深度学习与Pytorch入门笔记
一、基本操作
pythonPytorch中文文档
https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch-optim/
一、Anaconda基本操作
1、用conda创建Python虚拟环境(在conda prompt环境下完成)
conda create -n environment_name python=X.X
2、激活虚拟环境(在conda prompt环境下完成)
activate your_env_name(虚拟环境名称)
3、给虚拟环境安装外部包
conda install -n your_env_name [package]
4、查看已有的环境(当前已激活的环境会显示一个星号)
conda info -e
5、删除一个已有的虚拟环境
conda remove --name your_env_name --all
6、进入虚拟环境
conda activate your_env_name(虚拟环境名称)
二、Tensor和Numpy
tensor可以轻易地进行卷积,激活,上下采样,微分求导等操作,而numpy数组就不行
三、反向传播法
https://blog.csdn.net/shijing_0214/article/details/51923547?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-4.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-4.control
四、Pytorch特性自动梯度模块Autograd
1.核心数据结构Variable
variable封装了三个数据:
data(保存variable所包含的tensor),
grad(保存data对应的梯度,grad也是variable而不是tensor,与data形状一致),在Variable变量创建的过程中通过requires_grad的值,程序来选择是否要在计算的过程中跟踪该值
grad_fn(指向一个function,记录tensor的操作历史,即该tensor是什么操作的输出,用于构建计算图,如某tensor是由a+b得到,其grad_fn的值即为AddBackward。如果某一个Variable变量是由用户创建,即他为叶子结点,对应的grad_fn为None)
如建立一个Variable变量a —— a = V(t.ones(3, 4), requires_grad =True)
调用a.sum()与a.data.sum()结果不同,前者计算sum后结果仍为Variable,后者取data后计算sum结果变为tensor
2.计算图
五、神经网络工具箱nn
#### tip:python中的self
- self只必须存在于类的函数中,普通函数是不需要带self的,在调用时,不需要为self参数赋值。Self代表的是类的实例对象(注意不是类本身),self可以用其他名称来代替,但是约定最好是self
- self的原理
创建一个类Test(),实例化该类t=Test()得到t这个对象,调用这个对象的方法t.fun(x,y),调用过程中,python会自动转为Test.fun(t,x,y)
1.nn.Module
autograd作为自动微分系统对于实际的深度学习项目过于底层,在实际使用中,我们可以使用nn工具箱模块。torch.nn的核心数据结构是Module。在使用中,最常见是继承nn.Module从而撰写自己的网络层。
1)全连接层Linear
以下为使用nn工具箱中的现有模型
in_features指的是输入的二维张量的大小,即输入的[batch_size, size]中的size。
out_features指的是输出的二维张量的大小,即输出的二维张量的形状为[batch_size,output_size],当然,它也代表了该全连接层的神经元个数。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e2Ox8dFP-1620980777610)(C:\Users\15729\AppData\Roaming\Typora\typora-user-images\image-20210313145041022.png)]
以下为使用nn.Module实现自己的全连接层(全连接层,即输出y和输入x满足y=wx+b,w和b是可学习的参数)
import torch as t
from torch import nn
from torch.autograd import Variable
class Linear(nn.Module): # 继承nn.Module
def __init__(self, in_features, out_features):
super(Linear, self).__init__() # 等价于nn.Module.__init__(self)
self.w = nn.Parameter(t.randn(in_features, out_features))
self.b = nn.Parameter(t.randn(out_features))
def forward(self, x):
x = x.mm(self.w)
return x + self.b.expand_as(x)
layer = Linear(4, 3)
input = Variable(t.randn(2, 4))
output = layer(input) #等价于layer.forward(input)
print(input)
print(output)
注意
- 自定义层
Linear必须继承nn.Module,并且在其构造函数中需调用nn.Module的构造函数 - 在构造函数init中必须自己定义可学习的参数,并封装成
Parameter,在本例中我们把w和b封装成Parameter。Parameter是一种特殊的Variable,但其默认需要求导(requires_grad=True) forward函数实现的是前向传播过程,其输入可以是一个或多个variable,对x的任何操作也必须是variable支持的操作- 无须写反向传播函数,因其前向传播都是对variable进行操作,nn.Module能够利用autograd自动实现反向传播,这一点比Function简单许多
- 使用时,直观上可将layer看成数学概念中的函数,调用layer(input)即可得到input对应的结果。它等价于
layers.__call__(input),在call函数中,主要调用的是layer.forward(x)。在实际使用中应尽量使用layer(x)而不是使用layer.forward(x)
2)多层感知机
激活函数
激活函数简而言之,即引入非线性,解决线性函数,单层的感知机不能解决的分类问题
如果不用激活函数,在这种情况下每一层输出都是上层输入的线性函数。容易验证,无论神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。因此引入非线性函数作为激活函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入。
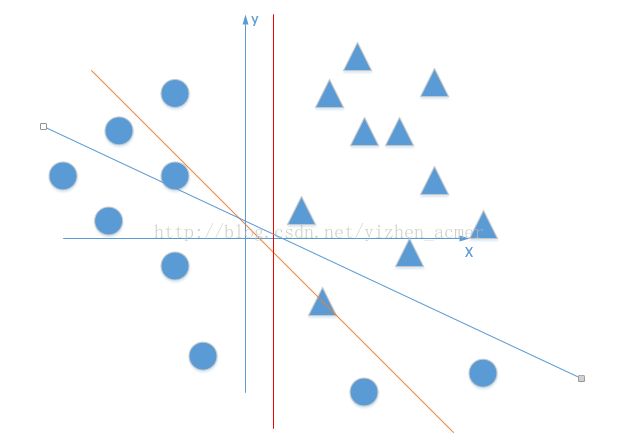
https://blog.csdn.net/qq_30815237/article/details/86700680
在已有上文Linear的情况下,我们可以添加多层,实现多层感知机,代码如下:
class Perceptron(nn.Module):
def __init__(self, in_features, hidden_features, out_features):
nn.Module.__init__(self)
self.layer1 = Linear(in_features, hidden_features)
self.layer2 = Linear(hidden_features, out_features)
def forward(self, x):
x = self.layer1(x)
x = t.sigmoid(x)
return self.layer2(x)
perceptron = Perceptron(3, 4, 1)
for name, param in perceptron.named_parameters():
print(name, param.size())
注意
- 构造函数init中,可利用前面自定义的Linear层(module)作为当前module对象的一个子module,它的可学习参数,也会成为当前module的可学习参数
- 在前向传播函数中,我们有意识地将输出变量都命名为x,是为了能让python回收一些中间层的输出,从而节省内存
module中parameter的全局命名规范如下:
- Parameter直接命名。例如self.param_name=nn.Parameter(t.randn(3,4)),命名为param_name
- 子module中的parameter,
会在其名字之前加上当前module的名字。例如self.sub_module=SubModel(),SubModel中有个parameter的名字也叫做param_name,那么二者拼接而成的parameter name就是sub_module.param_name
2.常用的神经网络层
3.优化器
PyTorch将深度学习中常用的优化方法全部封装在torch.optim中
所有的优化方法都是继承基类optim.Optimizer,并实现了自己的优化步骤。下面就以最基本的优化方法–随机梯度下降法(SGD)举例说明。这里需要重点掌握:
- 优化方法的基本使用方法
- 如何对模型的不同部分设置不同的学习率
- 如何调整学习率
optimizer的使用
为了使用torch.optim,你需要构建一个optimizer对象。这个对象能够保持当前参数状态并基于计算得到的梯度进行参数更新。
构建
了构建一个Optimizer,你需要给它一个包含了需要优化的参数(必须都是Variable对象)的iterable。然后,你可以设置optimizer的参 数选项,比如学习率,权重衰减,等等
优化方法列举:https://blog.csdn.net/q295684174/article/details/79130666
//选用不同的优化方法,优化规则不同,有SGD,Adam等
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr = 0.0001)
为每个参数单独设置选项
若想这么做,不要直接传入Variable的iterable,而是传入dict的iterable。每一个dict都分别定 义了一组参数,并且包含一个param键,这个键对应参数的列表。其他的键应该optimizer所接受的其他参数的关键字相匹配,并且会被用于对这组参数的 优化。
例如,当我们想指定每一层的学习率时,这是非常有用的:
optim.SGD([
{
'params': model.base.parameters()},
{
'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)
这意味着model.base的参数将会使用1e-2的学习率,model.classifier的参数将会使用1e-3的学习率,并且0.9的momentum将会被用于所 有的参数。
执行优化
所有的optimizer都实现了step()方法,这个方法会更新所有的参数。它能按两种方式来使用:
optimizer.step()
这是大多数optimizer所支持的简化版本。一旦梯度被如backward()之类的函数计算好后,我们就可以调用这个函数。
optimizer.step(closure)
一些优化算法例如Conjugate Gradient和LBFGS需要重复多次计算函数,因此你需要传入一个闭包去允许它们重新计算你的模型。这个闭包应当清空梯度, 计算损失,然后返回。
调整学习率
调整学习率主要有两种做法。一种是修改optimizer.param_group中对应的学习率,另一种是新建优化器(更简单也是更推荐的做法),由于optimizer十分轻量级,构建开销很小,故可以构建新的optimizer。但是新建优化器会重新初始化动量等状态信息,这对使用动量的优化器来说(如带momentum的sgd),可能会造成损失函数在收敛过程中出现震荡
# 调整学习率,新建一个optimizer
old_lr=0.1
optimizer=optim.SGD([
{
'params':net.features.parameters()},
{
'params':net.classifier.parameters(),'lr':old_lr*0.1}
],lr=1e-5)
4.nn.functional
nn中的大部分layer在functional中都有一个与之对应的函数。
nn.functional与nn.Module的主要区别在于:
用Moudule实现的layers是一个特殊的类,会自动提取科学系的参数
functional中的函数更像是纯函数,由def function(input)定义
当模型有可学习的参数时,最好使用nn.Module,否则可以使用nn.functional
5.保存数据
全部保留
torch.save(net1 ,‘net.pth’)
参数保留
torch.save(net1.state_dict(), ‘net_params.pth’ )
加载已经保存的模型
net = Net()
net.load_state_dict(t.load(‘net.pth’))
六、Pytorch中常用的工具
1.数据处理
(1)数据加载,Dataset
pytorch中,数据的加载可通过自定义的数据集对象实现。数据集对象被抽象为Dataset类,我们用这个类来处理自己的数据集的时候必须继承Dataset类(在torch.utils.data包中,通过data.Dataset调用),并实现他的两个魔术方法。
-
__ getitem__(index):
返回一个样本数据,当使用obj[index]时实际就是在调用obj.__ getitem__(index)
-
__ len__():
返回样本的数量,当使用len(obj)时实际就是在调用obj.__ len__()
例如:
class dogCat(data.Dataset):
def __init__(self,root): # root为数据存放目录
imgs = os.listdir(root) #列出当前路径下所有的文件
self.imgs = [os.path.join(root,img) for img in imgs] # 所有图片的路径
#print(self.imgs)
"""返回一个样本数据"""
def __getitem__(self, item):
img_path = self.imgs[item] # 第item张图片的路径
#dog 1 cat 0
label = 1 if 'dog' in img_path.split('\\')[-1] else 0 # 获取标签信息
#print(label)
pil_img = Image.open(img_path) #读入图片
print(type(pil_img))
array = np.asarray(pil_img) # 转为numpy.array类型
data = t.from_numpy(array) # 转为tensor类型
return data,label #返回图片对应的tensor及其标签
"""样本的数量"""
def __len__(self):
return len(self.imgs)
(2)dataloader
虽然在封装了Dataset类之后我们能够完成对数据的记载,但是在实际训练过程中我们还需要更多的步骤:
- 一次加载batch size大小的数据。
- 打乱数据的顺序。
- 多线程加载数据。
而这些需求已经全部被DataLoader类所实现
https://www.cnblogs.com/ranjiewen/articles/10128046.html
pytorch 的数据加载到模型的操作顺序是这样的:
① 创建一个 Dataset 对象
② 创建一个 DataLoader 对象
③ 循环这个 DataLoader 对象,将img, label加载到模型中进行训练
DataLoader接口的目的:将自定义的Dataset根据batch size大小、是否shuffle等封装成一个Batch Size大小的Tensor,用于后面的训练。
以下为DataLoader(object)的参数:
- dataset(Dataset): 传入的数据集
- batch_size(int, optional): 每个batch有多少个样本
- shuffle(bool, optional): 在每个epoch开始的时候,是否对数据进行重新排序
- num_workers (int, optional): 这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认为0)
(3)计算机视觉工具包:torchvision
对于图像数据来说,以上的数据加载时不完善的,因为只是将图片读入,而没有进行相关的处理,如每张图片的大小和形状,样本的数值归一化等等。
为了解决这一问题,PyTorch开发了一个视觉工具包torchvision,这个包独立于torch,需要通过pip install torchvision来单独安装。
torchvision有三个部分组成:
- models:提供各种经典的网络结构和预训练好的模型,如AlexNet、VGG、ResNet、Inception等。
from torchvision import models
from torch import nn
resnet34 = models.resnet34(pretrained=True,num_classes=1000) # 加载预训练模型
resnet34.fc=nn.Linear(512,10) # 修改全连接层为10分类
- datasets:提供了常用的数据集,如MNIST、CIFAR10/100、ImageNet、COCO等。
from torchvision import datasets
dataset = datasets.MNIST('data/',download=True,train=False,transform=transform)
- transforms: 提供常用的数据预处理操作,主要是对
Tensor和PIL Image对象的处理操作。
对PIL Image的操作:
Scale:调整图片尺寸,长宽比保持不变
CenterCrop、RandomCrop、RandomsizedCrop:裁剪图片
Pad:填充图片
ToTensor:将PIL Image转化为Tensor,会自动将[0,255]归一化至[0,1]
对Tensor的操作:Normalize、ToPILImage等。
Normalize:标准化,即减均值,除以标准差
ToPILImage:将Tensor转为PIL Image对象
import os
from torch.utils import data
from PIL import Image
import numpy as np
from torchvision import transforms as T
transform = T.Compose([T.Resize(224),T.CenterCrop(224),T.ToTensor(),T.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])]) # 构建转换操作
class dogCat(data.Dataset):
def __init__(self,root,transforms):
imgs = os.listdir(root)
#print(imgs)
self.imgs = [os.path.join(root,img) for img in imgs]
#print(self.imgs)
self.transforms = transforms
def __getitem__(self, item):
img_path = self.imgs[item]
#dog 1 cat 0
label = 1 if 'dog' in img_path.split('\\')[-1] else 0
#print(label)
pil_img = Image.open(img_path)
if self.transforms:
pil_img = self.transforms(pil_img) #执行准换操作
return pil_img,label,item
def __len__(self):
return len(self.imgs)
七、实战开发
深度学习的研究,程序一般都需要实现以下几个方面:
① 模型定义
② 数据处理和加载
③ 训练模型
④ 训练过程的可视化
⑤ 测试
最为普遍的神经网络训练可以简单概括为以下三步:
① 将训练数据输入模型开始前向传播。
② 通过损失函数计算模型输出和标准答案之间的差距,得到loss值。
③ 根据loss值反向传播,使用优化器更新模型参数。
pytorch具体的训练步骤非常简单:
① 数据输入模型得到输出。
② 根据输出和标签计算loss。
③ optimizer.zero_grad () 优化器梯度归零。
④ loss.backward () loss反向传播。
⑤ optimizer.step () 优化器更新参数。
根据以上步骤,我们完成了下面的训练和验证模块:
def train(model, loss_fn, optimizer, dataloader, num_epochs = 1):
for epoch in range(num_epochs):
print('Starting epoch %d / %d' % (epoch + 1, num_epochs))
# 在验证集上验证模型效果
check_accuracy(fixed_model, image_dataloader_val)
model.train() # 模型的.train()方法让模型进入训练模式,参数保留梯度,dropout层等部分正常工作。
for t, sample in enumerate(dataloader):
x_var = Variable(sample['image']) # 取得一个batch的图像数据。
y_var = Variable(sample['Label'].long()) # 取得对应的标签。
scores = model(x_var) # 得到输出。
loss = loss_fn(scores, y_var) # 计算loss。
if (t + 1) % print_every == 0: # 每隔一段时间打印一次loss。
print('t = %d, loss = %.4f' % (t + 1, loss.item()))
# 三步更新参数。
optimizer.zero_grad()
loss.backward()
optimizer.step()
def check_accuracy(model, loader):
num_correct = 0
num_samples = 0
model.eval() # 模型的.eval()方法切换进入评测模式,对应的dropout等部分将停止工作。
for t, sample in enumerate(loader):
x_var = Variable(sample['image'])
y_var = sample['Label']
scores = model(x_var)
_, preds = scores.data.max(1) # 找到可能最高的标签作为输出。
num_correct += (preds.numpy() == y_var.numpy()).sum()
num_samples += preds.size(0)
acc = float(num_correct) / num_samples
print('Got %d / %d correct (%.2f)' % (num_correct, num_samples, 100 * acc))
二、神经网络基本组成

卷积层
CNN的卷积核通道数 = 卷积输入层的通道数
CNN的卷积输出层通道数(深度)= 卷积核的个数(数量任意)
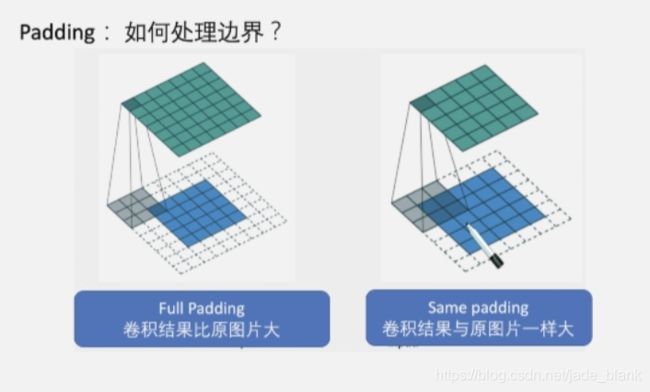
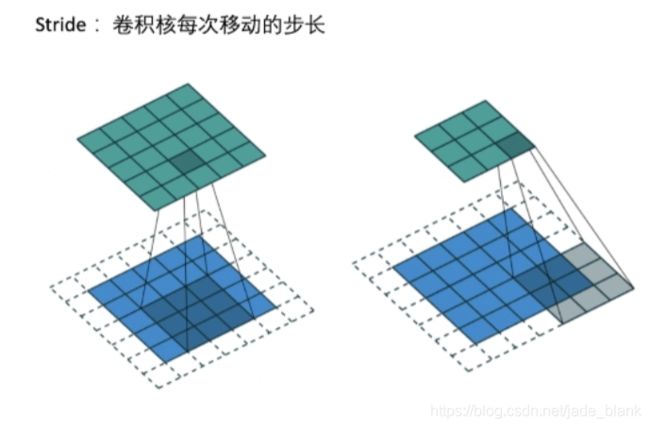
巻积层和池化层的输出维度计算公式为N=(W-F+2P)/S+1,
其中F为巻积核大小,P为图像四周的padding大小,S为步长
如:一个8×8的原始图片,经过3×3卷积核默认卷积操作,得到6×6的图片
conv2d参数如下:
torch.nn.Conv2d(in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
在卷积层的计算中,假设输入是H x W x C, C是输入的深度(即通道数),那么卷积核(滤波器)的通道数需要和输入的通道数相同,所以也为C,假设卷积核的大小为K x K,一个卷积核就为K x K x C,计算时卷积核的对应通道应用于输入的对应通道,这样一个卷积核应用于输入就得到输出的一个通道。假设有P个K x K x C的卷积核,这样每个卷积核应用于输入都会得到一个通道,所以输出有P个通道。

Padding
Stride
最大池化层 maxpool

下面是PyTorch对于池化层的实现。
>>> import torch
>>> from torch import nn
# 池化主要需要两个参数,第一个参数代表池化区域大小,第二个参数表示步长
>>> max_pooling = nn.MaxPool2d(2, stride=2)
>>> aver_pooling = nn.AvgPool2d(2, stride=2)
>>> input = torch.randn(1,1,4,4)
>>> input tensor(
[[[[ 1.4873, -0.2228, -0.3972, -0.1336],
[ 0.6129, 0.4522, -0.3175, -1.2225],
[-1.0811, 2.3458, -0.4562, -1.9391],
[-0.3609, -2.0500, -1.2374, -0.2012]]]])
# 调用最大值池化与平均值池化,可以看到size从[1, 1, 4, 4]变为了[1, 1, 2, 2]
>>> max_pooling(input)
tensor([[[[ 1.4873, -0.1336],
[ 2.3458, -0.2012]]]])
>>> aver_pooling(input)
tensor([[[[ 0.5824, -0.5177],
[-0.2866, -0.9585]]]])
Flatten层
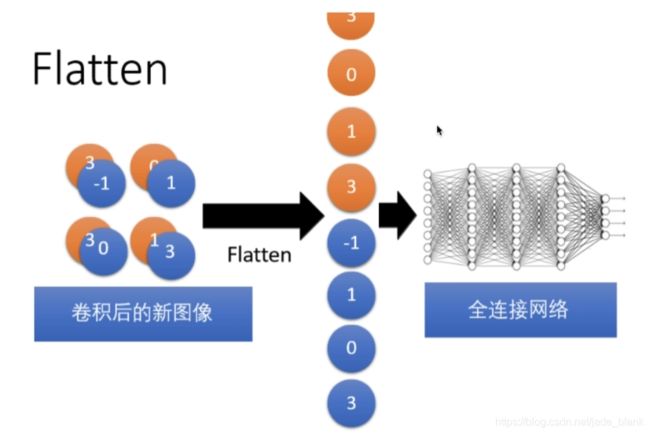
Dropout层
在深度学习中,当参数过多而训练样本又比较少时,模型容易产生过拟合现象。过拟合具体表现为在训练集上预测准确率高,而在测试集上准确率大幅下降。
Dropout的基本思想如图所示,在训练时,每个神经元以概率p保留,即以1-p的概率停止工作,每次前向传播保留下来的神经元都不 同,这样可以使得模型不太依赖于某些局部特征,泛化性能更强。在测 试时,为了保证相同的输出期望值,每个参数还要乘以p。当然还有另 外一种计算方式称为Inverted Dropout,即在训练时将保留下的神经元乘 以1/p,这样测试时就不需要再改变权重。

在PyTorch中使用Dropout的示例如下:
>>> import torch >>> from torch
import nn
# PyTorch将元素置0来实现Dropout层,第一个参数为置0概率,第二个为是否原地操作
>>> dropout = nn.Dropout(0.5, inplace=False)
>>> input = torch.randn(2, 64, 7, 7)
>>> output = dropout(input)
全连接层的作用
https://www.zhihu.com/question/41037974
全连接层的作用主要就是实现分类(Classification)
从下图,我们可以看出
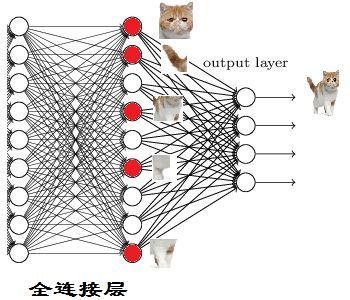
红色的神经元表示这个特征被找到了(激活了)
同一层的其他神经元,要么猫的特征不明显,要么没找到
当我们把这些找到的特征组合在一起,发现最符合要求的是猫
PyTorch使用全连接层需要指定输入的与输出的维度。示例如下:
>>> import torch
>>> from torch import nn
# 第一维表示一共有4个样本
>>> input = torch.randn(4, 1024)
>>> linear = nn.Linear(1024, 4096)
>>> output = linear(input)
>>> input.shape
torch.Size([4, 1024])
>>> output.shape
torch.Size([4, 4096])
tip:鲁棒性
计算机软件在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃,就是该软件的鲁棒性。
感受野
感受野就是,卷积神经网络中每层的**特征图(Feature Map)**上的像素点在原始图像中映射的区域大小,也就相当于高层的特征图中的像素点受原图多大区域的影响。

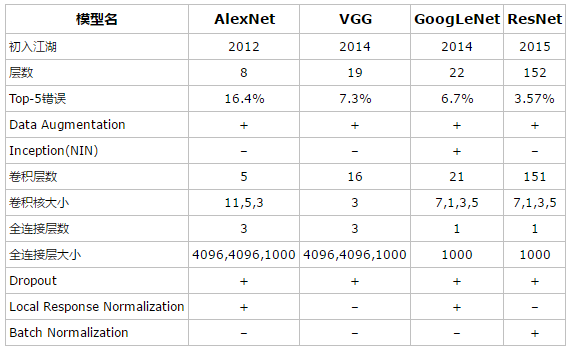
各种经典网络模型
在CNN网络结构的进化过程中,出现过许多优秀的CNN网络,如:LeNet,AlexNet,VGG-Net,GoogLeNet,ResNet,DesNet.
https://blog.csdn.net/u013989576/article/details/71600795
三、物体检测框架
https://blog.csdn.net/fu_shuwu/article/details/84195998
1.两阶经典检测器:Faster RCNN
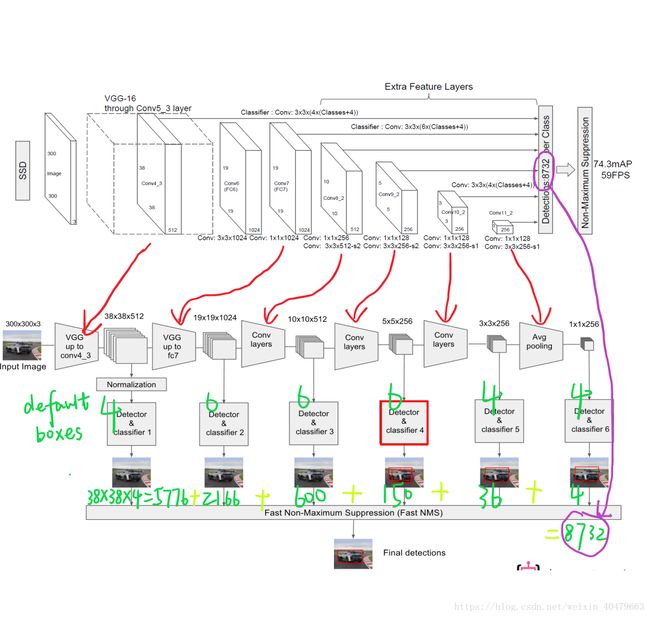
2.单阶多层检测器:SSD
https://blog.csdn.net/weixin_40479663/article/details/82953959