从零开始制作语义分割数据集
1. 安装labelme
labelme是一款十分好用的语义分割数据集制作软件,可用于自定义数据集的标注。labelme是用Python语言编写的,项目地址。具体的安装十分简单,步骤如下:
- 安装依赖
pip install pyqt5 -i https://pypi.douban.com/simple/2. 安装labelme
pip install labelme -i https://pypi.douban.com/simple/安装完成后,在终端中输入labelme,即可打开软件,界面如下。
![]()
2. 标注图像
labelme标注图像的过程与目标检测的labelimg软件的使用方法类似,点击open dir,选择需要标注图像的路径,即可开始标注。
标注完成后,图像文件路径下会生成同名的json文件,如下图所示:

打开json文件,具体内容如下,关键的参数包括:
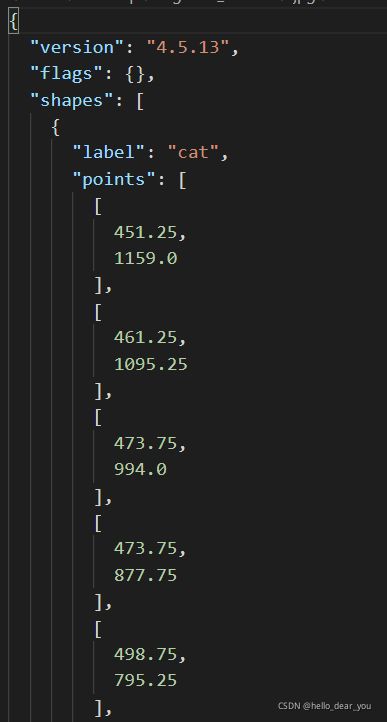
- label:表示区域内物体的类别
- points:表示围成物体区域的点集
3. 可视化标注
获取到json文件之后,利用labelme提供工具labelme_json_to_dataset将json文件生成对应的标注文件
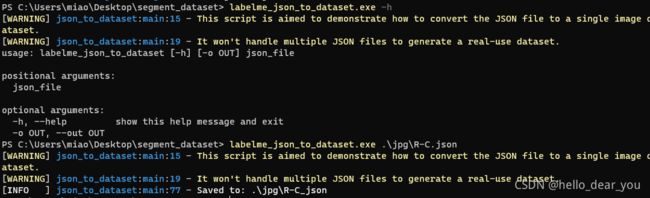
此时会得到一个与json文件同名的文件夹,里面包含标注文件
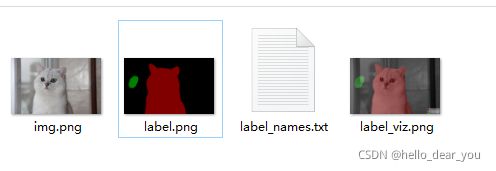
其中每个文件的含义如下:
- img.png:图像原图
- label.png:标注得到的语义图像
此时生成的标签只是当前图像包含类别的局部标注信息,详细来说就是,假设语义分割任务需要分割三个类别(cat,person, dog),那么对应的全局的标注文件上,背景所属区域的像素值为0,cat对应区域的像素值为1,person对应区域的像素值为2,dog对应区域的像素值为3. 但是在单个图像中,每个类别对应的像素值是随机的,由你在标注当前图像的类别顺序决定,因此在标注完成之后,需要转换为全局类别标签
- label_names.txt:图像中包含的类别信息
- label_viz.png:标注可视化防止标注错误
下面重点分析一下label.png图像,用像素查看软件,可以看到background的像素值为0,猫对应区域的像素值为1,而绿色区域为狗的像素值为2。
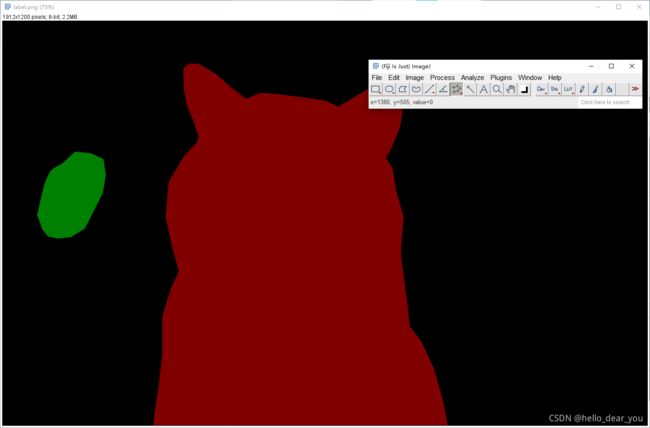
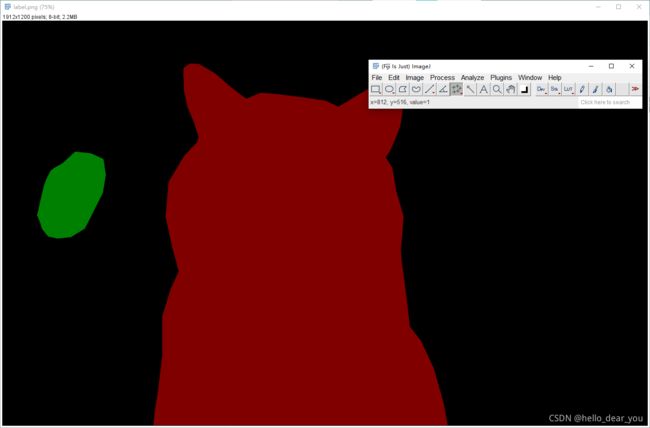

当前labelme中提供的工具只能逐个转换图像,并不提供全部转换的脚本,通过参考labelme项目下的json_to_dataset.py脚本和参考链接中的第二篇文章,编写了如下代码来转换所有的标注文件。
# json_to_dataset.py
import argparse
import json
import os
import os.path as osp
import warnings
import imgviz
import PIL.Image
import yaml
from labelme import utils
import base64
def main():
count = os.listdir("./before/")
for i in range(0, len(count)):
path = os.path.join("./before", count[i])
# 找到before文件中以json为结尾的文件并且打开
if os.path.isfile(path) and path.endswith('json'):
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl, _ = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
# captions = ['{}: {}'.format(lv, ln)
# for ln, lv in label_name_to_value.items()]
# lbl_viz = utils.labelme_shapes_to_label(lbl, img, captions)
label_names = [None] * (max(label_name_to_value.values()) + 1)
for name, value in label_name_to_value.items():
label_names[value] = name
lbl_viz = imgviz.label2rgb(
lbl, imgviz.asgray(img), label_names=label_names, loc="rb"
)
out_dir = osp.basename(count[i]).replace('.', '_')
out_dir = osp.join(osp.dirname(count[i]), out_dir)
out_dir = osp.join("output",out_dir)
if not osp.exists(out_dir):
os.mkdir(out_dir)
# image
PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png'))
# label.png
utils.lblsave(osp.join(out_dir, 'label.png'), lbl)
# PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png'))
# label_viz.png
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, "label_viz.png"))
with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n')
# warnings.warn('info.yaml is being replaced by label_names.txt')
# info = dict(label_names=label_names)
# with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
# yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir)
if __name__ == '__main__':
main()
-
before文件夹中包含了原始图像和json文件
- output文件夹中得到转换后的结果
4. 生成全局标签文件
由上述的介绍可知,每个图像得到的label.png文件中的标签只是局部标签,需要将其转换为全局的标签,第一步需要准备一个包含全局类别的txt文件class_name.txt放在before文件下,本例子中的内容如下:

第二步是通过下面提供的draw_label_png.py文件得到最终的结果。【需要注意的是最终生成的标注文件png,应该是单通道的而不是RGB图像】
import os
from PIL import Image
import numpy as np
# 文件路径处理
root = os.getcwd()
before = os.path.join(root, "before")
output = os.path.join(root, "output")
assert(os.path.exists(before)), "please check before folder"
assert(os.path.exists(output)), "please check output folder"
jpg = os.path.join(root, "jpg")
png = os.path.join(root, "png")
if not os.path.exists(jpg):
os.mkdir(jpg)
if not os.path.exists(png):
os.mkdir(png)
def main():
# 读取原文件夹
count = os.listdir("./before/")
for i in range(0, len(count)):
# 如果里的文件以jpg结尾
# 则寻找它对应的png
if count[i].endswith("jpg"):
path = os.path.join("./before", count[i])
img = Image.open(path)
img.save(os.path.join("./jpg", count[i]))
# 找到对应的png
path = "./output/" + count[i].split(".")[0] + "_json/label.png"
img = Image.open(path)
# 找到全局的类
class_txt = open("./before/class_name.txt","r")
class_name = class_txt.read().splitlines()
# ["bk","cat","dog"] 全局的类
# 打开x_json文件里面存在的类,称其为局部类
with open("./output/" + count[i].split(".")[0] + "_json/label_names.txt","r") as f:
names = f.read().splitlines()
# ["bk","dog"] 局部的类
# 新建一张空白图片, 单通道
new = Image.new("P", (img.width, img.height))
# 找到局部的类在全局中的类的序号
for name in names:
# index_json是x_json文件里存在的类label_names.txt,局部类
index_json = names.index(name)
# index_all是全局的类,
index_all = class_name.index(name)
# 将局部类转换成为全局类
# 将原图img中像素点的值为index_json的像素点乘以其在全局中的像素点的所对应的类的序号 得到 其实际在数据集中像素点的值
# 比如dog,在局部类(output/x_json/label_names)中它的序号为1,dog在原图中的像素点的值也为1.
# 但是在全局的类(before/classes.txt)中其对应的序号为2,所以在新的图片中要将局部类的像素点的值*全局类的序号,从而得到标签文件
new = new + (index_all*(np.array(img) == index_json))
new = Image.fromarray(np.uint8(new))
# 将转变后的得到的新的最终的标签图片保存到make_dataset/png文件夹下
new.save(os.path.join("./png", count[i].replace("jpg","png")))
# 找到新的标签文件中像素点值的最大值和最小值,最大值为像素点对应的类在class_name.txt中的序号,最小值为背景,即0
print(np.max(new),np.min(new))
if __name__ == '__main__':
main() 通过上述过程,可以得到最终用于训练的语义分割数据集,制作过程总体的文件结构如下:
- before:包含原始图像和标注的json文件
- jpg:原始图像
- output:局部标注文件
- png:全局标签文件(用于最终的训练)
参考链接
wkentaro/labelme: Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation). (github.com)
https://github.com/wkentaro/labelmejson返回的img图片被原样输出_语义分割中单类别和多类别图片数据标注,以及灰度类别转换..._weixin_39939661的博客-CSDN博客