数据挖掘导论 笔记5
其他分类模型
基于规则的分类器
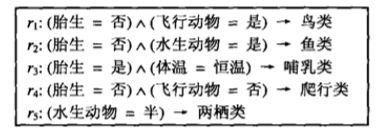
ri是规则,R=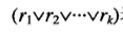 是规则集
是规则集
每一个分类规则可以表示为形式![]()
规则左边称为规则前件(rule antecedent)或前提(precondition)。它是属性测试的合取,即
![]()
规则右边称为规则后件(rule consequent),包含预测类yi
分类规则的质量可以用覆盖率(coverage) 和准确率(accuracy) 来度量
覆盖率定义为D中满足规则r的记录所占的比例
准确率或置信因子定义为类标号等于y占触发r的比例

基于规则的分类器的工作原理
互斥规则(Mutually Exclusive Rule)如果规则集R中不存在两条规则被同一条记录触发,则称规则集R中的规则是互斥的。这个性质确保每条记录至多被R中的一条规则覆盖。
简单来说就是不能有矛盾。
穷举规则(Exhaustive Rule)如果对属性值的任一组合,R中都存在一条规则加以覆盖,则称规则集R具有穷举覆盖。这个性质确保每一条记录都至少被R中的一条规则覆盖。
简单来说就是每个数据都要有可以参照的规则。
这两个性质共同作用,保证每一条记录被且仅被一条规则覆盖。
然而,很多基于规则的分类器,都不满足这两个性质。
1.如果规则集不是穷举的,那么必须添加一个默认规则ri:()→yd来覆盖那些未被覆盖的记录。默认规则的前件为空,当所有其他规则失效时触发。yd是默认类,通常被指定为没有被现存规则覆盖的训练记录的多数类。
2.如果规则集不是互斥的,那么一条记录可能被多条规则覆盖,这些规则的预测可能会相互冲突。解决这个问题有如下两种方法。
(1)有序规则(ordered rule) 在这种方法中, 规则集中的规则按照优先级降序排列,优先级的定义有多种方法(如基于准确率、覆盖率、总描述长度或规则产生的顺序等)。有序的规则集也称为决策表(decision list)。 当测试记录出现时,由覆盖记录的最高秩的规则对其进行分类,这就避免由多条分类规则来预测而产生的类冲突的问题。
(2)无序规则(unordered rule)这种方法允许一条测试记录触发多条分类规则,把每条被触发规则的后件看作是对相应类的一次投票, 然后计票确定测试记录的类标号。通常把记录指派到得票最多的类。
在某些情况下,投票可以用规则的准确率加权。使用无序规则来建立基于规则的分类器有利也有弊。首先,无序规则方法在分类一个测试记录时,不易受由于选择不当的规则而产生的错误的影响(而基于有序规则的分类器则对规则排序方法的选择非常敏感)。其次,建立模型的开销也相对较小,因为不必维护规则的顺序。然而,对测试记录进行分类却是一件很繁重的任务,因为测试记录的属性要与规则集中的每一条规则的前件作比较。
本章主要讨论第一种
规则的排序方案
1.基于规则的排序方案
这个方案依据规则质量的某种度量对规则排序。这种排序方案确保每一个测试记录都是由覆盖它的“最好的”规则来分类。该方案的潜在缺点是规则的秩越低越难解释,因为每个规则都假设所有排在它前面的规则不成立。
2.基于类的排序方案
在这种方案中,属于同一个类的规则在规则集R中一起出现。然后,这些规则根据它们所属的类信息一起排序。同一个类的规则之间的相对顺序并不重要,只要其中一个规则被激发,类标号就会赋给测试记录。这使得规则的解释稍微容易一些。然而,质量较差的规则可能碰巧预测较高秩的类,从而导致高质量的规则被忽略。

本章主要是介绍基于规则的分类器
如何建立基于规则的分类器
1.规则提取的直接方法
顺序覆盖
比如对于脊椎动物分类问题,顺序覆盖算法可能先产生对鸟类进行分类的规则,然后依次是哺乳类、两栖类、爬行类,最后是鱼类的分类规则。决定哪一个类的规则最先产生的标准取决于多种因素,如类的普遍性( 即训练记录中属于特定类的记录的比例),或者给定类中误分类记录的代价。

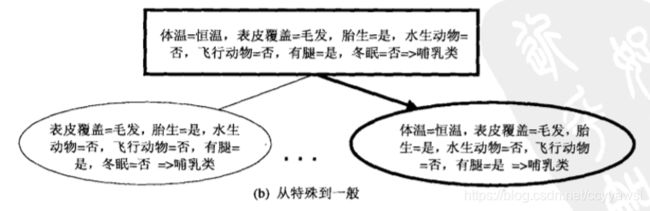
图5-2演示在包含-组正例和反例的数据集上顺序覆盖算法是怎样工作的。规则R1首先被提取出来,(覆盖如图5-2b所示)因为它覆盖的正例最多。接下来去掉R1覆盖的所有训练记录,算法继续寻找下一一个最好的规则,即R2。
Learn-One-Rule函数
Learn-One-Rule函数的目标是提取一个分类规则,该规则覆盖训练集中的大量正例,没有或仅覆盖少量反例Learn-One- Rule函数通过以一 种贪心的方式的增长规则来解决指数搜索问题。它先产生一个初始规则r,并不断对该规则求精,直到满足某种终止条件为止。然后,修剪该规则,以改进它的泛化误差。
规则增长策略常见的分类规则增长策略有两种:从一般到特殊和从特殊到一般。
1.在从一般到特殊的策略中,先建立一个初始规则r:{}->y,其中左边是一个空集,右边包含目标类。该规则的质量很差,因为它覆盖训练集中的所有样例。接着加入新的合取项来提高规则的质量。图5-3a显示脊椎动物分类问题的从一般到特殊的规则增长策略。合取项体温=恒温首先被选择作为规则的前件。算法接下来探查所有可能的候选,并贪心地选择下一个合取项胎生=是,将其添加到规则的前件中。继续该过程,直到满足终止条件为止(例如,加入的合取项已不能提高规则的质量)。
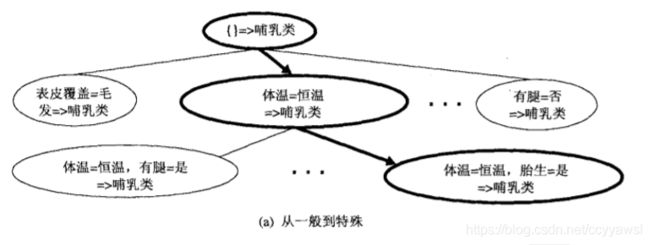
2.对于从特殊到一般的策略,可以随机地选择一个正例作为规则增长的初始种子。在求精步,通过删除规则的一个合取项,使其覆盖更多的正例来泛化规则。图5-3b给出了脊椎动物分类问题的从特殊到一般的方法。假设选择哺乳类的一个正例作为初始种子。初始规则与种子的属性值包含相同的合取项。为了提高覆盖率,删除合取项冬眠=否,以泛化规则。重复求精步,直到满足终止条件为止。
例如,当规则开始覆盖反例时停止。由于规则的贪心的方式增长,以上方法可能会产生次优规则。为了避免这种问题,可以采用束状搜索( beam search)。 算法维护k个最佳候选规则,各候选规则各自在其前件中添加或删除合取项而独立地增长。评估候选规则的质量,选出k个最佳候选进入下一轮迭代。
规则评估
在规则增长过程中,需要一种评估度量来确定应该添加(或删除)哪个合取项。
准确率就是一个很明显的选择,因为它明确地给出了被规则正确分类的训练样例的比例。然而,把准确率作为标准的一个潜在的局限性是它没有考虑规则的覆盖率。例如,考虑一个训练集, 它包含60个正例和100个反例。假设有如下两个候选规则。
规则r1:覆盖50个正例和5个反例。
规则r2:覆盖2个正例和0个反例。
r和r2的准确率分别为90.9%和100%。然而,r1是较好的规则,尽管其准确率较低。r2的高准确率具有潜在的欺骗性,因为它的覆盖率太低了。
简单来说,准确率和覆盖率都要考虑到。
解决方法
**(1)**可以使用统计检验剪除覆盖率较低的规则。
例如,我们可以计算下面的似然比( likelihoodratio)统计量:
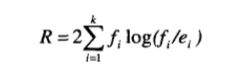
其中,k是类的个数, fi是被规则覆盖的类i的样本的观测频率, ei是规则作随机猜测的期望频率。

20.625就是55个里面期望有20.625个正类
50是这55个里面实际有50个正类

由此,r1比r2好。
**(2)**可以使用一种考虑规则覆盖率的评估度量。
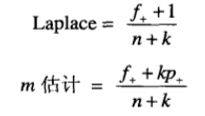
其中n是规则覆盖的样例数,f+是规则覆盖的正例数,k是类的总数,p+是正类的先验概率。
在规则的覆盖率很高时,两个度量都渐近地趋向于规则的准确率f+/n.回到前面的例子,r1的Laplace度量为51/57 = 89.47%,很接近它的准确率。相反,r2的Laplace度量(75%)比它的准确率小很多,这是因为r2 的覆盖率太小了。
**(3)**另一种可以使用的评估度量是考虑规则的支持度计数的评估度量
FOIL信息增益(FOIL’s information gain)就是一种这样的度量。规则的支持度计数对应于它所覆盖的正例数。假设规则r:A→+覆盖Po个正例和no个反例。增加新的合取项B,扩展后的规则r :A^B→+覆盖p1个正例和n1个反例。根据以上信息,扩展后规则的FOIL信息增益定义为:
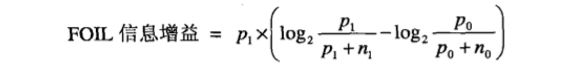
上例中r1和r2的FOIL信息增益分别为63.87和2.83,因此规则r1比r2好。
最近邻分类器
积极学习方法:如果训练数据可用,它们就开始学习从输入属性到类标号的映射模型,建立模型。
与之相反的策略是推迟对训练数据的建模,直到需要分类测试样例时再进行。采用这种策略的技术被称为消极学习方法(lazy learner)。消极学习的一个例子是Rote分类器(Rote clasifier),它记住整个训练数据,仅当测试实例的属性和某个训练样例完全匹配时才进行分类。该方法一个明显的缺点是有些测试记录不能被分类,因为没有任何训练样例与它们相匹配。
使该方法更灵活的一个途径是找出和测试样例的属性相对接近的所有训练样例。这些训练样例称为最近邻(nearest neighbor),可以用来确定测试样例的类标号。使用最近邻确定类标号的合理性。
用下面的谚语最能说明:“如果走像鸭子,叫像鸭子,看起来还像鸭子,那么它很可能就是一只鸭子。”
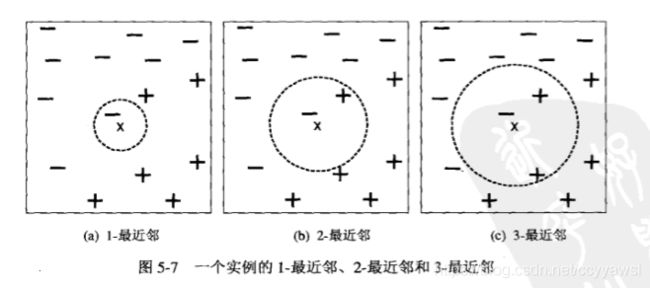
最近邻分类器把每个样例看作d维空间上的一个数据点,其中d是属性个数。使用2.4节中介绍的任意一种邻近性度量,计算该测试样例与训练集中其他
数据点的邻近度。给定样例z的k个最近邻是指和z距离最近的k个数据点。
如果数据点的近邻中含有多个类标号,则将该数据点指派到其最近邻的多数
a -
b ±都行
c +
前面的讨论中强调了选择合适的k值的重要性。如果k太小,则最近邻分类器容易受到由于训练数据中的噪声而产生的过分拟合的影响;相反,如果k太大,最近邻分类器可能会误分类测试样例,因为最近邻列表中可能包含远离其近邻的数据点。

降低k的影响的一种途径就是根据每个最近邻x距离的不同对其作用加权: w=1/d(x’,x).
结果使得远离z的训练样例对分类的影响要比那些靠近z的训练样例弱一些。 使用距离加权表决方案,类标号可以由下面的公式确定:
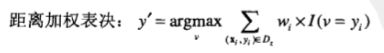
贝叶斯分类器
贝叶斯定理
![]()
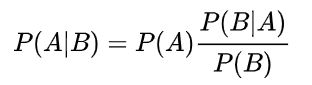
贝叶斯定理
2.贝叶斯定理在分类中的应用
设X表示属性集,Y表示类变量。如果类变量和属性之间的关系不确定,那么我们可以把X和Y看作随机变量,用P(Y|X)以概率的方式捕捉二者之间的关系。这个条件概率又称为Y的后验概率(postcrior probability),与之相对地,P(Y)称为Y的先验概率(prior probability)。
在训练阶段,我们要根据从训练数据中收集的信息,对X和Y的每一种组合学习后验概率P(Y|X)。知道这些概率后,通过找出使后验概率P(Y’| X )最大的类Y’可以对测试记录X进行分类。
为了解释这种方法,考虑任务:预测一个贷款者是否会拖欠还款。图5-9中的训练集有如下属性:有房、婚姻状况和年收入。拖欠还款的贷款者属于类Yes,还清贷款的贷款者属于类No。假设给定一测试记录有如下属性集: X=(有房=否,婚姻状况=已婚,年收入= $120K)。要分类该记录,我们需要利用训练数据中的可用信息计算后验概率P(Yes|X)和 P(No|X)。 如果P(Yes|X)> P(No]X), 那么记录分类为Yes,反之,分类为No。

准确估计类标号和属性值的每一种可能组合的后验概率非常困难,因为即便属性数目不是很大,仍然需要很大的训练集。此时,贝叶斯定理很有用,因为它允许我们用先验概率P(Y)、类条件(class-conditional)概率P(X|Y)和证据P(X)来表示后验概率:
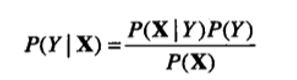
在比较不同Y值的后验概率时,分母P(X)总是常数,因此可以忽略。先验概率P(Y)可以通过计算训练集中属于每个类的训练记录所占的比例很容易地估计。对类条件概率P(X|Y)的估计,我们介绍两种贝叶斯分类方法的实现:朴素贝叶斯分类器和贝叶斯信念网络。
简单来说就是减少了所需数据的数量。所需问题就剩P(X|Y)的计算。
朴素贝叶斯分类器
给定类标号y,朴素贝叶斯分类器在估计类条件概率时假设属性之间条件独立。条件独立假设可形式化地表述如下:
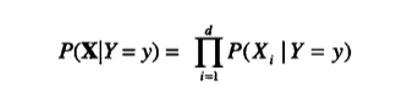
其中每个属性集X= {X1, X2, … Xa}包含d个属性。
条件独立性

Z发生时,X与Y是否发生两者无关。
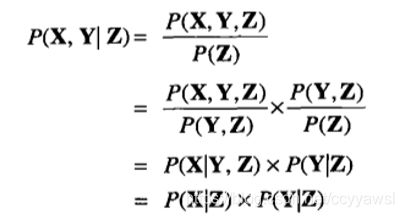
上面的公式得到下面的公式的最后一行。
分类测试记录时,朴素贝叶斯分类器对每个类Y计算后验概率:
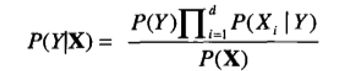
由于对所有的Y, P(X)是固定的,因此只要找出使分子
估计分类属性的条件概率
最大的类就足够了。在接下来的两部分,我们描述几种估计分类属性和连续属性的条件概率P(X|Y)的方法。
对分类属性X,根据类y中属性值等于x的训练实例的比例来估计条件概率P(X= xi|Y=y)。例如,在图5-9给出的训练集中,还清贷款的7个人中3个人有房,因此,条件概率P(有房=是|No)等于3/7。同理,拖欠还款的人中单身的条件概率P(婚姻状况=单身|Yes)= 2/3。
估计连续属性的条件概率
连续属性和分类属性不一样,对于服从正态分布的连续属性,分布有两个参数,均值μ和方差σ^2。
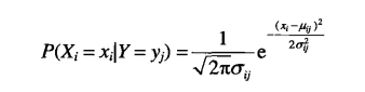
朴素贝叶斯分类器举例
eg.
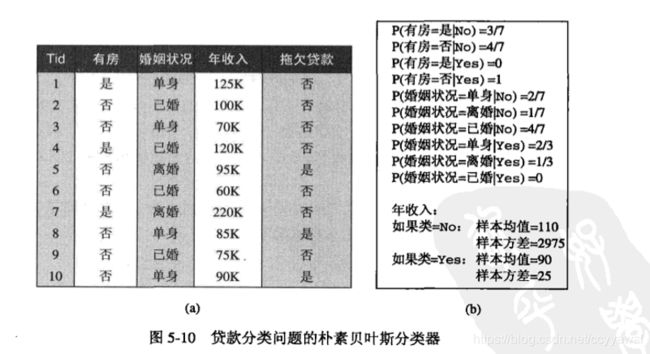
P(Yes)=0.3,P(No)= 0.7

P(No|X)= a0.70.0024 = 0.00160,其中a= 1/P(X);
P(Yes|X)=a0.30=0
所以判定不拖欠贷款。
条件概率的m估计
前面的计算过程显示出一个问题,如果有一个属性的类条件概率等于0,则整个类的后验概率就等于0。
很多情况下数据集不能覆盖各种“属性的组合情况”,为了规避这个问题我们引入条件概率的m估计。

其中,n是类yi中的实例总数,nc 是类yi的训练样例中取值xi的样例数,m是称为等价样本大小的参数,而p是用户指定的参数。
如果没有训练集(即n=0),则P(xi|yi)=p。
因此p可以看作是在类yj的记录中观察属性值xi的先验概率。等价样本大小决定先验概率p和观测概率nc/n之间的平衡。
使用m估计方法,m=3,p= 1/3,则条件概率不再是0:
m一般取和n相等的大小 n是有三个yes nc是三个yes里没有已婚的
P(婚姻状况=已婚|Yes)= (0 + 3x1/3)/(3+ 3)= 1/6

尽管分类结果不变,但是当训练样例较少时,m估计通常是一种更加健壮的概率估计方法。
朴素贝叶斯分类器的特征
1.面对孤立的噪声点,朴素贝叶斯分类器是健壮的。因为在从数据中估计条件概率时,这些点被平均。通过在建模和分类时忽略样例,朴素贝叶斯分类器也可以处理属性值遗漏问题。
2.面对无关属性,该分类器是健壮的。如果X;是无关属性,那么P(X{Y)几乎变成了均匀分布。X的类条件概率不会对总的后验概率的计算产生影响。
3.相关属性可能会降低朴素贝叶斯分类器的性能,因为对这些属性,条件独立的假设已不成立。
贝叶斯误差率
eg.
假设我们知道支配P(X|Y)的真实概率分布。
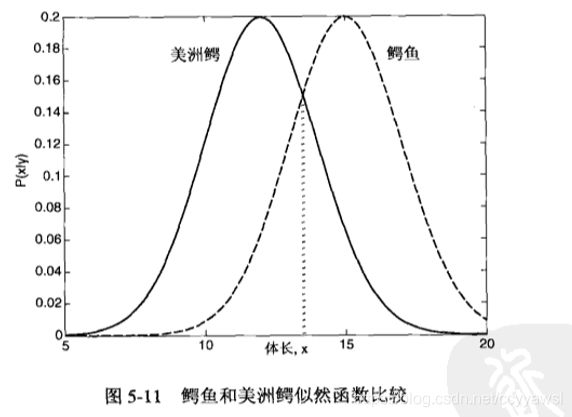
考虑任务: 根据体长区分美洲鳄和鳄鱼。一条成年鳄鱼的平均体长大约15 英尺,而一条成年美洲鳄的体长大约12英尺。假设它们的体长x服从标准差为2英尺的高斯分布,那么二者的类条件概率表示如下:

图5-11给出了鳄鱼和美洲鳄类条件概率的比较。假设它们的先验概率相同,理想决策边界x^满足:
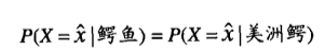
(理想决策边界就是两个正态分布的交点,落在边界左右是不同的决策。)
先验概率相等,消去,可以得到
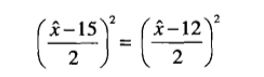
解得x^=13.5
当先验概率不一样时,决策边界朝着先验概率较小的类移动
因为P(X|鳄鱼)*P(鳄鱼)=P(X|美洲鳄)*P(美洲鳄)
若P(鳄鱼)>P(美洲鳄)
则P(X|鳄鱼)>P(X|美洲鳄)
(因为e^是在分母上)
则x^离12近一些离15远一些才可以减小P(X|美洲鳄)
所以往小先验概率偏移。
误差率就是二者交界的部分面积和:
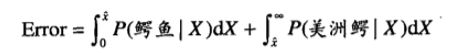
总误差率称为贝叶斯误差率
贝叶斯信念网络
对那些属性之间有一定相关性的分类问题,有更灵活的类条件概率P(X)的建模方法。该方法不要求给定类的所有属性都条件独立,而是允许指定哪些属性条件独立。
模型表示
贝叶斯信念网络( Bayesian belief networks, BBN), 简称贝叶斯网络,用图形表示一组随机变量之间的概率关系。贝叶斯网络有两个主要成分。
(1)一个有向无环图(dag), 表示变量之间的依赖关系。
(2)一个概率表,把各结点和它的直接父结点关联起来。
三个随机变量A. B和C,其中A和B相互独立,并且都直接影响第三个变量C.
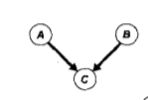
性质1:条件独立
贝叶斯网络中的一个结点,如果它的父母结点已知,则它条件独立于它的所有非后代结点。
除了网络拓扑结构要求的条件独立性外,每个结点还关联一个概率表。
(1)如果结点X没有父母结点,则表中只包含先验概率P(X)。
(2)如果结点X只有一个父母结点Y,则表中包含条件概率P(X|Y)。
(3)如果结点X有多个父母结点{Y, Y2," Yk},则表中包含条件概率P(X|Y1, Y2,……,Yk)。
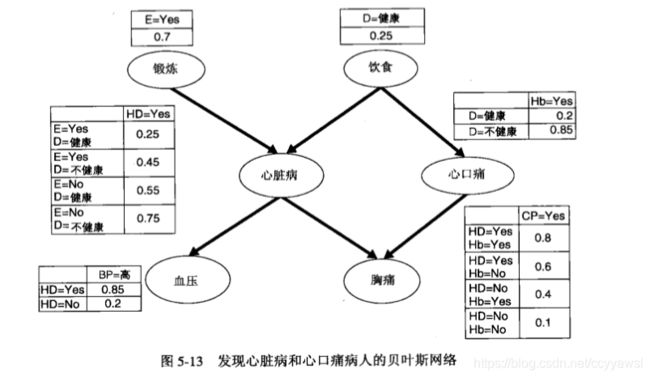
使用BBN进行推理
情况一:没有先验信息
在没有任何先验信息的情况下,可以通过计算先验概率P(HD=Yes)和P(HD=No)来确定一个人是否可能患心脏病。为了表述方便,设a∈{Yes, No}表示锻炼的两个值,β∈{健康,不健康}表示饮食的两个值。
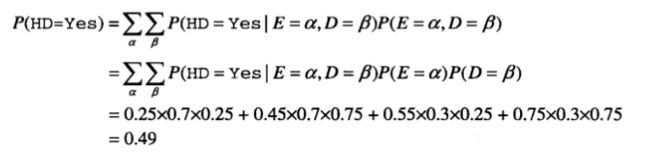
简而言之就是把各个情况下HD=Yes的概率求和。
情况二:已知高血压
如果一个人有高血压,可以通过比较后验概率P(HD=Yes |BP=高)和P(HD=No I BP=高)来诊断他是否患有心脏病。为此,我们必须先计算分母P(BP=高):

之后就有

注意到,这里的计算需要分母。
情况三:高血压、饮食健康、经常锻炼身体
假设得知此人经常锻炼身体并且饮食健康。加上这些新信息,此人患心脏病的后验概率:

第三行就是 有心脏病的条件下高血压概率/ 高血压概率
人工神经网络(ANN)
感知器
考虑图5-14中的图表。左边的表显示一个数据集,包含三个布尔变量(x, x,划)和一个输出变量y,当三个输入中至少有两个是0时,y取-1,而至少有两个大于0时,y取+1.
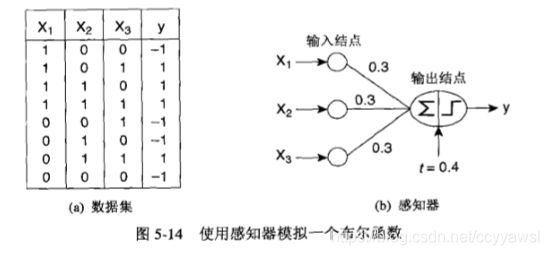
图5-14b就是一个简单的神经网络结构一感知器。
感知器包含两种结点:几个输入结点,用来表示输入属性; 一个输出结点,用来提供模型输出。
神经网络结构中的结点通常叫作神经元或单元。
在感知器中,每个输入结点都通过一个加权的链连接到输出结点。这个加权的链用来模拟神经元间神经键连接的强度。训练一个感知器模型就相当于不断调整链的权值,直到能拟合训练数据的输入输出关系为止。
感知器对输入加权求和,再减去偏置因子t,然后考察结果的符号,得到输出值y.
图5-14b中的模型有三个输入结点,各结点到输出结点的权值都等于0.3,偏置因子t= 0.4.模型的输出计算公式如下: .
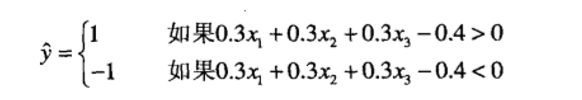
w为权值,x为输入的数据,那感知器模型的输出可以用如下数学方式表示:

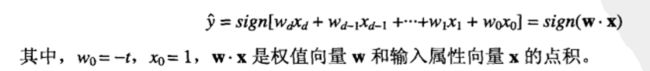
在感知器模型的训练阶段,权值参数w不断调整直到输出和训练样例的实际输出一致。
算法:

算法的主要计算是第7步中的权值更新公式:
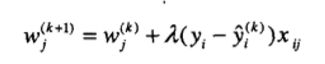
xij是第i个数据集的第j个数据,λ是学习率,人自行决定。
如果y=+1,y‘=-1,那么预测误差(y-y‘)=2。为了补偿这个误差,需要通过提高所有正输入链的权值、降低所有负输入链的权值来提高预测输出值。
如果y=-1,y’=+ 1,那么预测误差(y-y’)=-2。为了补偿这个误差,我们需要通过降低所有正输入链的权值、提高所有负输入链的权值来减少预测输出值。
权值不能改变太大,因为仅仅对当前训练样例计算了误差项。否则的话,以前的循环中所作的调整就会失效。学习率λ在0和1之间,可以用来控制每次循环时的调整量。如果A接近0,那么新权值主要受旧权值的影响;相反,如果λ接近1,则新权值对当前循环中的调整量更加敏感。
在某些情况下,可以使用一个自适应的λ值:在前几次循环时值相对较大,而在接下来的循环中逐渐减小。
多层人工神经网络
人工神经网络结构比感知器模型更复杂。这些额外的复杂性来源于多个方面。
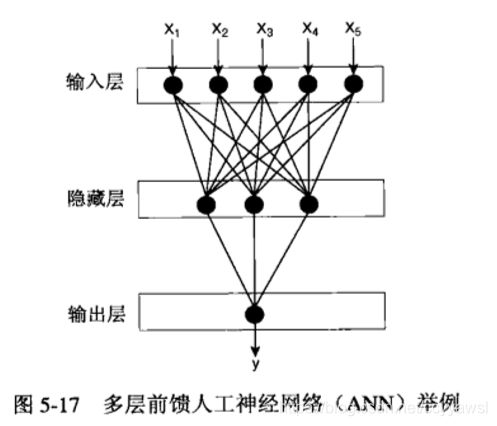
(1) 网络的输入层和输出层之间可能包含多个中间层,这些中间层叫作隐藏层(hidden layer),隐藏层中的结点称为隐藏结点(hidden node)。这种结构称为多层神经网络(见图5-17)。
在前馈(feed-forward)神经网络中,每一层的结点仅和下一层的结点相连。感知器就是一个单层的前馈神经网络,因为它只有一个结点层一输出层一 进行复杂的数学运算。
在递归(recurrent)神经网络中,允许同一层结点相连或一层的结点连到前面各层中的结点。
(2)除了符号函数外,网络还可以使用其他激活函数,如图5-18所示的线性函数、S型(逻辑斯缔)函数、双曲正切函数等。这些激活函数允许隐藏结点和输出结点的输出值与输入参数呈非线性关系。.

这些附加的复杂性使得多层神经网络可以对输入和输出变量间更复杂的关系建模。例如,考虑上一节中描述的XOR问题。实例可以用两个超平面进行分类,这两个超平面把输入空间划分到各自的类,如图5-19a所示。
因为感知器只能构造一个超平面,所以它无法找到最优解。该问题可以使用两层前馈神经网络加以解决,见图5-19b。直观上,我们可以把每个隐藏结点看作一个感知器,每个感知器构造两个超平面中的一个,输出结点简单地综合各感知器的结果,得到的决策边界如图5-19a所示。

学习ANN模型
ANN学习算法的目的是确定一组权值 w,最小化误差的平方和:

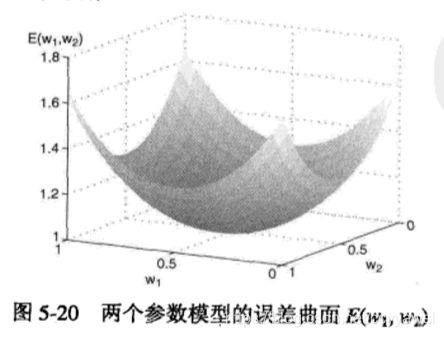
E(w)反应误差大小。
大多数情况下,由于激活函数的选择(如s型或双曲正切函数), ANN的输出是参数的非线性函数。这样,就不能直接推导出w的全局最优解了。像基于梯度下降的方法等贪心算法可以很有效地求解优化问题。梯度下降方法使用的权值更新公式可以写成:
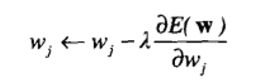
其中,λ是学习率。式中第二项说的是权值应该沿着使总体误差项减小的方向增加。
由于误差函数是非线性的,梯度下降方法可能会陷入局部极小值。
梯度下降方法可以用来学习神经网络中输出结点和隐藏结点的权值。对于隐藏结点,学习的计算量并不小,因为在不知道输出值的情况下,很难估计结点的误差项dE/0w。一种称为反向传播(back propagation)的技术可以用来解决该问题。该算法的每一次迭代包括两个阶段: 前向阶段和后向阶段。在前向阶段,使用前一次迭代所得到的权值计算网络中每一个神经元的输出值。
计算是向前进行的,即先计算第k层神经元的输出,再计算第k+1层的输出。在后向阶段,以相反的方向应用权值更新公式,即先更新k+1层的权值,再更新第k层的权值。使用反向传播方法,可以用第k+1层神经元的误差来估计第k层神经元的误差。
ANN学习中的设计问题
在训练神经网络来学习分类任务之前,应该先考虑以下设计问题。
(1)确定输入层的结点数目。每一个数值输入变量或二元输入变量对应-一个输入结点。如果输入变量是分类变量,则可以为每一个分类值创建一一个结点,也可以用[log2k个输入结点对k元变量进行编码。
(2)确定输出层的结点数目。对于2-类问题,-一个输出结点足矣;而对于k-类问题,则需要k个输出结点。
(3)选择网络拓扑结构(例如,隐藏层数和隐藏结点数,前馈还是递归网络结构)。注意, 目标函数表示取决于链上的权值、隐藏结点数和隐藏层数、结点的偏置以及激活函数的类型。找出合适的拓扑结构不是件容易的事。-种方法是,开始的时候使用一一个有足够多的结点和隐藏层的全连接网络,然后使用较少的结点重复该建模过程。这种方法非常耗时。另一种方法是,不重复建模过程,而是删除一些结点,然后重复模型评价过程来选择合适的模型复杂度。
(4)初始化权值和偏置。随机赋值常常是可取的。
(5)去掉有遗漏值的训练样例,或者用最合理的值来代替。
人工神经网络的一般特点概括如下。
(1)至少含有一个隐藏层的多层神经网络是-种普适近似( universal approximator),即可以
用来近似任何目标函数。由于ANN具有丰富的假设空间,因此对于给定的问题,选择合适的拓
扑结构来防止模型的过分拟合是很重要的。
(2) ANN可以处理冗余特征,因为权值在训练过程中自动学习。冗余特征的权值非常小。
(3)神经网络对训练数据中的噪声非常敏感。处理噪声问题的一-种方法是使用确认集来确定
模型的泛化误差,另一种方法是每次迭代把权值减少-一个因子。
(4) ANN权值学习使用的梯度下降方法经常会收敛到局部极小值。避免局部极小值的方法是在权值更新公式中加上-一个动量项(momentum term)。
(5)训练ANN是一个很耗时的过程,特别是当隐藏结点数量很大时。然而,测试样例分类时非常快。
支持向量机
支持向量机(support vector machine, SVM)这种方法具有一个独特的特点,它使用训练实例的一个子集来表示决策边界,该子集称作支持向量(supportvector )。
为了解释SVM的基本思想,首先介绍最大边缘超平面(maximal margin hyperplane)的概念以及选择它的基本原理。然后,描述在线性可分的数据上怎样训练-一个线性的SVM,从而明确地找到这种最大边缘超平面。最后,介绍如何将SVM方法扩展到非线性可分的数据上。
1.最大边缘超平面
图5-21显示了一个数据集,包含属于两个不同类的样本,分别用方块和圆圈表示。这个数据集是线性可分的,即可以找到这样一个超平面分开这两部分。然而可能存在无穷多个那样的超平面。虽然它们的训练误差都等于零,但是不能保证这些超平面在未知实例上运行得同样好。根据在检验样本上的运行效果,分类器必须从这些超平面中选择一个来表示它的决策边界。
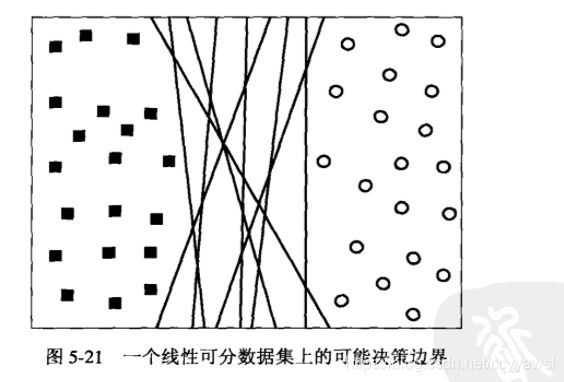
为了更好地理解不同的超平面对泛化误差的影响,考虑两个决策边界B1和B2,如图5-22所示。
这两个决策边界都能准确无误地将训练样本划分到各自的类中。每个决策边界B;都对应着一对超平面,分别记为b1和b2。其中,ba 是这样得到的:平行移动一个和决策边界平行的超平面,直到触到最近的方块为止:类似地,平行移动一个和决策边界平行的超平面,直到触到最近的圆圈,可以得到b2。这两个超平面之间的间距称为分类器的边缘。
B1的边缘显著大于B2的边缘。在这个例子中,B1就是训练样本的最大边缘超平面。
线性模型的能力与它的边缘逆相关。具有较小边缘的模型具有较高的能力,因为与具有较大边缘的模型不同,具有较小边缘的模型更灵活、能拟合更多的训练集。然而随着能力增加,泛化误差的上界也随之提高。因此,需要设计最大化决策边界的边缘的线性分类器,以确保最坏情况下的泛化误差最小。线性SVM (linear SVM)就是这样的分类器。
2线性支持向量机:可分情况
线性SVM是这样一个分类器,它寻找具有最大边缘的超平面,因此它也经常被称为最大边缘分类器(maximal margin classifier)。
考虑一个包含N个训练样本的二元分类问题。每个样本表示为一个二元组(x,y) (i= 1, 2,N),其中x= (x1, x2.,…, xm)",对应于第i个样本的属性集。为方便计,令y∈{-1,1}表示它的类标号。一个线性分类器的决策边界可以写成如下形式:
W.x+b= 0(5-28)
W和x都是向量
其中,W和b是模型的参数。
图5-23显示了包含圆圈和方块的二维训练集。图中的实线表示决策边界,它将训练样本一分为二,划入各自的类中。任何位于决策边界上的样本都必须满足公式(5-28)。
例如,如果xa和xb是两个位于决策边界上的点,则
W*Xa+b=0
W*Xb+b=0
两个方程相减便得到:
W(xb-xa)= 0
其中,如xb-xa是一个平行于决策边界的向量,它的方向是从xa到xb。由于点积的结果为零,因此w的方向必然垂直于决策边界。
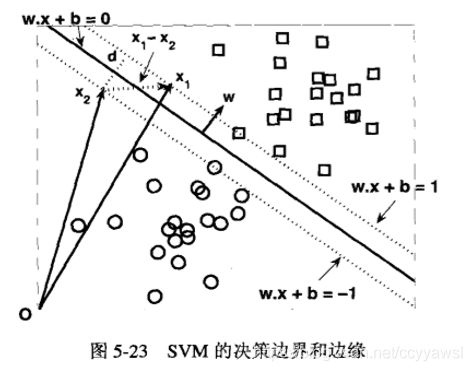
对于任何位于决策边界上方的方块xg,我们可以证明:
w.X+b=k 其中k>0。
同理 下方样本点有
w.X+b=k k<0
所以有

线性分类器的边缘
上方的点w.X+b=k k>0
比如图中离分界线最近的两个点,满足

相减得到
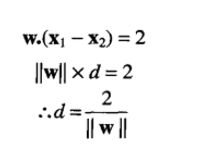
(就是两个样品点方向在w方向(垂直分界线方向)的投影=2)
学习线性SVM模型
SVM的训练阶段包括从训练数据中估计决策边界的参数w和b。选择的参数必须满足下面两个条件:
w.X+ b≥1 如果y= 1
w.X+ b≤-1 如果y=-1
归纳为
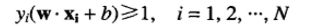
另一个条件—最大化边缘等价于最小化下面的目标函数:
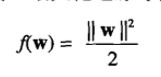
1.线性SVM:可分情况
SVM的学习任务可以形式化地描述为以下被约束的优化问题
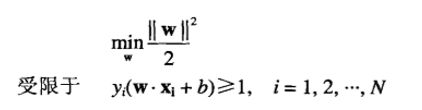
由于目标函数是二次的,而约束在参数w和b上是的线性的,因此这个问题是-一个凸(convex)优化问题,可以通过标准的拉格朗日乘子(Lagrange multiplier) 方法求解。
求偏导

还需要第三个条件求解λ,这个条件是
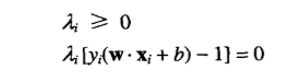
当【】中的式子不为0时λ恒=0
当【】中的式子为0时,即在分界线的两个边界线上时λ>0,这些向量称为支持向量,显然λ的求解只和支持向量有关。
把前两个式子代入第三个式子

这称之为对偶拉格朗日函数。
对偶拉格朗日函数和原拉格朗日函数的主要区别如下:
(1)对偶拉格朗日函数仅涉及拉格朗日乘子和训练数据,而原拉格朗日函数除涉及拉格朗日乘子外还涉及决策边界的参数。尽管如此,这两个优化问题的解是等价的。
(2)公式(5-43)中的二次项前有个负号,这说明原来涉及拉格朗日函数Lp的最小化问题已经变换成了涉及对偶拉格朗日函数Lp的最大化问题。
一旦找到一组λ,就可以通过前面三个等式来求得w和b的可行解。
决策边界可以表示成:
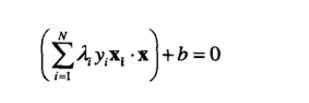
线性支持向量机:不可分情况
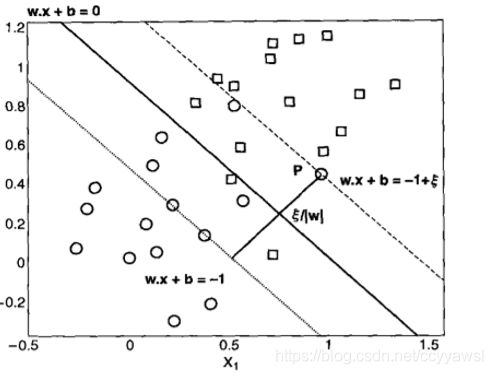
下图给出了一个和图5-22相似的数据集,不同处在于它包含了两个新样本P和Q。尽管决策边界B1误分类了新样本,而B2正确分类了它们,但是这并不表示B2 是一个比 B1好的决策边界,因为这些新样本可能只是训练数据集中的噪声。BI可能仍然比B2更可取,因为它具有较宽的边缘,从而对过分拟合不太敏感。
然而,上一节给出的SVM公式只能构造没有错误的决策边界。这一节考察如何修正公式,利用一种称为软边缘(soft margin)的方法,学习允许一定训
练错误的决策边界。更为重要的是,本节给出的方法允许SVM在一些类线性不可分的情况下构造线性的决策边界。为了做到这一点,SVM学习算法必须考虑边缘的宽度与线性决策边界允许的训练错误数目之间的折中。
决策边界B不再满足之前公式给定的所有约束。因此,必须放松不等式约束,以适应非线性可分数据。可以通过在优化问题的约束中引入正值的松弛变量(slack variable)来实现,如下式所示: .
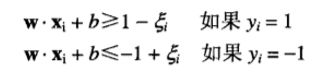

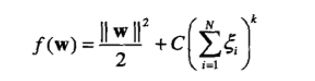
其中C和k是用户指定的参数,表示对误分训练实例的惩罚。为了简化该问题,剩余部分假定k=1。参数C可以根据模型在确认集上的性能选择。

由此,被约束的优化问题的拉格朗日函数可以记作如下形式:

其中,前面两项是需要最小化的目标函数,第三项表示与松弛变量相关的不等式约束,而最后一项是要求ξ的值非负的结果。此外,利用如下的KKT条件,可以将不等式约束变换成等式约束:
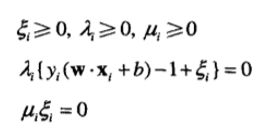
令L关于w, b和ξ的一阶导数为零,就得到如下公式:
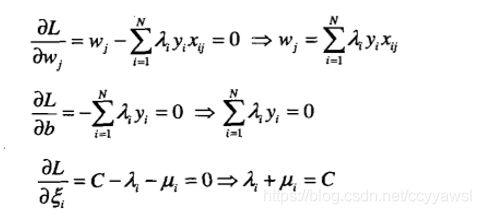
代入拉格朗日函数中,得到如下的对偶拉格朗日函数:
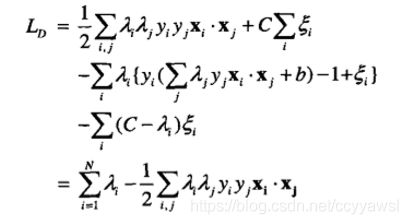
5.1 线性不可分
我们刚刚讨论的硬间隔和软间隔都是在说样本的完全线性可分或者大部分样本点的线性可分。但我们可能会碰到的一种情况是样本点不是线性可分的。
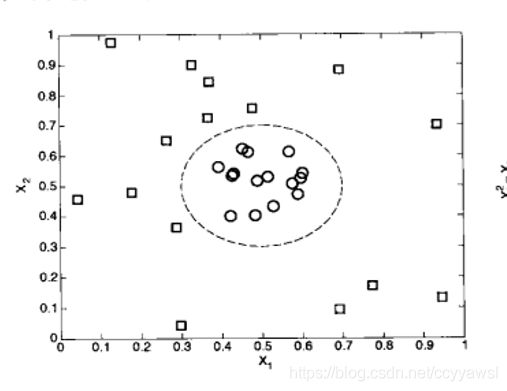
对这种问题,假定存在一个合适的函数中φ(x)来变换给定的数据集。
比如
![]()
变换后,我们需要构建一个线性的决策边界,把样本划分到它们各自所属的类中。在变换后的空间中,线性决策边界具有以下形式: w.φ(x)+b=0。
非线性优化问题就表示为
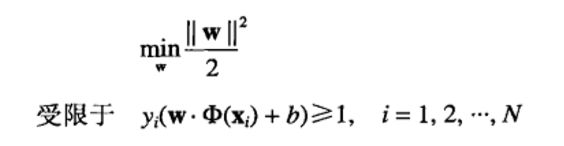
注意,非线性SVM的学习任务和线性SVM (参见定义5.1)很相似。主要的区别在于,学习任务是在变换后的属性中φ(x),而不是在原属性x上执行的。采用5.5.2 节和5.5.3节介绍的线性SVM所使用的方法,可以得到该受约束的优化问题的对偶拉格朗日函数:
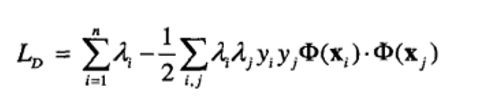
核函数的作用
点积经常用来度量两个输入向量间的相似度。例如,在2.4.5 节介绍的余弦相似度可以定义为规范化后具有单位长度的两个向量间的点积。类似地,点积中φ(x1) φ(x2)可以看作两个实例x1和x2在变换后的空间中的相似性度量。.
核技术是一种使用原属性集计算变换后的空间中的相似度的方法。考虑公式(5-55) 中的映射函数φ。两个输入向量u和v在变换后的空间中的点积可以写成如下形式:
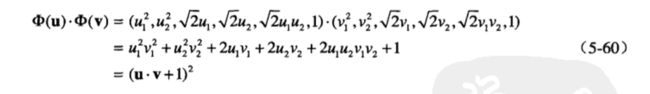
就可以实现以下转化

这个式子只用低维空间的数据即可计算。
这个在原属性空间中计算的相似度函数K称为核函数(kernel function)。核技术有助于处理如何实现非线性SVM的一些问题。
首先,由于在非线性SVM中使用的核函数必须满足一个称为Mercer定理的数学原理,因此我们不需要知道映射函数φ的确切形式。Mercer 原理确保核函数总可以用某高维空间中两个输入向量的点积表示。SVM核的变换后空间也称为再生核希尔伯特空间(Reproducing Kernel Hilbert Space, RKHS)。
其次,相对于使用变换后的属性集中(x),使用核函数计算点积的开销更小。
第三,既然计算在原空间中进行,维灾难问题就可以避免。
5.3 常见核函数
我们常用核函数有:
线性核函数
![]()
多项式核函数

高斯核函数

这三个常用的核函数中只有高斯核函数是需要调参的。
5.5.5
支持向量机的特征,
SVM具有许多很好的性质,因此它已经成为广泛使用的分类算法之- -。下面简要总结一下
SVM的一般特征。
(1) SVM学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他的分类方法(如基于规则的分类器和人工神经网络)都采用一种基于贪心学习的策略来搜索假设空间,这种方法- -般只能获得局部最优解。
(2) SVM通过最大化决策边界的边缘来控制模型的能力。尽管如此,用户必须提供其他参数,如使用的核函数类型、为了引入松弛变量所需的代价函数C等。
(3)通过对数据中每个分类属性值引入-一个哑变量,SVM可以应用于分类数据。例如,如果婚姻状况有三个值{单身,已婚,离异},可以对每一一个属性值引入一个二元变量。
(4)本节所给出的SVM公式表述是针对二类问题的。5.8 节将给出把SVM扩展到多类问题的一些方法。