果
并发控制
目的:内部拥有锁机制防止数据破坏
共享锁和排他锁(读锁和写锁)
- 读锁是共享的,相互不阻塞
- 写锁是排他的,一个写锁会阻止其他读锁和写锁
锁粒度
提高共享资源并发性就是让锁更有选择性,让锁只监控部分数据
记住:任何时候,给定资源下,锁定数据量越少,并发程度越高,只要相互不发生冲突即可
mysql提供多个存储引擎支持丰富的锁策略
表锁 (table lock)
表锁是msyql中最基本的锁策略,开销最小的策略,这种方式类似邮箱的加锁机制:会锁定整张表,用户访问时候,对表进行写操作,需要优先获得写锁,会阻塞其他用户读写操作,只有没有写锁时候,其他用户才能获得读锁,读锁之间是不相互阻塞的,特定场景表锁可以有良好性能。
注意事项:
- 写锁比读锁有更高的优先级,写锁有可能会插入到一个读锁的前面,但是读锁不能插入到写锁队列前面
- 服务器会为alter table 等语句默认使用表锁而不是根据引擎决定(虽然存储引擎才是真正干活的)
行级锁 (row lock)
该锁可以最大程度支持并发处理(与此同时带来巨大锁开销),InnoDB和XtraDB, 实现了行级锁,行级锁只在存储层也就是存储引擎实现,而mysql服务层没有实现
事务
事务的ACID
A(atomicity) 原子性
- 一个事务是一个不可分割的单位,事务中的所有操作,要么全完成,要么全不完成,任何一个操作的失败,都会回滚到事务执行之前的状态。
C (consistency) 一致性
- 事务结束后,系统状态是一致的。即,在并发操作时,系统的状态也要和串行执行事务时一样。
I (isolation)隔离性
- 并发执行的事务之间,无法看到彼此的系统状态。
D (durability)持续性
- 在事务完成后,事务对数据库的操作会被持久保存在数据库中,不会被回滚。
事务使用与否根据实际业务情况而定(甚至可以不使用事务,而是使用sql 进行一定的安全措施),如何选择合适的 mysql 引擎来解决问题可能事务本身更加重要。
隔离级别

死锁
如果多个线程同时更改同一行数据,你们两个线程互相等待对面的锁,造成死锁
解决方法:
- 例如:InnoDB 检测死循环依赖,并且立即返回一个错误(死锁会造成慢查询)。
- 查询时间达到锁等待超时设定时间之后放弃锁请求。
- InnoDB目前(5.1)处理方法:将持有最少行级排他锁的事务进行回滚。
- 大多数时候因为数据冲突,有时候确实是因为存储引擎方式引起的!!!
只有部分或者完全回滚一个事务才能打破死锁,事务性系统无法避免。 大多数时候只需要重新执行死锁事务即可
事务日志
事务日志采用追加方式,因此I/O的消耗比较小,内存修改数据后台慢慢刷会磁盘,目前大多数存储引擎都是这样实现被称为:预写式日志
mysql中的事务
- innoDB
- NDB cluster
自动提交
默认情况下我们所写的SQL默认都是自动提交的,也就是说在执行的时候MYSQL都会给我们自定加上一条,COMMIT语句,也就是自动提交事务,我们可以使用SHOW VARIABLES LIKE 'AUTOCOMMIT'语句查看是否开启自动提交。

切记:查找对应版本会产生 AUTO_COMMIT 所有语句
设置隔离级别
命令如下:
> SET SESSION TRASACTION ISOLATTION LEVEL READ COMMITTED
mysql 可以识别 4 个 ansi 隔离级别,innodb 引擎也支持
混合使用存储引擎
mysql 服务层不管理事务,事务下层存储引擎实现,同一个事务使用多种存储引擎不可靠
mysql 对非事务型表不会有提示!!!!
mysql 对非事务型表不会有提示!!!!
mysql 对非事务型表不会有提示!!!!
隐藏和显式锁定
记住下面的两条特点:
- INNODB 使用两阶段锁定协议,锁只有在执行提交或者回滚才会释放
- INNODB 会根据隔离级别自动加锁
innodb支持显示的加锁如下:
SELECT ... FROM IN SHARE MODESELECT ... FOR UPDATE
注意:这不是sql规范,而是MYSQL自己增加的语法支持
mysql 中的lock 和 unlock tables 语句和存储引擎无关,而是在服务层实现,不能用来替代事务性存储引擎,有其他用途
建议:除了事务中禁用autocommit ,可以使用lock tables 之外,其他任何时候不要显式执行 lock tables,不管是什么存储引擎
多版本并发控制(mvcc)
mvcc实现:保存数据在某个时间点的快照实现,记住:根据事务开始时间不同,每个事务对同一张表,同一时刻看到的数据可能是不一样的,这里可以引申:悲观锁和乐观锁
innodb 的 mvvc
实现原理:通过在每行记录后面保存两个隐藏的列实现
- 一个列保存行创建时间
- 另一个保存过期时间(删除时间)
事务开始时候系统版本号(每个新事务都会递增版本号)作为事务版本号,和查询到记录的版本号比较
REPEATABLE READ 隔离级别操作

MVCC 只在 REPEATABLE READ 和 READ COMMITTED 两个隔离级别工作。
mysql 存储引擎
- 建表时候,会在
mytable.frm中定义表定义。 - 表的定义是在服务层。
- 不同系统存储形式不一样(数据和索引)。
使用show table status命令 显示表的相关信息,例如 show table status like 'user' \G,mysql5.1中的innodb plugin 支持一些新特性(BLOB存储方式使用),mysql5.1一定要使用 innodb plugin ,比 旧innodb要好得多
mysql 5.5 之后 innodb plugin 才替换掉旧的 Innodb
Innodb 概览
mysql4.1 之后新特性
- innodb 可以将每个表的数据和索引放在单独文件当中
- innodb 可以将裸设备作为存储介质
Innodb 特点
- 使用mvcc 支持高并发
- 实现了四个标准隔离级别(默认级别为 REPEATABLE READ(可重复读))。
- 使用间隙锁(next-key locking) 策略防止幻读的出现。
- 间隙锁不仅锁定查询行,还对索引进行锁定。
- INNODB 基于 聚簇索引 建立。
- 存储格式是平台独立的,意味着可以跨平台使用。
- 内部进行优化,可预测性预读,可以自动在内存当中创建hash索引加速读操作自适应哈希索引,加速操作的加入缓冲区。
- 阅读官方文档"InnoDB 事务模型和锁"了解更多内容。
- innodb 通过一些机制和工具实现真正的热备份。
聚簇索引 对于主键查询有非常高的性能,不过二级索引中必须包含主键列, 如果主键列很大,其他所有索引都会很大,
Myisam 存储引擎
mysql5.1 之前默认使用 MyISAM 作为存储引擎
特点:
- 全文索引,压缩,空间函数
- 不支持事务和行级锁
- 崩溃之后无法安全恢复
存储:
将表存储在两个文件当中
- 数据文件 ( .MYD )
- 索引文件 ( .MYI )
- 表支持包含动态或者静态(长度固定)行,mysql根据表定义决定存储形式
- Mysql5 当中,如果是变长行,只能处理256TB 数据
- 修改Myisam 表指针长度, 修改表 max_rows 和 avg_row_length 选项实现
myisam特性
- 加锁与并发:对整张表加锁,而不是针对行。
- myisam 表, mysql 可以手工或者自动检查和修复操作(但是效率较低)。
- 索引特性:即使是BLOB 和 TEXT等长字段,也可以基于500 个字符创建。
- myisam 支持全文索引,基于分词创建索引。
- 延迟更新索引键。
myisam 压缩表
如果表中数据不再修改,可以使用myisam 压缩表,作用是减少磁盘i/o, 提高查询性能。
myisam 性能问题
最典型的性能问题是 表锁 的问题
mysql 内建其他存储引擎
Archive 引擎
- 只支持 insert 和 sleect, mysql5.1 之前不支持索引。
- 适合日志和数据采集类应用。
- 支持行级锁和专用缓冲区,实现高并发插入。
- 不是事务性引擎,只对告诉插入和压缩做了优化的简单引擎。
Blackhole 引擎
- 无存储,丢弃所有插入数据。但是服务器会记录blackhole 表的日志。
- 简单的日志引擎。
CVS 引擎
- 将普通cvs 作为mysql 表处理,不支持索引。
- cvs 引擎可以作为 数据交换的机制(excel 表格的转换)。
Federated 引擎
- 访问其他mysql 服务器代理,但是默认是禁用的。
Memory引擎
- 可以快速访问数据 使用 Memory 表。
- 所有数据都是在内存当中。
- 每行长度固定。
- 并发性能较低。
作用:
- 查找或者映射表。
- 缓存周期性聚合数据。
- 保存数据产生的中间数据。
- 如果mysql 查询使用临时表保存结果,你们内部使用就是Memory 表,但是如果数据量较大,就会转为myisam 表
Merga 引擎
- myisam 引擎变种,多个myisam 表合并变种
- 分区功能实现后,被放弃
NDB 集群引擎
- 用于mysql 集群
第三方存储引擎
OLTP 类引擎
- XtraDB引擎
- PBXT引擎
- TokuDB 引擎
如何选择引擎
除非使用到了innodb 不具备的特性,并且无法替代,否则优先选择innodb
主要看待四点
- 事务
- 备份
- 崩溃恢复
- 特有特性
个人看法:
- 对于极高的插入数据要求时候,可以使用myisam 或者archieve
- 如果不知道其他引擎的特性还是建议INNODB
测试崩溃数据恢复问题就是模拟电源断电!!!
数据表引擎转换
1. 直接转换
mysql> ALTER TABLE mytable ENGINE = InnoDB
这种方式性能很低,而且会加锁
2. 使用导入导出的方法
导入与导出:使用msyql 工具导出sql 语句然后手动修改引擎
3. 创建与查询
mysql > create table innodb_table like myisam table;
mysql > alter table innodb_table engine = InnoDB;
mysql > insert into innodb_table select * from myisam_table4. 数据量很大的话可以分批处理
start transaction;
insert into innodb_table select * from myisam_table
where id between x and y;
insert into innodb_table select * from myisam_table
where id between x and y;
insert into innodb_table select * from myisam_table
where id between x and y;
.......
commit总结
第一篇读书笔记主要介绍了和MYSQL的存储引擎的重点内容,以及简单介绍MYSQL 的事务相关内容,在前言也说过,内容比较基础并且由于以前偷懒很多都是截图书上的内容=-=。